딥러닝 모델들이 black-box 형태의 모델이기 때문에 해석을 하는 데 있어서 사람들의 많은 요구사항들이 있다.
그중에서 유명한 것은 eli5, shap, lime, skater와 같은 알고리즘들을 사용하고, 만약 이러한 알고리즘을 적용하기 어렵다면, surrogate model을 통해 해당 모델에 대한 설명 가능한 모델을 새로 만들어서 모델을 해석하는 방법도 있다.

아래 블로그는 XAI에 대해서 정리한 글이라서 참고하시면 될 것 같다.
해당 글에서는 ELI5 /Skater / SHAP에 대한 설명을 해주고 있다.
대한 예제는 해당 블로그에도 있으니 참고하길 바란다.
여기선 skater라는 것을 보게 됐는데, 이것도 적용을 해봐야겠다.
Hands-on Machine Learning Model Interpretation
A comprehensive guide to interpreting machine learning models
towardsdatascience.com
2번째 글은 그토록 찾고 있었던 딥러닝 프레임워크에 tabular data를 적용한 사례이다.
예전에 이 알고리즘을 봤을 때는 Scikit-learn 기반의 알고리즘들만 제공해줘서 포기했었는데,
이미 되고 있었다는 것을 확인할 수 있었다.
> 해봤지만, 내부 패키지를 조금 수정해야 사용할 수 있을 것 같음.
https://towardsdatascience.com/interpretability-of-deep-learning-models-9f52e54d72ab
Interpretability of Deep Learning Models
Model Interpretability of Deep Neural Networks (DNN) has always been a limiting factor for use cases where d, and such is the case for…
towardsdatascience.com
하지만 필자 Keras 기반보다는 Tensorflow raw 한 버전을 사용하는 것을 더 선호하기 때문에, 이 코드를 수정을 해보고자 하였고, 한 가지 정도? 이슈가 있어서 다음과 같이 수정한 것을 공유하고자 한다.
SHAP
일단 필자는 다음과 같이 구성했다.
- keras와 같은 형태로 만들기 위해서 raw 한 tensorflow를 class로 만들었다.
- shap 패키지 내부 코드에서 deep_tf.py에 keras 모델 이외에 다른 모델도 처리할 수 있게 변경할 필요가 있었다.
일단 Tensorflow class 모델을 만든다.

자 이제 이걸 medium에서 keras로 구현한 것과 같이 model을 넣어서 시도를 해보자.

일단 이것을 하기에 앞서 shap 내부에 있는 deep_tf.py 부분에 코드를 하나 수정해줘야 한다.
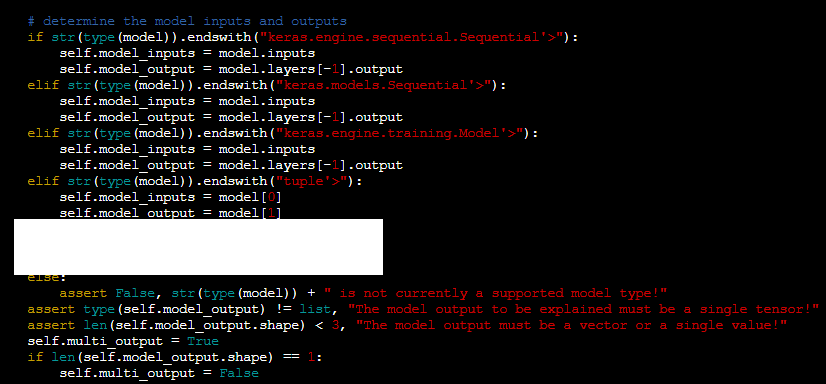
아마 처음 코드는 이렇게 되어있을 것이다. 즉 이 모델은 keras 모델만 가능하게 설정을 해놓은 상태이다.
하지만 내가 만든 class 모델의 타입은 다음과 같다.
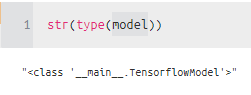
이렇게 때문에 이름 부분 중에서 Tensorflow를 인식할 수 있게, 이런 식으로 추가하였다.

이제 이렇게 하면, 통과하고 다음 이슈가 발생한다.

이런 식으로 weight가 초기화가 안됬다고 한다. 다행히 이것은 옵션을 주는 부분이 있어서 다음과 같이 class 내부에서 정의한 session을 가져왔다.

이제 이렇게 하면 일단 shap은 적용시켰다!! (오~)
이제 다음으로 한 개씩 실제로 적용한 결과를 보여주겠다.






