목차
Objective
추천 시스템에는 다양한 종류들이 있다.
그래서 처음 하게 되면, 머부터 시작할지 다소 애매할 수 있다.
이 글은 아래 참고를 바탕으로 간 방법론 별로 간단한 코드를 정리해보고자 한다.

Implementation
Data 생성 및 구조
여기서는 유저별 아이템별 rating이 있는 데이터를 임의로 생성한다.
그리고 아이템별로 타입도 임의로 선정한다.
데이터는 사용자의 아이템별 rating과 아이템의 장르를 가진 테이블을 가지고 분석을 해본다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import gc
from collections import defaultdict
# synthesize data
NUM_USERS = 10_000
NUM_ITEMS = 1_000
user_id = np.arange(start = 0, stop = NUM_USERS)
item_id = np.arange(start = 0, stop = NUM_ITEMS)
np.random.seed(42)
user_item_dict = defaultdict(list)
genres = ['Action','Comedy','Drama','Fantasy','Horror','Mystery','Romance','Thriller','Western']
for id in user_id:
# random the number of item generation
# for each user, random 3 to 5 items to be rated.
num_rand_item = np.random.randint(low = 3, high = 5)
# random from the item_id
rand_items = np.random.choice(item_id, size = num_rand_item, replace = False)
# random rating for each itme_id
rand_rating = np.random.randint(low = 1, high = 10, size = num_rand_item)
# collect the user-item paris.
for uid, iid,rating in zip([id] * num_rand_item, rand_items, rand_rating):
user_item_dict['user_id'].append(uid)
user_item_dict['item_id'].append(iid)
user_item_dict['rating'].append(rating)
# prepare dataframe
ratings = pd.DataFrame(user_item_dict)
print("Rating Dataframe")
ratings[['user_id','item_id']] = ratings[['user_id','item_id']].astype(str)
display(ratings.head())
item_genre_dict = defaultdict(list)
for iid in item_id:
# random number of genres
num_rand_genre = np.random.randint(low = 1, high = 3)
# random set of genres
rand_genres = np.random.choice(genres, size = num_rand_genre, replace = False)
item_genre_dict['item_id'].append(iid)
item_genre_dict['genres'].append(', '.join(list(rand_genres)))
# prepare dataframe
items = pd.DataFrame(item_genre_dict)
print("\nItem Dataframe")
items = items.astype(str)
display(items.head())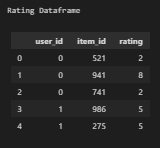

