일단 테스를 해봤을 때 잘 작동하는 것을 확인하였고, 궁금해서 더 찾아보니, 논문까지도 나와있었다.
그래서 왜 이런 게 논문까지 나왔을까 보니, 여러 환경들을 비교해보고 적합한 Environment라는 것을 주장하기 위해 논문이 나온 것 같다.
그래서 앞으로 MARL 환경 구축시에 참고할 수 있을 것 같아 빠르게 읽어보고자 한다.
본 논문에서는 PettingZoo 라이브러리와 함께 제공되는 에이전트 환경 사이클("AEC") 게임 모델을 소개한다. PettingZoo는 범용적이고 우아한 Python API를 가진 다양한 다중 에이전트 환경들의 라이브러리이다. PettingZoo는 Multi-에이전트 강화 학습("MARL")에 대한 연구를 가속화하는 것을 목표로 개발되었으며, 이는 개방형과 유사한 방식으로 작업을 보다 상호 교환, 접근성 및 재생산 가능하게 합니다.
AI의 Gym은 단일 에이전트 강화 학습에 성공했다.
PettingZoo의 API는 Gym의 많은 특징들을 이어받았지만, 새로운 AEC 게임 모델을 기반으로 한다는 점에서 MARL API들 사이에서 독특하다. 고 한다. 우리는 인기 있는 MARL 환경의 주요 문제에 대한 사례 연구를 통해 인기 있는 게임 모델이 MARL과 함께 일반적으로 사용되는 게임의 열악한 개념 모델이며, 탐지하기 어려운 심각한 버그를 조장하며, AEC 게임 모델이 이러한 문제를 해결한다고 주장한다.
현재 MARL에는 에이전트가 환경과 상호 작용하는 방식에 대한 사실상의 표준 API가 존재하지 않는다. 이는 새로운 목적을 위해 기존 학습 코드를 재사용하는 데 상당한 노력이 필요하며, 연구자의 시간을 소비하고 연구에서 보다 철저한 비교를 방지한다.
MARL이 기존과 다른 차이점은 Partially Observable Stochastic Games (“POSGs”) 와 Extensive Form Games("EFGs") 이다.
저자들은 개발 중에 이러한 일반적인 게임 모델이 코드로 구현된 멀티 에이전트 게임에 대해 개념적으로 적합하지 않으며 모든 유형의 멀티 플레이어 환경을 깨끗하게 처리하는 API의 기초를 형성할 수 없다는 것을 발견했다.
그래서 저자는 위와 같은 문제를 해결하기 위해 에이전트 환경 사이클 (AEC) 게임을 소개한다고 한다.
이 모델이 코드로 구현된 게임에 더 나은 개념적 적합이라고 주장한다. 일반 MARL API에 고유하게 적합하다고 주장한다.
그런 다음 저자는 모든 AEC 게임이 표준 POSG 모델로 대표될 수 있고, 모든 POSG가 AEC 게임으로 대표될 수 있다는 것을 증명한다.
AEC 게임 모델의 중요성을 설명하기 위해, 본 논문은 인기 있는 MARL 구현의 심각한 버그에 대한 두 가지 사례 연구를 추가로 다룬다. 두 경우 모두, 이 벌레들은 오랫동안 눈에 띄지 않았다. 두 게임 모두 혼동을 일으키는 게임 모델을 사용하는 것에서 비롯되었으며, AEC 게임 기반 API를 사용함으로써 불가능하게 만들어졌을 것이다.

배경
gym API는 단일 RL의 POMDP 개념화에서 차용되는 상당히 간단한 Python API이다.
이 API의 간단성과 개념적인 명확성은 매우 영향을 끼쳤고, 자연스럽게 강화학습 모델의 수학적인 모델과 pervasive mental에 사용되게 되었다.
이를 통해 RL 프레임워크에 대한 이해를 가진 모든 사람이 Gym의 API를 완전히 이해하는 것을 더 쉽게 할 수 있다.

Partially Observable Stochastic Games and RLlib
다중 에이전트 강화 학습은 단일 에이전트 강화 학습에서 POMDP 모델과 같은 보편적인 정신적 및 수학적 모델을 가지고 있지 않다.
