2023.07.05 - [ML(머신러닝)/Time Series] - Transformer 기반 Time Series Forecast 논문 알아보기
2023.07.06 - [ML(머신러닝)/Time Series] - TimeSeries Forecast) Transformer보다 좋다는 LSTF-Linear 알아보기
2023.07.12 - [ML(머신러닝)/Time Series] - TimeSeries) PatchTST 논문과 코드 살펴보기
2023.10.13 - [분류 전체보기] - TimeSeries) TSMixer 논문 및 구현 살펴보기
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. ICLR2023
해당 논문은 Are Transformers Effective for Time Series Forecasting? 이후에 나온 논문으로 알고 있고, Transformer가 좋다고 주장하는 논문입니다.
논문의 개요는 다음과 같습니다.
개요
저자는 다변량 시계열 예측과 자기 지도 학습(self supervised representation learning)을 위한 Transformer 기반 모델의 효율적인 설계를 제안합니다.
이는 두 가지 주요 구성 요소에 기반합니다:
(i) 시계열을 하위 시계열 패치로 분할(segmentation)하여 Transformer의 입력 토큰으로 사용하는 것
(ii) 채널 독립성(channel-independence), 즉 각 채널이 동일한 임베딩과 Transformer 가중치를 공유하는 단일 단변량 시계열을 포함한다는 점
패치 설계(Patching design)는 세 가지 이점을 갖습니다:
1. 임베딩에서 지역 의미 정보(local semantic information)가 유지되며, 동일한 이전 창을 가지더라도 어텐션 맵의 계산과 메모리 사용량이 제곱적으로 감소하며, 모델은 더 긴 과거에 대해 주의를 기울일 수 있습니다.
2. channel-independent patch time series Transformer (PatchTST)는 최신 Transformer 기반 모델과 비교했을 때 장기 예측 정확도를 크게 향상할 수 있습니다.
3. 저자의 모델을 자기 지도 사전 학습(self supervised representation learning) 작업에 적용하여 탁월한 성능을 보이며, 대규모 데이터셋에 대한 지도 학습을 능가합니다. 마스크 된 사전 학습 표현을 한 데이터셋에서 다른 데이터셋으로 전이하는 것도 최첨단 예측 정확도를 얻을 수 있습니다.
즉, 저자는 다변량 시계열 예측과 자기 지도 학습을 위한 효율적인 Transformer 기반 모델인 PatchTST를 제안합니다.
이 모델은 시계열을 하위 시계열 패치로 분할하고 채널 독립성을 가집니다. PatchTST는 최신 Transformer 모델보다 더 나은 장기 예측 정확도를 제공하며, 자기 지도 사전 학습과 전이 학습에도 탁월한 성능을 보인다고 합니다.
핵심 키워드는 #patch #channel independence #self supervised representation learning 으로 보입니다.
처음에 다른 논문과 비슷하게 Transformer가 좋아지고, 시계열 예측이 중요하다로 시작하고 저자가 주장하는 디자인은 다음과 같다고 합니다.
Patching.
시계열 예측은 각 다른 시간 단계의 데이터 사이의 상관 관계를 이해하는 것을 목표로 합니다. 그러나 단일 시간 단계는 문장의 단어와 같이 의미를 갖지 않으므로, 연결을 분석하는 데 있어서 지역적인 의미 정보를 추출하는 것이 중요합니다. 이전 연구들은 대부분 점별 입력 토큰(point-wise input tokens)을 사용하거나 수작업으로 만든 정보 시리즈만 사용합니다. 그에 반해, 저자는 시간 단계를 하위 시계열 패치로 집계함으로써 점별 수준에서 사용할 수 없는 포괄적인 의미 정보를 포착하고 지역성을 강화합니다.
즉, 기존 방시에서는 점별 토큰 방식에서 지역 정보의 손실이 있어서 데이터를 잘라서 하나의 토큰으로 만들어서 넣으면, 부분적으로 정보를 추출할 수 있다고 하는 겁니다.