일단 결과들의 해석은 나중에 해봐야 알겠지만, 정상적으로 잘 작동한 것을 확인했다!
일단 가장 직관적으로 알 수 있는 것은 우측 하단에 summary plot으로 기존 tree-based 알고리즘에서 해주는 변수 중요도를 표현해준다. 실제 이 모델에서 가장 중요하게 본 것은 PAY_6이라는 것을 알게 되었다.
LIME
기본적으로 SHAP 알고리즘에서 아쉬운 점은 변수 중요도가 범주형 변수를 원 핫 인코딩을 한 후에 해석해서 나온다는 것이다. 이것도 아마 내부 코드를 수정하면 해결할 수 있을 것 같지만, 일단 해봐야 알 것 같고
LIME 같은 경우에는 범주형 변수를 합쳐서 모아주는 기능이 있었다, 이 기능을 SHAP 알고리즘 내부에 잘 녹여주면 똑같이 할 수 있지 않을까라는 개인적인 생각을 해본다.
일단 특이했던 점은 categorical_feature은 index 정보를 categorical_names 은 column name의 dict형태를 넣어야 한다는 것이다. 일단 필요한 정보를 다음과 같은 코드로 얻어보자.

그다음에 lime에서 LimeTabularExplainer를 적용시킨다.
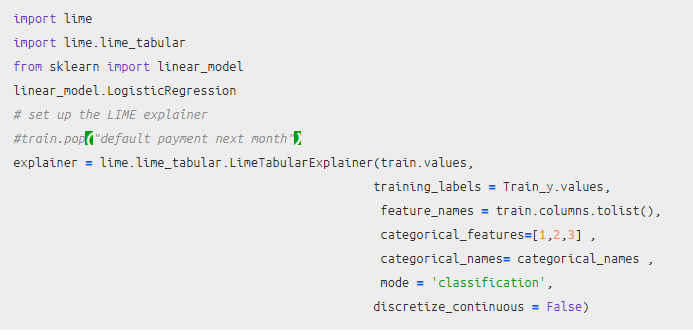
그다음에 샘플을 하나 뽑는데 중요한 것은 결측이 있으면 안 되는 결측을 처리해줘야 한다.
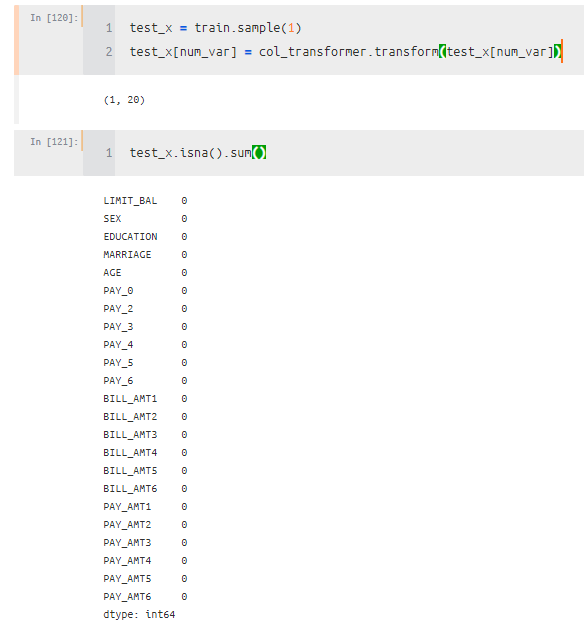
predict 함수를 정의하고 적용시킨다.
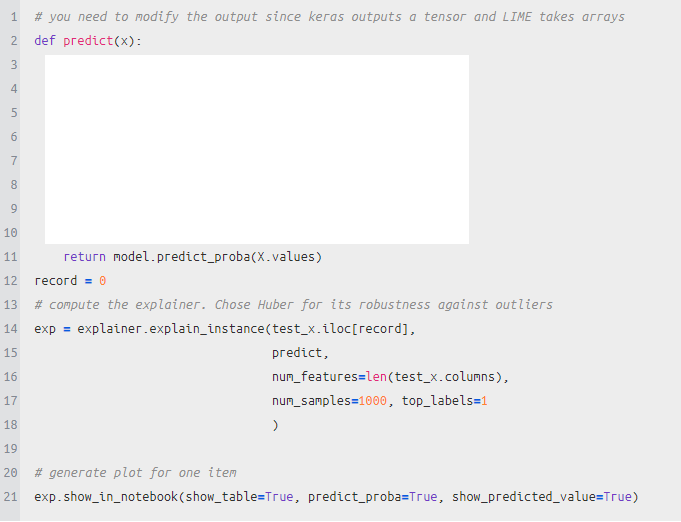
lime이 적용된 것을 알 수 있다.

이렇게 뜻밖에 글을 읽고 딥러닝 프레임워크를 정형 데이터에 적용할 수 있게 되었고, 앞으로 자주 사용할 것 같다.
추가적으로 eli5 , skater에도 적용할 수 있는지 확인해봐야겠다.
'관심있는 주제 > XAI' 카테고리의 다른 글
| Neural Additive Models:Interpretable Machine Learning with Neural Nets (0) | 2020.05.02 |
|---|---|
| Permutation importance 을 사용하여 딥러닝 모델 해석하기 (정형 데이터) (0) | 2020.03.26 |
| Interpreting complex models with SHAP values - 리뷰 (0) | 2020.02.29 |
| [ Python ] SHAP (SHapley Additive exPlanations) Decision plot 설명 (0) | 2019.09.08 |