missing data는 통계적인 방법의 실재적 적용에 꽤 흔하다. 그리고 imputation은 완전하지 않은 데이터셋의 분석에서 쓰는 일반적인 통계적 기법이다.
2012년에 Stekhoven and Bühlmann 은 missing data를 처리하기 위해 iterative method라고 하는 missforest를 제안했다.
이 글에서는 missforest에 대해서 간단한 설명을 써보려고 한다.
흔히 MISSING에서는 3가지 메커니즘이 있다고 한다.

MCAR과 MAR 같은 경우에는 수많은 방법으로 대체가 가능하다
(mean / mode imputation, conditional mean imputation (regression imputation), stochastic regression imputation, hot deck imputation, substitution, cold deck imputation, maximum likelihood method (ML), EM algorithm, predictive mean matching, k-NN imputation.)
NMAR 같은 경우에는 좀 더 다르고 복잡한 접근방식을 요구한다.
Selection models or pattern-mixture models
또 다른 방식으로는 missforest가 있다고 한다.
p개의 변수가 있고 전체 (1~n) 개 중에서 임의의 변수 X_s는 미싱이라고 하자.
그럴 때 4가지 파트로 나눌 수가 있다.



왼쪽과 같은 데이터를 오른쪽 같이 4등분으로 나눈다는 의미이다.
현재 y_obs 는 결측치가 있는 한 개의 column을 의미하고 x_obs는 y_obs가 있는 행을 제외한 나머지 columns
y_miss 는 실제 결측치가 있는 한 개의 column에서 결측 값 x_miss는 y_miss가 속한 나머지 columns
missforest는 다음과 같은 흐름을 따른다.

1. 평균이나 다른 대체법으로 missing을 처음에 추측한다.
2. missing value의 양에 따라서 X_s를 정렬한다. 가장 낮은 것부터 시작
3. 각각의 변수 X_s를 반응 변수 Y_obs(s)를 사용하여 Randomfrest fitting을 한다. 그리고 예측을 하여 s_obs(s) 값을 얻는다. 그리고 그 값과 실제 결측치인 y_miss(s)에 예측을 한다.
4. 이러한 imputation 절차는 기준치 criterion gamma를 만족할 때까지 반복한다. 기준치 gamma는 새롭게 imputation data matrix와 기존의 matrix가 2개의 타입 변수(continuous , categorical)에 대해서 처음보다 커지는 즉시 충족된다?

continous 같은 경우에 공식을 보면 이전에 missing matrix와 새롭게 생성된 missing matrix 간의 차이를 빼고 제곱합을 해주고 새롭게 생성된 값의 제곱합을 나눠준 게 도함수? 가 된다.
categorical 같은 경우에는 이전 미싱 데이터와 현재 미싱 데이터가 같냐 같지 않냐라는 indicator 함수를 통해서 계산을 한다.
Continouos에서 Performance 측정은 NRMSE라고 하는 방법으로 측정을 한다.
이렇게 하는 이유는 아마 변수별 scale이 다르기 때문에 공정한 스케일로 비교하기 위해서? normalize 하는 것 같다.
흐음 개인적으로 궁금한 것은 scale 자체를 미리 변환해서 같게 유지하고 미싱만 비교를 하는 방식은 말이 안 되는 건지 궁금하다.
본 논문에서는 MCAR / MAR / NMAR 을 예시를 보여주니 글로 보는 것보다 이해가 잘 될 것 같다.

MCAR : 완전 임의 랜덤
MAR : X_mis에는 의존하지 않지만, 다른 X_obs에 의존해서 생기는 Missing data
NMAR : X_mis에 의존해서 생기는 Missing Data


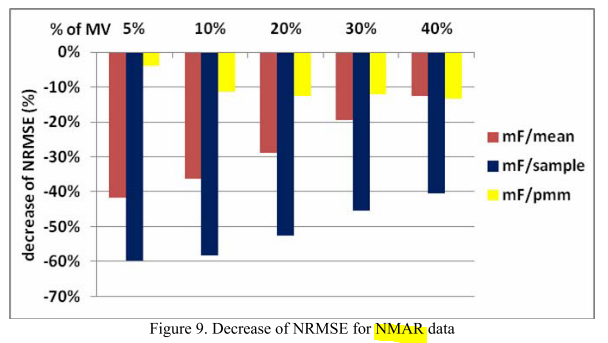
일단 기본적으로 MCAR / MAR 의 NRMSE 가 NMAR 보다 작게 나왔다고 한다.
그리고 그 안에서 missForest라는 대체 방법이 일단 MCAR / MAR에서 좋은 성과를 냈고, NMAR에서도 눈에 띄게 좋은 성과를 낸 것을 확인했다고 한다.
그리고 이렇게 NRMSE로 평가를 하다가 마지막에 논문에서는 적절하지 못한 매트릭이라고 말을 해버린다...
왜냐하면 결국 공식 자체에 분모쪽에 분산이 들어가는데 만약 분산 자체가 0.~~으로 만 돼도 엄청 큰 값을 내뱉게 하기 때문이다.
예를 들어, 현재 원래 데이터 분산이 1인데 미싱으로 인해 나머지 SAMPLE 값의 분산이 0.01이면 NRMSE는 무려 10배가 증가하게 된다.
- 끝 -
MISSFOREST PAPER URL
http://yadda.icm.edu.pl/yadda/element/bwmeta1.element.hdl_11089_10081/c/18-misztal.pdf
'ML(머신러닝) > BASIC' 카테고리의 다른 글
| Measure Theory (Measureable space and Probability space) 공부해보기 (1) | 2021.05.29 |
|---|---|
| 지도 학습에서 사용하는 목적 함수 정리하기 (1) | 2020.03.12 |
| 차원 축소에 대한 10가지 팁(Ten quick tips for effective dimensionality reduction) (0) | 2019.08.11 |
| Binary Classification 중 주의해야 할 것과 팁 (0) | 2019.05.30 |
| 모델평가와 성능평가 _미완성 (0) | 2018.01.15 |