Channel-independence. 다변량 시계열은 다중 채널 신호이며, 각 Transformer 입력 토큰은 단일 채널 또는 다중 채널의 데이터로 표현될 수 있습니다. 입력 토큰의 설계에 따라 다양한 변형의 Transformer 아키텍처가 제안되었습니다. 채널 혼합(Channel-mixing)은 입력 토큰이 모든 시계열 특징의 벡터를 사용하여 정보를 혼합하기 위해 임베딩 공간에 투영되는 경우를 의미합니다. 반면, 채널 독립성(Channel-independence)은 각 입력 토큰이 단일 채널에서만 정보를 포함한다는 것을 의미합니다. 이는 CNN (Zheng et al., 2014) 및 선형 모델 (Zeng et al., 2022)에서 잘 작동함이 입증되었으나, 아직 Transformer 기반 모델에는 적용되지 않았습니다.
기존 방식은 결국 채널별로 값이 섞이는 방식이었지만, 저자들이 새롭게 주장하는 방법은 채널별로 각기 다르게 처리해서, 섞이지 않게 하는 것을 반영했다는 것 같습니다.
기여한 점
저자의 모델은 시간 및 공간 복잡도를 줄이고, 더 긴 과거 정보를 학습하며, 표현 학습 능력을 갖고 있습니다.
패칭을 통해 시간 및 공간 복잡도를 감소시키고 지역적인 의미 정보를 포착하며, 채널 독립성을 통해 다중 채널 시계열 데이터를 처리합니다. 이로 인해 더 나은 예측 성능을 달성할 수 있습니다. 저희는 실험 결과를 통해 이러한 이점을 확증합니다.
1. 시간 복잡도 감소 - Patch를 통해 개선
2. 더 긴 과거 정보 학습 - Patch로 그룹화하여 token을 줄이면서 길게 사용할 수 있음.
3. 표현 학습 능력 - 기존 Transformer처럼 MLM 방식으로 학습할 수 있음. (mask patch를 복원하기)
표 1을 통해 확인한 점이라고 주장하는 부분
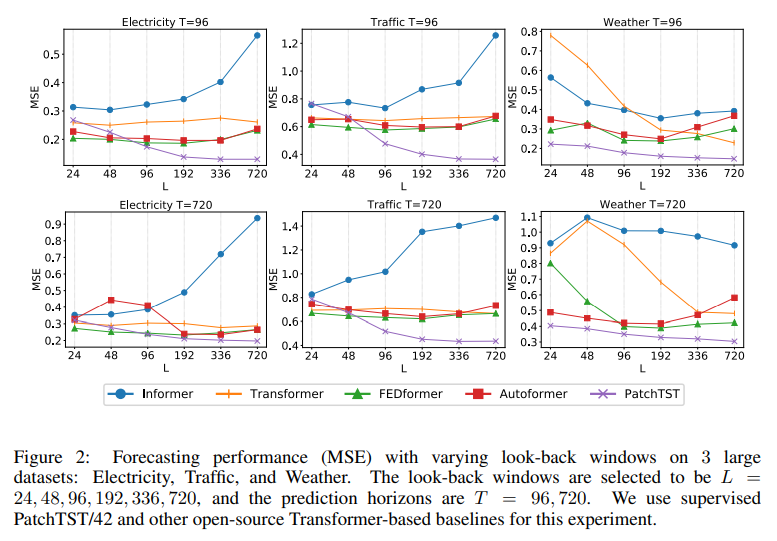
1. N ≈ L/S, 따라서 복잡성을 이차적으로 감소시킬 수 있습니다. Table 1은 패치(patching)의 유용성을 보여줍니다. P = 16, S = 8, L = 336로 설정하여 대규모 데이터셋에서 학습 시간이 22배 정도 줄어드는 것을 확인할 수 있습니다.
2. Table 1에서도 확인할 수 있듯이, 패치(patching)를 사용하면 L = 336일 때 MSE 점수가 0.397에서 0.367로 더욱 감소합니다.
3. 선형 모델(Zeng et al., 2022)과 같은 단순한 모델은 제한된 표현 능력 때문에 이러한 작업에는 선호되지 않을 수 있습니다. PatchTST 모델을 통해 저자는 Transformer가 실제로 시계열 예측에 효과적임을 확인할 뿐만 아니라, 예측 성능을 더욱 향상할 수 있는 표현 능력을 보여줄 수 있습니다.

관련 작업들
시계열 분야의 Transformer
Transformer 기반 모델 아키텍처는 다양하게 attention을 바꿔가면서 진행함.
1. LogTrans
2. Informer
3. Autoformer
4. FEDformer
저자의 주장으로는 다른 모델들은 포인트 단위의 어텐션을 사용하여 패치의 중요성을 무시합니다.