가장 인기 있는 모델 중 하나는 부분적으로 관찰 가능한 확률 게임("POSG")이다. 이 모델은 다중 에이전트 MDP [Boutilier, 1996], Dec-POMDPs [Bernstein et al., 2002] 및 Stockastic("Markov") 게임[Shapley, 1953]과 매우 유사하며 엄격히 일반적이다
이 모델을 통해 단일 에이전트 RL 방법을 다중 에이전트 설정에 훨씬 쉽게 적용할 수 있게 되었다. 그러나 이 모델에는 두 가지 즉각적인 문제가 있습니다.
1. 체스와 같이 엄격하게 턴 기반 게임을 지원하려면 비액션 에이전트(또는 유사한 트릭 사용)에 대한 더미 동작을 지속적으로 전달해야 한다.
2. 에이전트 사망 또는 생성을 위해 에이전트 수를 변경하는 것은 학습 코드가 갑자기 변화하는 목록에 대처해야 하기 때문에 매우 어색하다.
MARL용 클래식 보드 및 카드 게임의 대규모 컬렉션이 있는 주요 라이브러리인 OpenSpiel [Lancot et al., 2019]는 아래 그림에 나와 있는 EFG 패러다임에서 API를 기반으로 한다.

EFG 모델은 게임 이론 분석 및 트리 검색과 같은 방법으로 정신 이론과 관련된 문제를 해결하는 데 성공적으로 사용되어 왔다. 그러나 일반적인 MARL 문제에 적용할 경우 EFG 모델에서 세 가지 즉각적인 문제가 발생한다.
1. 모델 및 해당 API는 POSG와 비교했을 때 매우 복잡하며 Gym과 같은 초보자에게는 적합하지 않습니다. 예를 들어 Gym의 API나 RLLib의 POSG API보다 환경 API가 훨씬 더 복잡합니다. 또한 EFG 모델의 복잡성으로 인해 강화 학습 연구자들은 POSG 또는 POMDP 모델을 사용하는 것과 동일한 방식으로 이를 게임의 정신적 모델로 사용하지 않는다.
2. 공식적인 정의는 게임이 끝날 때에만 보상을 포함하는 반면, 강화 학습은 종종 보상을 필요로 한다. API 구현에서는 이러한 작업을 수행할 수 있지만, 이상적이지는 않습니다.
3. OpenSpiel API는 연속적인 작업(RL의 공통적이고 중요한 사례)을 처리하지 않지만, EFG 모델에 내재되지 않은 선택이었습니다.

PettingZoo Design Goals
목표는 다음과 같다고 한다.
- Be Like GYM
- Be a Universal API
GYM 같이 만들기
- API를 Gym과 같은 모양과 느낌으로 만들고, API를 피톤컬하고 단순하게 만들기
- 메인 패키지와 함께 게임의 수많은 참조 구현 포함
일반화된 API 만들기
MARL을 위한 Gym과 같은 API가 있어야 한다면, 모든 사용 사례와 유형의 환경을 지원할 수 있어야 한다. 따라서, 신중하게 고려해야 하는 기술적으로 어려운 몇 가지 사례가 존재한다.
- 다수의 에이전트가 있는 환경
- 에이전트 사망 및 생성 환경
- 각 에피소드에 서로 다른 에이전트를 선택하여 참여할 수 있는 환경
- 특수한 하위 레벨 기능에 액세스해야 하는 학습 방법
유니버설 디자인을 위한 두 가지 관련 부드러운 디자인 목표는 초보자도 쉽게 사용할 수 있을 만큼 API가 간단하다는 것과, 해당 분야의 연구 방향이 크게 바뀌면 API를 쉽게 변경할 수 있도록 하는 것이다.
논문 Conclusion
multiagent rl에서 AEC (Agent Environment Cycle)이라는 것을 제안하였다
비 전문가도 mutlagent rl에 가능하게 하는 api를 만들었다고 주장한다.
한 가지 한계점은 만약 에이전트가 10,000개를 훨씬 넘는 게임은 각 에이전트를 한 번에 단계별로 수행하므로 성능 문제가 발생한다고 한다. 이런 것을 효율적으로 하기 위해서는 python 이외에 언어가 필요하고 그래야지 진정한 병렬 지원이 가능하다고 말하고 있다.
향후 작업으로는 3가지 방향으로 본다고 한다.