Popular Based
전체 데이테에서 인기 기반 구현은 빠르게 수행할 수 있다.
전체 사용자 중 평균 평점이 가장 높은 항목, 득표수가 가장 높은 항목 또는 시청한 회원 수부터 시작할 수 있다.
IMDB 시스템과 관련하여 각 영화의 등급을 매기는 데 사용되는 가중 등급 시스템(weighted rating)이라는 메트릭이 있습니다.
$$WR = \frac{v}{v+m} R + \frac{m}{v+m} C $$
$R$ 은 아이템의 평균 rating
$v$ 는 아이템에 투표한 수
$m$ 은 인기 항목에 나열되는 데 필요한 최소 투표수 (아래 코드 총 투표 수의 > 백분위수 80으로 정의)
$C$ 는 전체 데이터셋을 통해서 얻은 평균 rating
투표한 아이템의 평균값이 높을수록 아이템의 레이팅이 올라가는 구조다
여기에 추가적으로 아이템이 아닌 지역, 시간, 등등 다른 것도 고려해서 weighted rating 함수를 설정할 수도 있을 것이다.
def weighted_rating(v,m,R,C):
'''
Calculate the weighted rating
Args:
v -> average rating for each item (float)
m -> minimum votes required to be classified as popular (float)
R -> average rating for the item (pd.Series)
C -> average rating for the whole dataset (pd.Series)
Returns:
pd.Series
'''
return ( (v / (v + m)) * R) + ( (m / (v + m)) * C )
def assign_popular_based_score(rating_df, item_df, user_col, item_col, rating_col):
'''
Assigned popular based score based on the IMDB weighted average.
Args:
rating -> pd.DataFrame contains ['item_id', 'rating'] for each user.
Returns
popular_items -> pd.DataFrame contains item and IMDB weighted score.
'''
# pre processing
vote_count = (
rating_df
.groupby(item_col,as_index=False)
.agg( {user_col:'count', rating_col:'mean'} )
)
vote_count.columns = [item_col, 'vote_count', 'avg_rating']
# calcuate input parameters
C = np.mean(vote_count['avg_rating'])
m = np.percentile(vote_count['vote_count'], 70)
vote_count = vote_count[vote_count['vote_count'] >= m]
R = vote_count['avg_rating']
v = vote_count['vote_count']
vote_count['weighted_rating'] = weighted_rating(v,m,R,C)
# post processing
vote_count = vote_count.merge(item_df, on = [item_col], how = 'left')
popular_items = vote_count.loc[:,[item_col, 'genres', 'vote_count', 'avg_rating', 'weighted_rating']]
return popular_items
# init constant
USER_COL = 'user_id'
ITEM_COL = 'item_id'
RATING_COL = 'rating'
# calcualte popularity based
pop_items = assign_popular_based_score(ratings, items, USER_COL, ITEM_COL, RATING_COL)
pop_items = pop_items.sort_values('weighted_rating', ascending = False)
pop_items.head()

Content-based
아래 코드에서는 content-based 코드로써, 여기서는 아이템과 장르를 기반으로 유사도(코사인)를 계산해서 추천해주는 방식이다.
즉 사용자가 원하는 content에 대해서 벡터화를 해주고, 그 벡터화된 데이터를 가지고 유사도만 계산해주면 사용할 수 있는 방법이다.
from sklearn.metrics.pairwise import cosine_similarity
def top_k_items(item_id, top_k, corr_mat, map_name):
# sort correlation value ascendingly and select top_k item_id
top_items = corr_mat[item_id,:].argsort()[-top_k:][::-1]
top_items = [map_name[e] for e in top_items]
return top_items
# preprocessing
rated_items = items.loc[items[ITEM_COL].isin(ratings[ITEM_COL])].copy()
# extract the genre
genre = rated_items['genres'].str.split(",", expand=True)
# get all possible genre
all_genre = set()
for c in genre.columns:
distinct_genre = genre[c].str.lower().str.strip().unique()
all_genre.update(distinct_genre)
all_genre.remove(None)
# create item-genre matrix
item_genre_mat = rated_items[[ITEM_COL, 'genres']].copy()
item_genre_mat['genres'] = item_genre_mat['genres'].str.lower().str.strip()
# OHE the genres column
for genre in all_genre:
item_genre_mat[genre] = np.where(item_genre_mat['genres'].str.contains(genre), 1, 0)
item_genre_mat = item_genre_mat.drop(['genres'], axis=1)
item_genre_mat = item_genre_mat.set_index(ITEM_COL)
# compute similarity matix
corr_mat = cosine_similarity(item_genre_mat)
# get top-k similar items
ind2name = {ind:name for ind,name in enumerate(item_genre_mat.index)}
name2ind = {v:k for k,v in ind2name.items()}
similar_items = top_k_items(name2ind['99'],
top_k = 10,
corr_mat = corr_mat,
map_name = ind2name)
# display result
print("The top-k similar movie to item_id 99")
display(items.loc[items[ITEM_COL].isin(similar_items)])
del corr_mat
gc.collect();아래 결과는 99번째 영화에 대한 장르를 기준으로 유사한 아이템을 찾아서 나온 결괏값이다.