LogTrans(Li et al., 2019)는 키와 쿼리 간의 포인트 단위의 내적을 피하지만, 여전히 값은 단일 시간 단계를 기반으로 합니다.
Autoformer(Wu et al., 2021)는 패치 수준의 연결을 얻기 위해 자기상관을 사용하지만, 이는 모든 패치 내의 의미 정보를 포함하지 않는 수작업 디자인입니다.
Triformer(Cirstea et al., 2022)는 패치 내에서 의사 타임스탬프를 쿼리로 사용하여 복잡성을 줄이기 위해 패치 어텐션을 제안하지만, 이는 패치를 입력 단위로 처리하지 않으며 그 뒤에 있는 의미적 중요성을 드러내지 않습니다.
시계열 분야의 표현 학습
Transformer 기반이 아닌 다양한 모델이 제안되었습니다(Franceschi et al., 2019; Tonekaboni et al., 2021; Yang & Hong, 2022; Yue et al., 2022). 한편, Transformer는 기반 모델(Bommasani et al., 2021) 및 범용적인 표현 학습을 위한 이상적인 후보로 알려져 있습니다. 그러나 시계열 Transformer(TST)(Zerveas et al., 2021)와 TS-TCC(Eldele et al., 2021)와 같은 Transformer 기반 모델에 대한 시도는 아직 완전히 이루어지지 않았습니다.
모델 구조
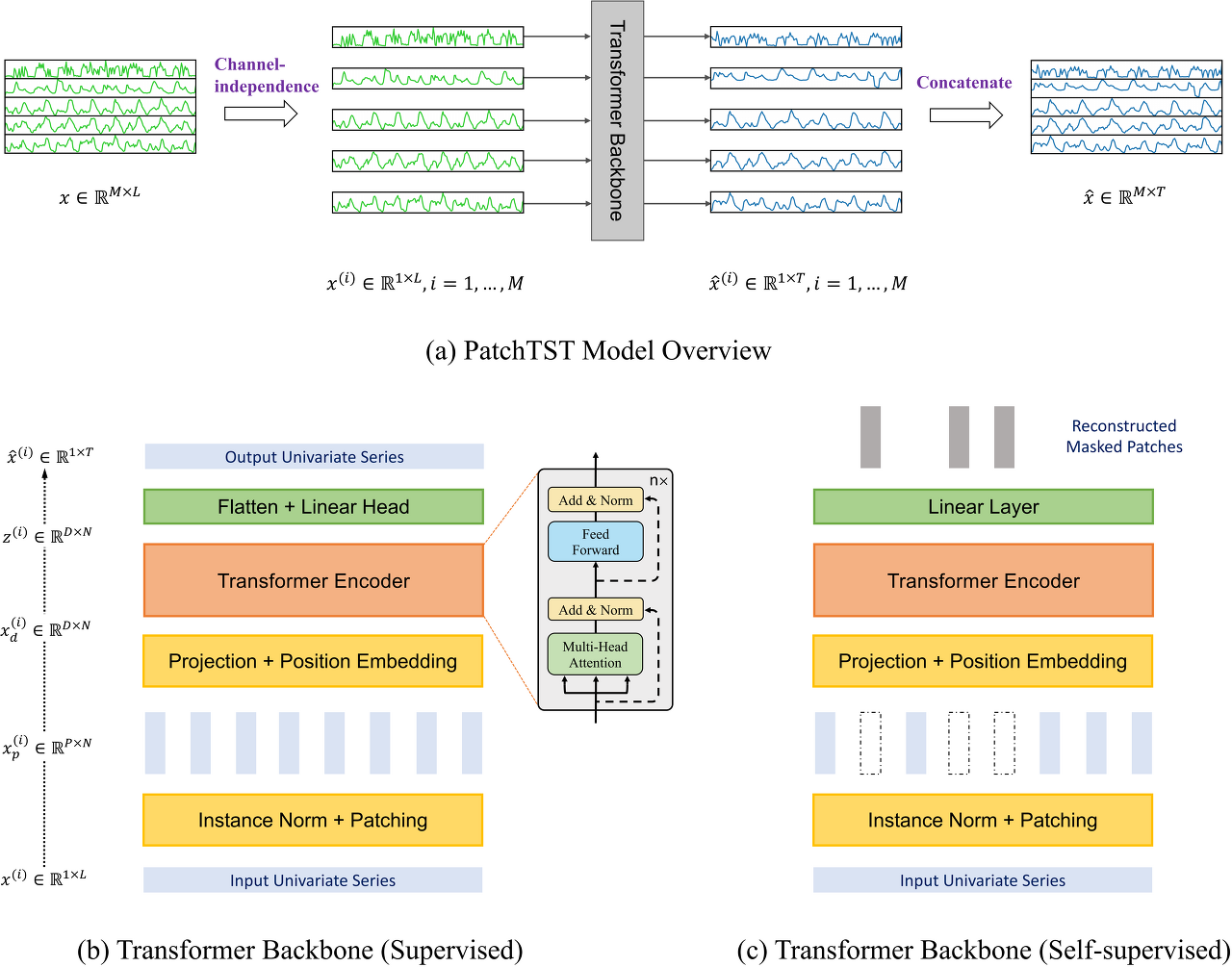
문제 정의
x(1)~x(L)의 데이터를 가지고 x(L+1) ~ x(L+T) 을 예측하는 것으로 볼 수 있습니다.