- 환경 추가
- 표준화된 API와 환경 세트를 활용하여 서로 다른 연구자의 에이전트가 COMPETITIVE GAME을 할 수 있는 서비스
- Gym procgen evironments과 유사하게 방법이 얼마나 잘 일반화되는 테스트 하기 위해 정착으로 생성된 다중 에이전트 환경의 개발을 구성한다고 함.
MARL의 POSG 모델 문제 사례연구
1. POSGs Don’t Allow Access To Information You Should Have
POSG 모델에서 동시 동작을 사용하는 모델링 환경의 또 다른 문제는 (모든 소스에서) 에이전트의 모든 보상이 합산되어 한꺼번에 반환된다는 것이다. 그러나 다중 에이전트 게임에서, 이 결합된 보상은 종종 다른 플레이어와 환경의 액션으로 인한 복합 보상이 된다. 마찬가지로, 다양한 학습 이유 또는 보상의 출처를 찾기 위한 디버깅 목적으로 이 보상의 출처를 지정할 수 있습니다.
그러나, 보상 기원에 대해 생각할 때, 모든 보상이 동시에 배출되는 것은 다른 보상이 모두 결합되기 때문에 매우 혼란스러운 것으로 입증된다.
POSG를 본떠 모델링된 API를 통해 이 정보에 접근하려면 모델에서 벗어나야 한다.
이는 목록 대신 2D 보상 배열을 반환하는 형태로 나타날 수 있으며, 이는 표준화가 어렵고 코드를 구문 분석하는 데 불편할 수 있다.
이것이 실제로 문제를 일으킨 주목할 만한 사례는 굽타 등의 인기 추구 그리드 세계 환경에서이다. 그림 4에 표시된 [2017].
그 안에서, 8명의 적색 통제 가능한 추적자가 함께 협력하여 무작위로 움직이는 30명의 청색 회피자를 포위하고 포착해야 한다. 각 추적자의 작업 공간은 이산형(심부 방향 또는 아무 작업도 하지 않음)이며, 관측 공간은 추적자(주황색 상자)를 중심으로 한 7 ×7 상자이다. 추격자 또는 게임 경계에 의해 사방에 회피자가 포위되었을 때, 기여하는 추적자는 각각 5의 보상을 받는다.

pursuers가 먼저 움직인 다음, evaders가 무작위로 움직인 다음, 회피자가 붙잡혀서 보상을 방출하는지 여부를 판단하기 전에 말이죠. 따라서 "잡았어야 했다"는 evader는 실제로 포착되지 않는다. evader가 두 번째로 움직이는 것은 버그가 아니라 pursuer/evader 다중 에이전트 환경의 고전적인 장르에 복잡성을 가중시키는 방법일 뿐이다 [Vidal et al., 2002].
이것에는 다소 문제가 있어서 저자가 강조하는 방법론으로 가면 다음과 같다.
Pursuit이 AEC 게임으로 여겨질 때, 우리는 보상을 개별적인 단계들에 귀속시켜야 한다고 함.
그리고 그 break down은 pursuers이 주변 evanders로부터 결정론적 보상을 받는 것이 되고, 그 후에 뒤따라오는 evaders 때문에 무작위적인 보상이 됩니다. 보상의 이 임의의 구성요소(추적자가 이미 이동한 후 회피자 작용에 의해 야기된 부분)를 제거하면 우수한 성과로 이어져야 합니다.
이 경우 문제는 너무 무해해서 그것을 고치는 데는 두 줄의 코드를 교환해야 했다.
우리는 부록 A.1에서 이 성능 향상을 실험적으로 검증하여 평균적으로 이러한 변화가 학습된 정책의 예상 보상에서 최대 22%의 성능을 초래했음을 보여준다.
이 계열의 버그는 거의 모든 MARL 환경에서 쉽게 발생할 수 있으며, POSG 모델을 사용할 때 이를 분석하고 예방하는 것이 훨씬 쉬워진다. 모든 에이전트의 보상이 POSG 모델에서 함께 요약되기 때문에 코드를 볼 때 이 특정 문제는 매우 명백하지 않은 반면 개별 에이전트의 보상으로 강제적으로 보상이 돌아가면 이는 명확해진다.
또한 기존 환경에 이러한 문제가 있는 경우, 실제 보상 소스를 학습 코드 연구자에게 노출시킴으로써 다른 보상 소스를 제거하여 이와 같은 버그를 보다 쉽게 찾아 제거할 수 있으며, 원칙적으로 다양한 보상 소스에 자동으로 가중치를 부여하는 학습 알고리듬을 개발할 수 있다.