Collaborative filtering
여기서는 아이템과 유저 간의 행렬을 만들어서 진행한다.
협업 필터링 방법론에서는 크게 2가지 방법이 있다.
1. memory-based 2. model_based
1. Memory-based
from scipy.sparse import csr_matrix
# preprocess data
row = ratings[USER_COL]
col = ratings[ITEM_COL]
data = ratings[RATING_COL]
# init user-item matrix
mat = csr_matrix((data, (row, col)), shape=(NUM_USERS, NUM_ITEMS))
mat.eliminate_zeros()
# calculate sparsity
sparsity = float(len(mat.nonzero()[0]))
sparsity /= (mat.shape[0] * mat.shape[1])
sparsity *= 100
print(f'Sparsity: {sparsity:4.2f}%. This means that {sparsity:4.2f}% of the user-item ratings have a value.')
# compute similarity
item_corr_mat = cosine_similarity(mat.T)
# get top k item
print("\nThe top-k similar movie to item_id 99")
similar_items = top_k_items(name2ind['99'],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])
sparsity를 계산해보니 0.35%가 나왔고, 이 의미는 user-item 행렬에 0.35%만 값이 있다는 뜻이다.
이 자체를 그대로 이용하면 user 유사도를 계산하여, 유저 간의 가까운 정도를 계산할 수 있지만
여기서는 mat를 transpose 하여 user-item -> item-user로 변경하고 코사인 유사도를 계산해서 아이템 유사도에 대해서 구해지게 된다.

2. Model based
model based에서는 matrix factorziation 방법론도 있고, deep learning Matrix Factorziation 방법론도 있다.
1. Matrix Factorization (MF) based (TruncatedSVD )
from sklearn.decomposition import TruncatedSVD
epsilon = 1e-9
n_latent_factors = 10
# calculate item latent matrix
item_svd = TruncatedSVD(n_components = n_latent_factors)
item_features = item_svd.fit_transform(mat.transpose()) + epsilon
# calculate user latent matrix
user_svd = TruncatedSVD(n_components = n_latent_factors)
user_features = user_svd.fit_transform(mat) + epsilon
# compute similarity
item_corr_mat = cosine_similarity(item_features)
# get top k item
print("\nThe top-k similar movie to item_id 99")
similar_items = top_k_items(name2ind['99'],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])
del user_features
gc.collect();
model 기반 방법론에서는 여기서는 latent matrix를 만들기 위해서 TruncatedSVD 방법론을 사용했다.
마찬가지로 이 방법론을 사용하면 아이템뿐만 아니라 사용자 간의 유사도도 계산이 돼서, 가까운 사용자를 구할 수도 있다.
여기서 아이템 후보군을 찾으면 다음과 같다.

2. Matrix Factorization (MF) based ( Funk MF)

여기서 rating을 예측할 때는 다음과 같은 식을 따른다.
$\mu$ : 전체 ratings의 평균
$b_u$ : 아이템 bias term
$b_i$ : 유저의 bias term
$q_i$ : item latent factor matrix
$p_u$ : user latent factor matrix
아까 위의 방법론과는 다르게 아이템과 유저 정보를 다 사용해서 rating에 활용한다.

from surprise import SVD, accuracy
from surprise import Dataset, Reader
from surprise.model_selection import cross_validate
from surprise.model_selection.split import train_test_split
def pred2dict(predictions, top_k=None):
rec_dict = defaultdict(list)
for user_id, item_id, actual_rating, pred_rating, _ in predictions:
rec_dict[user_id].append((item_id, pred_rating))
return rec_dict
def get_top_k_recommendation(rec_dict, user_id, top_k, ind2name):
pred_ratings = rec_dict[user_id]
# sort descendingly by pred_rating
pred_ratings = sorted(pred_ratings, key=lambda x: x[1], reverse=True)
pred_ratings = pred_ratings[:top_k]
recs = [ind2name[e[0]] for e in pred_ratings]
return recs
# prepare train and test sets
reader = Reader(rating_scale=(1,10))
data = Dataset.load_from_df(ratings, reader)
train, test = train_test_split(data, test_size=.2, random_state=42)
# init and fit the funk mf model
algo = SVD(random_state = 42)
algo.fit(train)
pred = algo.test(test);
# evaluation the test set
accuracy.rmse(pred)
# extract the item features from algo
item_corr_mat = cosine_similarity(algo.qi)
print("\nThe top-k similar movie to item_id 99")
similar_items = top_k_items(name2ind['99'],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])
del item_corr_mat
gc.collect();