여기서는 Transformer에서 Encoder 를 핵심 아키텍처로 사용한다고 합니다.
Forward Pass
저자는 시간 인덱스 1에서 시작하는 길이 L인 i번째 단변량 시리즈를 x(i)1:L = (x(i)1, ..., x(i)L)로 표기합니다
(여기서 i = 1, ..., M). 입력 (x1, ..., xL)은 M개의 단변량 시리즈 x(i) ∈ R1×L로 분할되며, 각각의 시리즈는 채널 독립성 설정에 따라 독립적으로 Transformer 백본에 입력됩니다.
그런 다음 Transformer 백본은 해당되는 예측 결과 xˆ(i) = (ˆx(i)L+1, ..., xˆ(i)L+T) ∈ R1×T을 제공합니다.
즉 채널마다 독립적으로 예측한다고 볼 수 있습니다.
Patch
각각의 입력 단변량 시계열 x(i)는 먼저 중첩되거나 중첩되지 않을 수 있는 패치로 나눠집니다. 패치 길이를 P로, 두 개의 연속 패치 사이의 비중첩 영역인 스트라이드를 S로 나타내면, 패치 과정은 P × N의 패치 시퀀스 x(i)p ∈ R P×N을 생성합니다. 여기서 N은 패치의 수이며, N = [(L−P)/S] + 2입니다. 여기서 S는 패치 간 겹침의 횟수이며, S개의 반복된 마지막 값 x(i)L ∈ R을 원래 시퀀스의 끝에 패딩합니다.
패치의 사용으로 인해 입력 토큰의 수는 L에서 대략 L/S로 줄어듭니다. 이는 어텐션 맵의 메모리 사용량과 계산 복잡성이 S의 배수로 이차적으로 감소함을 의미합니다. 따라서 훈련 시간과 GPU 메모리에 제한을 받는다면, 패치 디자인을 통해 모델이 더 긴 과거 시퀀스를 볼 수 있으며, 이는 Table 1에서 확인할 수 있듯이 예측 성능을 크게 향상시킬 수 있습니다.

위에 있는 에시로 보면 다음과 같다
점의 개수 L = 15 / S = 0 / P=5
N = [(15-5) / 0] + 2 = ??
Patch의 개수가 3이 나와야 할 것 같은데 앞에서 [10/0] 이 나온다.
코드는 또 이렇게 나와있다.
(수정 2024.01.13)
L = 15 / S = 5 / P = 10
N = [ (15-10) / 5 ] + 2 = 3
-------------------------------------------------------------------
음 좀 다른 부분이 있어서 당황스럽긴 하지만 저런 식의 공식으로 되어있긴 하니 넘어가자
## SELF SUPERVISED
num_patch = (max(args.context_points, args.patch_len)-args.patch_len) // args.stride + 1
print('number of patches:', num_patch)
## SUPERVISED
patch_num = int((context_window - patch_len)/stride + 1)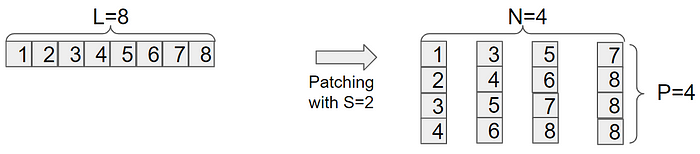
Transformer 인코더
저자는 관찰된 신호를 잠재 표현으로 매핑하는 vanilla Transformer 인코더를 사용합니다.