2. POSGs Based APIs Don’t Make Conceptual Sense For Games Implemented In Code
Introducing
race condition을 도입하는 것은 실제로 MARL 코드에서 매우 쉽게 범할 수 있는 실수이며, 멀티 에이전트 게임의 동시 모델은 게임 코드가 정상적으로 실행되는 방법을 대표하지 않기 때문에 이러한 현상이 발생한다.
이는 두 에이전트가 상충되는 작업(즉, 동일한 공간으로 이동)을 수행할 수 있는 다중 에이전트 환경에서 매우 일반적인 시나리오에서 비롯된다. 이러한 불일치는 환경(즉, 같은 공간에서 움직이는 것)에 의해 해결되어야 합니다. 이를 "tie-breaking"이라고 합니다.
앨리스와 밥이라는 두 명의 에이전트가 있는 환경을 생각해 보자. 앨리스가 먼저 발을 내딛고 동점자가 앨리스에게 편중되어 있다. 그러한 환경이 동시 동작을 갖는다고 가정하는 경우, 두 에이전트의 관찰이 어느 한쪽 작용 전에 수행될 것이며, 이로 인해 밥이 작용한 관찰은 편향된 동점 처리와 충돌이 발생할 경우 더 이상 환경을 정확하게 나타내지 못할 것이다. 예를 들어, 두 에이전트가 같은 정사각형에 발을 들여놓으려 하고 앨리스가 목록의 첫 번째에 있었기 때문에 정사각형에 도달했다면, 행동하기 전의 밥의 관찰은 사실상 부정확했고 환경은 실제로 평행하지 않았다. 이러한 행동은 진정한 경쟁 조건이며, 환경을 통과하는 결과는 에이전트 작업의 내부 해결 순서에 따라 우발적으로 다를 수 있습니다.
심지어 약간 복잡한 환경에서는 일반적으로 동점자가 처리되어야 하는 경우가 엄청나게 많습니다. 단 한 개라도 놓치는 경우, 환경에는 코드가 학습하려고 시도하는 race condition이 있습니다.
이러한 가능성을 찾는 것은 항상 중요하지만, 이러한 가능성을 완화하는 중요한 도구는 각 에이전트를 순차적으로 처리하여 이후에 새로운 관찰을 반환하는 API를 사용하는 것이다.
이것은 완전히 race condition을 소개할 기회를 막는다.
더욱이, 이 전체 문제는 소프트웨어 MARL 환경에 대해 에이전트를 순차적으로 업데이트하는 API를 사용하는 것이 일반적으로 업데이트를 동시에 모델링하는 것보다 더 개념적으로 타당하다는 사실에서 비롯된다.
환경의 작성자가 매우 복잡한 병렬화를 사용하지 않는 한, 환경은 실제로 한 번에 하나의 에이전트로 업데이트될 것이다.e. 부록 A.1에서는 사회적 순차적 딜레마 게임 환경의 오픈 소스 구현에서 이와 같은 인종 조건에 대한 사례 연구를 살펴본다. [Vinitsky et al., 2019] 이들은 다양한 형태의 자원 관리를 위한 새로운 행동을 연구하기 위해 고안된 인기 있는 다중 에이전트 그리드 세계 환경이며, 두 에이전트가 동시 API를 사용하는 동안 동일한 그리드의 리소스에 대해 작업하려고 하는 경우 불완전한 결합을 가지고 있다. 특히 이 버그는 매우 간단한 환경에서도 모든 동점자를 진정으로 편향되지 않게 만드는 것이 얼마나 어려운지를 보여준다. 특정 출처를 설명하는 데는 환경 규칙에 대한 많은 설명과 다이어그램이 필요하므로 이를 부록으로 설명한다고 한다. 한다.
The Agent Environment Cycle Games Model
POSG 및 EFG 모델을 MARL API에 적용하는 문제에 자극받아 에이전트 환경 사이클("AEC") 게임을 개발하였다. 이 모델에서 에이전트는 순차적으로 관찰을 보고, 에이전트가 조치를 취하고, 다른 에이전트에서 보상이 방출되며, 다음 에이전트가 선택된다. 이것은 사실상 순차적인 POSG 모델의 단계적 형태이다.