3. Generalized Matrix Factorization (Keras)

$\hat_y_{ui}$ : prediction of the user u on the item i
$a(out)$ : nn의 마지막 레이어의 activation function
$h^T$ : output layers의 edgw weight
$p_u$ : user latent vector
$q_u$ : item latent vector
$circle$ : element wise product operation
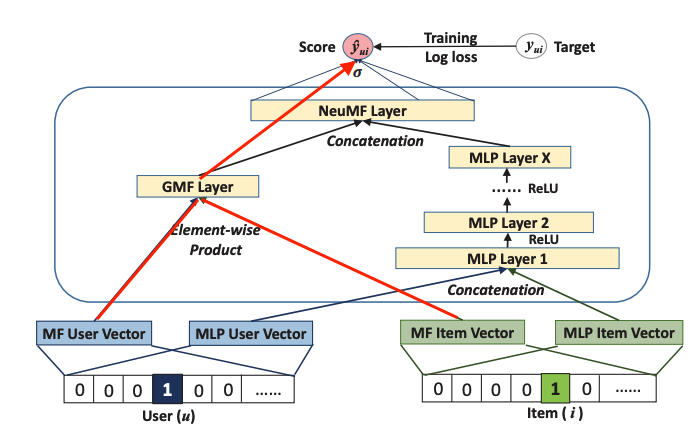
기존과는 다르게 딥러닝 방법론을 이용해서 유저와 아이템의 embedding값을 계산하고 나서, 임베딩 된 값을 concat 하고 다시 layer를 쌓아서 $\hat_y$ 를 계산하는 모델 구조이다.
그다음에 이 것이 rating을 잘 예측하면, 여기서 학습된 아이템에 대한 임베딩 행렬을 가지고 consine similarity를 계산해서 후보군을 뽑을 수 있다.
패키지 설치
pip install -q tensorflow-recommenders
pip install -q --upgrade tensorflow-datasets
pip install -q scann
from IPython.display import clear_output
import tensorflow as tf
import tensorflow_recommenders as tfrs
import tensorflow.keras as keras
from sklearn.model_selection import train_test_split
from typing import Dict, Text, Tuple
def df_to_ds(df):
# convert pd.DataFrame to tf.data.Dataset
ds = tf.data.Dataset.from_tensor_slices(
(dict(df[['user_id','item_id']]), df['rating']))
# convert Tuple[Dict[Text, tf.Tensor], tf.Tensor] to Dict[Text, tf.Tensor]
ds = ds.map(lambda x, y: {
'user_id' : x['user_id'],
'item_id' : x['item_id'],
'rating' : y
})
return ds.batch(256)
class RankingModel(keras.Model):
def __init__(self, user_id, item_id, embedding_size):
super().__init__()
# user model
input = keras.Input(shape=(), dtype=tf.string)
x = keras.layers.StringLookup(
vocabulary = user_id, mask_token = None
)(input)
output = keras.layers.Embedding(
input_dim = len(user_id) + 1,
output_dim = embedding_size,
name = 'embedding'
)(x)
self.user_model = keras.Model(inputs = input,
outputs = output,
name = 'user_model')
# item model
input = keras.Input(shape=(), dtype=tf.string)
x = keras.layers.StringLookup(
vocabulary = item_id, mask_token = None
)(input)
output = keras.layers.Embedding(
input_dim = len(item_id) + 1,
output_dim = embedding_size,
name = 'embedding'
)(x)
self.item_model = keras.Model(inputs = input,
outputs = output,
name = 'item_model')
# rating model
user_input = keras.Input(shape=(embedding_size,), name='user_emb')
item_input = keras.Input(shape=(embedding_size,), name='item_emb')
x = keras.layers.Concatenate(axis=1)([user_input, item_input])
x = keras.layers.Dense(256, activation = 'relu')(x)
x = keras.layers.Dense(64, activation = 'relu')(x)
output = keras.layers.Dense(1)(x)
self.rating_model = keras.Model(