패치는 훈련 가능한 선형 투사 Wp ∈ R (D×P)를 통해 차원 D의 Transformer 잠재 공간에 매핑되며, 학습 가능한 가산 위치 인코딩 Wpos ∈ R(D×N)이 패치의 시간적 순서를 모니터링하기 위해 적용됩니다:
x(i)d = Wpx(i)p + Wpos, 여기서 x(i)d ∈ R(D×N)은 Figure 1의 Transformer 인코더에 입력될 입력을 나타냅니다.
그런 다음 다중 헤드 어텐션의 각 헤드 h = 1, ..., H는 이들을 각각 쿼리 행렬 Q(i)h = (x(i)d)TWQh, 키 행렬 K(i)h = (x(i)d)TWKh, 밸류 행렬 V(i)h = (x(i)d)TWVh로 변환합니다. 여기서 WQh, WKh ∈ RD×dk이고, WVh ∈ RD×D입니다. 그 후에 Scaled Dot-Product Attention을 사용하여 어텐션 출력 O(i)h ∈ RD×N을 얻습니다:
대략 이런 느낌인 것 같다.
[B, M X L ] -> [B, 1, L] -> [B,N,P] -> [B,N,D] -> [B,NXD] -> [B,T]
Loss Function
MSE
Instance Normalization
패치 전에 저자는 각각의 x(i)를 정규화하고, 평균과 편차를 출력 예측에 다시 추가합니다.
REPRESENTATION LEARNING
자기 지도 학습 기반의 표현 학습은 라벨이 없는 데이터로부터 HIGH LEVEL 추상 표현을 추출하는 인기 있는 방법론
PatchTST를 사용하여 다변량 시계열의 유용한 표현을 얻는 데 적용합니다.
학습된 표현이 예측 작업에 효과적으로 전이될 수 있다는 것을 보여줄 것입니다. 자기지도 사전 훈련을 통해 표현을 학습하기 위한 인기 있는 방법 중 하나인 마스크 된 오토인코더는 NLP (Devlin et al., 2018) 및 CV (He et al., 2021) 분야에 성공적으로 적용되었습니다. 이 기법은 개념적으로 간단합니다: 입력 시퀀스의 일부가 의도적으로 임의로 제거되고, 모델은 빠진 내용을 복원하기 위해 훈련됩니다.
마스크된 인코더는 최근에 시계열에서 사용되었으며, 분류 및 회귀 작업에서 주목할만한 성능을 보였습니다 (Zerveas et al., 2021). 저자들은 다변량 시계열을 Transformer에 적용하기를 제안했는데, 여기서 각 입력 토큰은 i번째 시간 단계의 시계열 값으로 구성된 벡터 xi입니다. 마스킹은 각 시계열 내부 및 다른 시계열 간에 임의로 배치됩니다. 그러나 이 설정에는 두 가지 잠재적인 문제점이 있습니다. 첫째로, 마스킹은 단일 시간 단계 수준에서 적용됩니다. 현재 시간 단계에서 마스킹된 값은 전체 시퀀스의 고수준 이해 없이도 즉시 직전 또는 직후 시간 값과 보간하여 쉽게 추론될 수 있으며, 이는 전체 신호의 중요한 추상 표현을 학습하는 목표에서 벗어납니다. Zerveas et al. (2021)은 다양한 크기의 시계열 그룹에 임의로 마스킹하는 복잡한 무작위화 전략을 제안하여 이 문제를 해결했습니다.
둘째로, 예측 작업을 위한 출력 레이어의 설계는 문제가 될 수 있습니다. L 개의 시간 단계에 해당하는 표현 벡터 zt ∈ RD가 주어지면, 이러한 벡터를 선형 매핑을 통해 M개의 변수가 포함된 출력에 매핑하는 것은 (L · D) × (M · T) 차원의 매개변수 행렬 W가 필요합니다. 이 행렬은 이 네 가지 값 중 하나 또는 모두가 큰 경우 특히 과도하게 크게 될 수 있습니다. 이는 하류 훈련 샘플의 수가 부족한 경우 오버피팅을 일으킬 수 있습니다.
저자는 제안한 PatchTST는 자연스럽게 앞에서 언급한 문제를 극복할 수 있다고 합니다.