이렇게 하면 장점은 다음과 같다.
• 다양한 origin에 대한 보상의 명확한 속성을 보장하여 4.1절에서 설명한 다양한 학습 개선을 가능하게 한다.
• 4.2절에 기술된 바와 같이, 개발자가 혼란스럽고 도입하기 쉬운 race condition을 추가하는 것을 방지한다.
• 4.2절에 설명된 대로 컴퓨터 게임이 코드로 실행되는 방법은 보다 폐쇄적인 모델입니다.
• RL에서 요구하는 대로 모든 단계 후에 공식적으로 보상을 허용하지만, 섹션 2.2에서 설명한 것처럼 일반적으로 EFG 모델의 일부가 아닙니다.
• 섹션 2.2에서 논의되고 부록 C.2의 정의에 설명된 EFG 모델과 달리, 특히 초보자를 위한 멘탈 모델로 활동하기에 충분히 간단합니다.
• 에이전트 사망 또는 생성을 위해 에이전트 수를 변경하는 것은 덜 어색하다. 학습 코드는 섹션 2.1에서 설명한 것처럼 크기가 지속적으로 변화하는 목록을 설명할 필요가 없기 때문이다.
• 2.1절에서 언급한 동시 단계와 비교하여 범용 API의 경우 가장 나쁜 옵션입니다. 동시 스테핑은 모든 에이전트가 처리하기가 매우 어려운 작업을 수행할 수 없는 경우 비 op 작업을 사용해야 하는 반면, 모든 에이전트가 동시에 수행되고 자신의 작업을 대기열에 넣을 수 있는 순차적 스테핑 에이전트는 특별히 불편하지 않다.
부록 C.3에서 우리는 AEC 게임 모델을 수학적으로 공식화하지만, 형식주의를 완전히 이해하는 것은 논문을 이해하는 데 필수적인 것은 아니다.
부록 D에서 우리는 모든 AEC 게임에 대해 동등한 POSG가 존재하며 모든 POSG에 대해 동등한 AEC 게임이 존재한다는 것을 추가로 증명한다.
이는 AEC 게임 모델이 멀티 에이전트 환경의 가장 일반적인 최신 모델만큼 강력한 모델임을 보여준다.
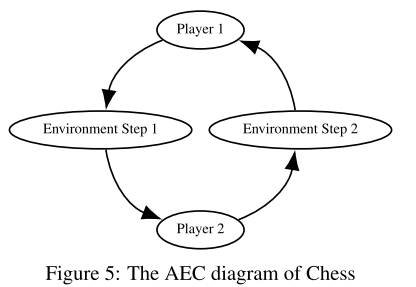
AEC 게임 모델의 한 가지 추가적인 개념적 특징이 존재하는데, 그 이유는 AEC가 API에서 일반적으로 역할을 하지 않기 때문이다(섹션 6.4 참조). AEC 게임 모델에서는 EFG의 Nature 에이전트와 유사한 "환경" 에이전트를 도입하여 POSG 모델에서 탈피한다. 이 에이전트가 모델에서 작동할 때 환경 자체의 업데이트를 나타내며 에이전트 작업 제출에 대해 인식하고 대응합니다. 이를 통해 보상에 대한 보다 포괄적인 속성, 에이전트 사망 원인, 이상한 업데이트 규칙과 레이스 조건을 가진 게임에 대한 논의가 가능하다. 체스의 전환의 예는 그림 5에 나타나 있으며, 이는 "에이전트 환경 주기"라는 이름의 영감 역할을 한다.
API Design
1. Basic API
각 에이전트에게 step function에서 하나의 액션을 제공한다. 그리고 observation, reward, done. info를 받는다.
observation과 state space는 또한 gym처럼 같은 공간 객체들을 사용한다.
render 와 close방법은 gym에서와 동일한 함수다. (현재 시각적인 것을 보여준다.)
reset 방법은 gym의 환경 함수와 유사하다.
pettingzoo는 오로지 gym에서 변경된 것은 2개다 바로 `last` , `agent_iter`이다.

2. The agent_iter Method
agent_iter 메서드는 환경이 동작할 다음 에이전트를 반환하는 환경의 생성자 메서드입니다.
환경이 다음 에이전트를 실행할 수 있도록 제공하므로 에이전트 동작 변경, 에이전트 생성 및 에이전트 사망과 관련된 모든 문제를 완전히 추상화합니다.