Figure 1에 나와 있는 것처럼, 저자는 지도 학습 설정과 동일한 Transformer 인코더를 사용합니다.
예측 헤드는 제거되고 D × P 선형 레이어가 추가됩니다.
패치가 중첩될 수 있는 지도 학습 모델과는 달리, 각 입력 시퀀스를 정규적이고 중첩되지 않는 패치로 나눕니다.
이렇게 함으로써 관찰된 패치가 마스크된 패치의 정보를 포함하지 않도록 편의상입니다. 그런 다음 균일하게 무작위로 일부 패치 인덱스를 선택하고, 이러한 선택된 인덱스에 따라 패치를 0 값으로 마스킹합니다. 모델은 MSE 손실을 사용하여 마스크된 패치를 재구성하기 위해 훈련됩니다.
저자는 각 시계열마다 공유 가중치 메커니즘을 통해 서로 교차 학습되는 잠재 표현을 가지게 된다는 점을 강조합니다. 이 설계는 사전 훈련 데이터가 하류 데이터보다 다른 수의 시계열을 포함할 수 있는 것을 가능하게 합니다. 이는 다른 접근 방법으로는 실현하기 어려울 수 있다고 합니다.
EXPERIMENTS
DataSet

결과
당연히 잘 나오게 했으니, 결과는 좋을 것으로 본다...

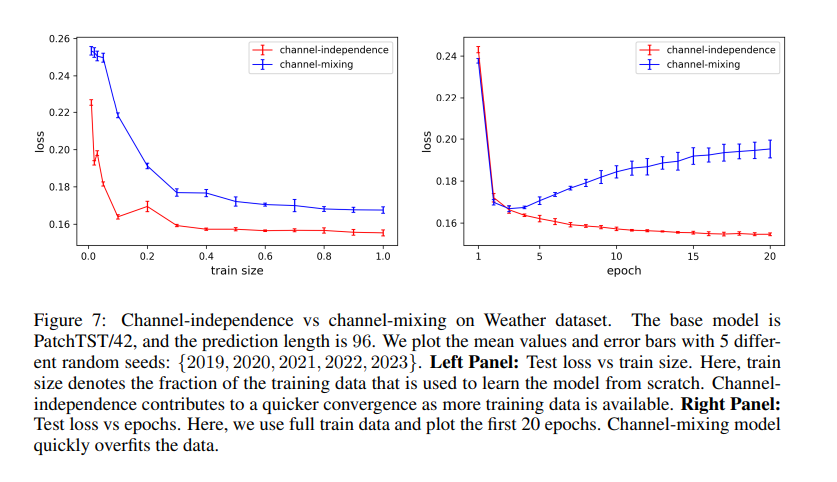
Channek-independence vs Channel-Mixining
Attention Map
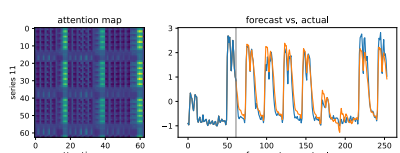

이 결과를 통해 상관관계가 높은 데이터는 잘 학습한다는 것을 알 수 있고, 그렇자 믾은 경우 학습 성능이 떨어진다는 것을 알 수 있다.
즉 외부 환경에 영향을 많이 받는 경우, 해당 모델은 사용하기 어렵다는 말일 수도 있다.
결론 및 향후 연구
본 논문은 패치링(patch)과 채널-독립 구조(channel-independent structure)라는 두 가지 핵심 구성 요소를 도입하여 시계열 예측 작업에 대한 Transformer 기반 모델의 효과적인 설계를 제안합니다.
이전 연구와 비교하여, 이 모델은 지역적 의미 정보를 포착하고 더 긴 과거 데이터를 활용하는 이점을 가지고 있습니다. 저자는 저자의 모델이 지도 학습에서 다른 기준 모델을 능가함을 보여줄 뿐만 아니라, 자기 지도 표현 학습과 전이 학습에서도 유망한 능력을 입증하였습니다.
저자의 모델은 향후 Transformer 기반 예측 작업의 기반 모델로서의 잠재력을 보여주며, 시계열 기반 모델의 구성 요소로 사용될 수 있습니다. 패치링은 간단하지만 다른 모델로 쉽게 전이할 수 있는 효과적인 연산자로 입증되었습니다. 반면, 채널-독립성은 다른 채널 간의 상관관계를 효과적으로 통합하기 위해 추가로 활용될 수 있습니다. 적절하게 다채널 종속성을 모델링하는 것은 중요한 향후 연구 단계가 될 것입니다.
코드
PatchTST_backbone을 봤을 경우 그리 특별한 것은 기존 Trnasformer 같은 경우 [B, SEQ_LEN, D_MODEL)이지만, 여기서는 각각의 변수가 개별적으로 처리하기 위해 [BATCH, nvars, seq_len]에서 시작한다는 점과 이것을
[batch, nvars, patch_len, patch_num [ 을 통해 해당 데이터를 쪼갰다는 것이 큰 특징이다.
이런 식으로 할 경우 self attention을 하게 되면 [batch, nvars, patch_num, d_model] 이 나올 것이다.
그래서 이거이 의미하는 바는 nvars 마다 집중하는 patch를 따로 보겠다는 뜻과 같다.
head_nf = d_model * patch_num
z: [bs x nvars x patch_len x patch_num]
z [bs x nvars x patch_len x (d_k * n_heads)]
z [bs, (nvars * patch_len) x n_head x d_k]
multihead attention
q_s = z [bs, n_head x (nvars * patch_len) x x d_k]
k_s = z [bs, x n_head x d_k x (nvars * patch_len) ]
score = z [bs, x n_head x (nvars * patch_len) x (nvars * patch_len) ]
- 이 부분이 약간 애매하다고 생각이 든다
output = z [bs, x n_head x (nvars * patch_len) x d_v x n_heads]
output = z [bs, x (nvars * patch_len) x d_model]
## encoder
output = z [bs, x nvars x patch_len x d_model]
output = z [bs, x nvars x d_model x patch_len]
그리고 한 가지 더 특이한 점은 revin_layer라는 게 있는 데, 이건 약간 통계치를 넣어주는 것이라고 볼 수 있다.
dlinear에서 본 것처럼 seasonal decompose 역할을 좀 넣어준 것 같다.
마지막으로 head를 보면, 논문에서 이야기한 것처럼 univate 하게 따로따로 값을 구하는 코드가 들어가 있는 것을 알 수 있고 이것 역시 dlinear와 유사한 부분이 있는 것 같고, 마지막으로 특이하게 dropout을 넣어준다.
약간 이게 의미하는 바가 좀 쓰려면 쓰고 말려면 말라는 것 같고, 마지막에 다시 denorm을 하는데, 이때 기존에 가지고 있던 통계치를 다시 집어넣어 줘서 복원하는 것 같은데...
결국 AI가 학습하는 부분은 대푯값은 가만히 두고, 과거 데이터 대비 그 사이에 변화량을 학습하게 한 코드라는 생각이 든다.
def forward(self, z): # z: [bs x nvars x seq_len]
# norm
if self.revin:
z = z.permute(0,2,1)
z = self.revin_layer(z, 'norm')
z = z.permute(0,2,1)
# do patching
if self.padding_patch == 'end':
z = self.padding_patch_layer(z)
z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len]
z = z.permute(0,1,3,2) # z: [bs x nvars x patch_len x patch_num]
# model
z = self.backbone(z) # z: [bs x nvars x d_model x patch_num]
z = self.head(z) # z: [bs x nvars x target_window]
# denorm
if self.revin:
z = z.permute(0,2,1)
z = self.revin_layer(z, 'denorm')
z = z.permute(0,2,1)
return z
class Flatten_Head(nn.Module):
def __init__(self, individual, n_vars, nf, target_window, head_dropout=0):
super().__init__()
self.individual = individual
self.n_vars = n_vars
if self.individual:
self.linears = nn.ModuleList()
self.dropouts = nn.ModuleList()
self.flattens = nn.ModuleList()
for i in range(self.n_vars):
self.flattens.append(nn.Flatten(start_dim=-2))
self.linears.append(nn.Linear(nf, target_window))
self.dropouts.append(nn.Dropout(head_dropout))
else:
self.flatten = nn.Flatten(start_dim=-2)
self.linear = nn.Linear(nf, target_window)
self.dropout = nn.Dropout(head_dropout)
def forward(self, x): # x: [bs x nvars x d_model x patch_num]
if self.individual:
x_out = []
for i in range(self.n_vars):
z = self.flattens[i](x[:,i,:,:]) # z: [bs x d_model * patch_num]
z = self.linears[i](z) # z: [bs x target_window]
z = self.dropouts[i](z)
x_out.append(z)
x = torch.stack(x_out, dim=1) # x: [bs x nvars x target_window]
else:
x = self.flatten(x)
x = self.linear(x)
x = self.dropout(x)
return xclass RevIN(nn.Module):