이 generation은 또한 AEC 게임 모델의 다음 에이전트 기능의 기능과 유사하다.
이 방법은 한 번에 작용하는 하나의 에이전트와 결합되어 에이전트 세트의 모든 상상할 수 있는 변동을 지원할 수 있다.
3. The last Method
다중 에이전트 환경의 특이한 측면은 한 에이전트의 관점에서 다른 에이전트는 환경의 일부라는 것이다.
단일 에이전트 사례에서 observation과 reward은 즉시 제공될 수 있지만, 다중 에이전트 사례에서 에이전트는 관찰, 보상, 수행 및 정보를 완전히 결정하기 전에 다른 모든 에이전트가 동작할 때까지 기다려야 한다.
이러한 이유로 이러한 값은 last 방법으로 지정되며, 그런 다음 정책에 전달되어 작업을 선택할 수 있습니다.
덜 강력한 구현은 에이전트 주문 변경과 같은 기능(예: Uno의 리버스 카드)을 허용하지 않을 것이다.
4. Additional API Features
에이전트 속성은 환경에 있는 모든 에이전트의 문자열 목록입니다.
reward, dones, infos, action_spaces 및 observation_spaces 속성은 각 속성에 대한 에이전트 키 사전입니다. (보상은 가장 최근의 동작에서 비롯되는 즉각적인 것이라는 점에 유의).
이렇게 하면 선택한 항목에 관계없이 궤적의 모든 지점에서 에이전트 속성에 액세스 할 수 있습니다.
observe(에이전트) method는 단일 에이전트의 이름을 인수로 전달하여 observation을 제공하며, 비정상적인 문맥에서 에이전트를 관찰해야 하는 경우 유용합니다.
state method는 중앙 집중식 critic method에 필요한 환경의 전역 상태를 반환하는 선택적 method입니다.
agent_selection method는 agent_iter별로 현재 수행될 수 있는 에이전트를 반환합니다.
이 모든 하위 수준의 정보에 대한 접근을 허용한 동기는 연구자들이 새롭고 특이한 실험을 시도할 수 있도록 하기 위함으로 구성했다고 한다.
다중 에이전트 RL의 공간은 아직 포괄적으로 탐색되지 않았으며, 다른 에이전트 보상, 관찰 등에 액세스 하기를 원할 수 있는 여러 가지 이유가 있다.
API가 새로운 분야에서 보편화되기 위해서는, 그것은 본질적으로 연구자들이 합리적으로 원할 수 있는 모든 정보에 대한 접근을 허용해야 한다.
이러한 이유로 우리는 표준 상위 수준 API 외에도 상당히 간단한 하위 수준 속성 및 메서드 집합에 대한 액세스를 허용한다.
아래 5에서는 간략하게 설명한 것처럼, 우리는 이러한 낮은 수준의 기능을 포함하는 것이 환경을 조성하는 데 엔지니어링 오버헤드를 초래하지 않도록 PettingZoo를 구성했다고 한다.
PettingZoo는 환경의 각 reset에 서로 다른 에이전트가 존재할 수 있는 환경을 처리하기 위해 임의의 시점에서 환경에 존재할 수 있는 모든 에이전트를 나열하는 possible_agents 속성을 가집니다.
환경을 재설정하면 에이전트 속성에 액세스 할 수 있게 되고 현재 활성 상태인 모든 에이전트가 나열됩니다. 비슷한 이유로 num_agents, rewards, done, infos 및 agent_selection은 재설정 후에나 사용할 수 있습니다.
정식 AEC Games 모델에 따라 환경에 환경 에이전트가 필요한 경우를 처리하기 위해 env라는 이름의 에이전트에 환경 에이전트를 넣고 없음이 수행되도록 하는 것이 표준입니다.
우리는 이것이 거의 사용되지 않고 API를 더 번거롭게 만들기 때문에 기본적으로 모든 환경에 이것을 요구하지는 않지만, 이것은 연구에서 특정 edge 사례에 중요한 특징이다.
이 기능은 이 기능을 사용하지 않을 때 공식 모델의 environment actor와 이전에 작용했던 agent actor가 함께 병합된다는 점에서 형식 모델에 연결된다.