def __init__(self, num_features: int, eps=1e-5, affine=True, subtract_last=False):
"""
:param num_features: the number of features or channels
:param eps: a value added for numerical stability
:param affine: if True, RevIN has learnable affine parameters
"""
super(RevIN, self).__init__()
self.num_features = num_features
self.eps = eps
self.affine = affine
self.subtract_last = subtract_last
if self.affine:
self._init_params()
def forward(self, x, mode:str):
if mode == 'norm':
self._get_statistics(x)
x = self._normalize(x)
elif mode == 'denorm':
x = self._denormalize(x)
else: raise NotImplementedError
return x
def _init_params(self):
# initialize RevIN params: (C,)
self.affine_weight = nn.Parameter(torch.ones(self.num_features))
self.affine_bias = nn.Parameter(torch.zeros(self.num_features))
def _get_statistics(self, x):
dim2reduce = tuple(range(1, x.ndim-1))
if self.subtract_last:
self.last = x[:,-1,:].unsqueeze(1)
else:
self.mean = torch.mean(x, dim=dim2reduce, keepdim=True).detach()
self.stdev = torch.sqrt(torch.var(x, dim=dim2reduce, keepdim=True, unbiased=False) + self.eps).detach()
def _normalize(self, x):
if self.subtract_last:
x = x - self.last
else:
x = x - self.mean
x = x / self.stdev
if self.affine:
x = x * self.affine_weight
x = x + self.affine_bias
return x
def _denormalize(self, x):
if self.affine:
x = x - self.affine_bias
x = x / (self.affine_weight + self.eps*self.eps)
x = x * self.stdev
if self.subtract_last:
x = x + self.last
else:
x = x + self.mean
return x개인 생각
결국 코드를 보니, 개인적으로 느낀 것은 patch로 먼가 시계열성을 학습하기 보다는 역시 통계치를 기반으로 어느정도 근사치를 놔두고, 거기서 변화량을 학습하는 것으로 이해가 됬다.
물론 이러한 방식이 학습의 안정성도 높이고 수렴속도도 증가시킬 수 있을 것 같다.
다만, patch를 방식을 통해서 어떤 상관관계를 잘 학습한다고 말할 수 있는 지가 의문이긴 하다.
이러한 방식으로 학습하게 되면, 기존 값의 큰 차이가 없는 값이 대다수가 될 것이니, 변화량 정도가 학습이 될 것 같고추세가 급변하거나, 먼가 기존 패턴과 다른 특별한 이벤트가 발생할 경우, 성능이 안좋을 것 같다.
참고
http://dsba.korea.ac.kr/seminar/?mod=document&uid=2670
[Paper Review] A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers
[ 발표 요약 ] 1. Topic A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers 2. Overview 이번 세미나 시간에는 ICLR 2023에 accept 된 long-term time series forecasting(LTSF) 방법론 PatchTST를 공유하고자 한다.
dsba.korea.ac.kr
https://arxiv.org/abs/2211.14730
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are serve
arxiv.org
https://github.com/yuqinie98/PatchTST
GitHub - yuqinie98/PatchTST: An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with
An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers." (ICLR 2023) https://arxiv.org/abs/2211.14730 - GitHub - yuqinie98/PatchT...
github.com
PatchTST for Time Series Forecasting: Original Results and My Single-Channel Experiments
Motivation
medium.com
'ML(머신러닝) > Time Series' 카테고리의 다른 글
| TimeSeries) TSMixer 논문 및 구현 살펴보기 (5) | 2023.10.13 |
|---|---|
| TimeSeries) Transformer보다 좋다는 LSTF-Linear 알아보기 (0) | 2023.07.06 |
| TimeSeries) Transformer 기반 Time Series Forecast 논문 알아보기 (0) | 2023.07.05 |
| Python) Vector AutoRegressive Model in Python(Difference , Inverse Transform) (0) | 2023.04.03 |
| 계절형 자기회귀 이동평균모형(SARIMA) (0) | 2018.04.09 |