5. Environment Creation and the Parallel API
PettingZoo 환경은 실제로 reset, seed, step, observe, render 및 close 기본 방법과 agents, rewards, dones, infos, state 및 agent_iter 기본 속성만 노출시킨다. 그런 다음 last 방법을 추가하기 위해 포장됩니다.
원시적인 방법을 구현하는 환경만이 새로운 환경을 보다 간단하게 만들고 코드 복제를 줄일 수 있습니다. 이것은 단순히 새로운 래퍼를 작성함으로써 모든 PettingZoo 환경을 대체 API로 쉽게 변경할 수 있게 하는 유용한 부작용을 가지고 있다. 우리는 이미 기본 환경에서 이 작업을 수행했으며 래퍼를 통해 RLlib POSG 기반 API와 거의 동일한 "병렬 API"를 추가로 추가했습니다. 에이전트 수가 매우 많은 환경에서는 파이썬 함수 호출 수를 줄임으로써 런타임이 개선될 수 있기 때문에 이 보조 API를 추가했다.
Default Environments
Gym의 기본 환경과 유사하게 PettingZoo는 63개의 환경을 포함한다. 포함된 환경 클래스(MPE, MAGENT, SISL)의 절반(MPE, MAGENT, SISL)은 인기에도 불구하고 유지 관리되지 않은 "연구 등급" 코드로 존재했으며, pip을 통해 설치할 수 없었으며, 정화 및 유지 관리 전에 많은 양의 유지보수를 필요로 했다. 또한 테리와 블랙[2020]의 멀티플레이어 아타리 게임, 독창적이고 우리만의 창조적인 버터플라이 환경, 인기 있는 클래식 보드 및 카드 게임 환경을 포함시켰다. 포함된 모든 기본 환경은 부록 B에 자세히 설명되어 있습니다.
Adoption
학습 라이브러리는 다음과 같이 채택함.
- The Autonomous Learning Library [Nota, 2020]
- AI-Traineree [Laszuk, 2020]
- PyMARL (ongoing) [Samvelyan et al., 2019]
- RLlib [Liang et al., 2018]
- Stable Baselines 2 [Hill et al., 2018] and Stable Baselines 3 [Raffin et al., 2019],
- CleanRL [Huang et al., 2020] (through SuperSuit [Terry et al., 2020a])
- Tianshou (ongoing) [Weng et al., 2020]
부록 (좀 더 봐야함)
Formal Definitions
3 Agent Environment Cycle Games


사실 아직 정확히 논문에서 환경을 어떻게 일반화했는지에 대해서 약간 의문적인 것이 있다. 예를 들어 에이전트의 순서나 joint action 같은 경우는 어떻게 처리할지, 각 액션 간의 상호관계는 또 어떻게 정의해야 하는지 등등 어떻게 보면 단일 에이전트들을 하나씩 돌린다는 느낌이 있다.
이러한 부분에서 이해할 수 있게 좀 더 찾아봐야 할 것 같다.
개인적으로 다중 강화 학습의 환경들이 구현된 것을 보면 아직 초창기라는 것이 느껴지는 게, 각자 자유롭게 환경을 구성한다는 것에 있다. 저자는 이러한 점에서 새롭게 잘 정리해서 제안을 하는 것 같고, 이 방법이 가장 좋은 방법인지는 좀 더 부록에 있는 내용을 봐야 알 것 같다. 그래도 다른 gym과 유사하게 가도록 노력하였기 때문에 기존에 연구자들이 활용하기에는 좋아 보일 것 같다.
다음에는 좀 더 코드 차원에서 보려고 한다.
| docs | https://www.pettingzoo.ml/# |
| paper | https://github.com/PettingZoo-Team/PettingZoo.git |
| youtube | https://www.youtube.com/watch?v=IMpf_X1IN_0&ab_channel=SyntheticIntelligenceForum |
'관심있는 주제 > RL' 카테고리의 다른 글
| RL) Reinforcement Learning for Portfolio Management - 논문 (0) | 2021.07.19 |
|---|---|
| Paper) Multi-Agent Game Abstraction via Graph Attention Neural Network (0) | 2021.07.03 |
| Paper) Decision Transformer: Reinforcement Learning via Sequence Modeling (0) | 2021.06.08 |
| RL) DuelingDQN 알아보기 (0) | 2021.06.03 |
| Paper) Reward is Enough 관련 자료 (4) | 2021.05.31 |