inputs = {
'user_id' : user_input,
'item_id' : item_input
},
outputs = output,
name = 'rating_model'
)
def call(self, inputs: Dict[Text, tf.Tensor]) -> tf.Tensor:
user_emb = self.user_model(inputs['user_id'])
item_emb = self.item_model(inputs['item_id'])
prediction = self.rating_model({
'user_id' : user_emb,
'item_id' : item_emb
})
return prediction
class GMFModel(tfrs.models.Model):
def __init__(self, user_id, item_id, embedding_size):
super().__init__()
self.ranking_model = RankingModel(user_id, item_id, embedding_size)
self.task = tfrs.tasks.Ranking(
loss = keras.losses.MeanSquaredError(),
metrics = [keras.metrics.RootMeanSquaredError()]
)
def call(self, features: Dict[Text, tf.Tensor]) -> tf.Tensor:
return self.ranking_model(
{
'user_id' : features['user_id'],
'item_id' : features['item_id']
})
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
return self.task(labels = features.pop('rating'),
predictions = self.ranking_model(features))
# preprocess
train, test = train_test_split(ratings, train_size = .8, random_state=42)
train, test = df_to_ds(train), df_to_ds(test)
# # init model
embedding_size = 64
model = GMFModel(user_id.astype(str),
item_id.astype(str),
embedding_size)
model.compile(
optimizer = keras.optimizers.Adagrad(learning_rate = .01)
)
# # fitting the model
model.fit(train, epochs=3, verbose=0)
# evaluate with the test data
result = model.evaluate(test, return_dict=True, verbose=0)
print("\nEvaluation on the test set:")
display(result)
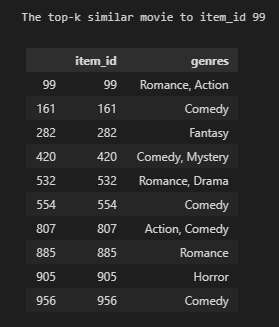
# extract item embedding
item_emb = model.ranking_model.item_model.layers[-1].get_weights()[0]
item_corr_mat = cosine_similarity(item_emb)
print("\nThe top-k similar movie to item_id 99")
similar_items = top_k_items(name2ind['99'],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])
del item_corr_mat
gc.collect();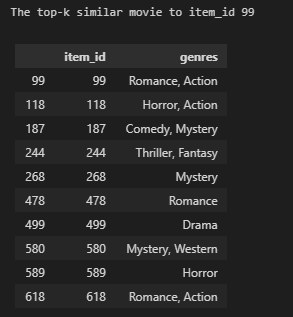
4. Deep learning MF - Neural Collaborative Filtering (recommenders)
recommenders라는 패키지를 사용하여 추천하는 방법론이다.
이미 사람들이 잘 만들어 놓은 것이 있는 것 같다.
패키지 설치
pip install recommenders
pip install tf-slimfrom recommenders.models.ncf.ncf_singlenode import NCF
from recommenders.models.ncf.dataset import Dataset as NCFDataset
from recommenders.datasets.python_splitters import python_chrono_split
from recommenders.utils.constants import SEED as DEFAULT_SEED
# Initial parameters
TOP_K = 10
EPOCHS = 50
BATCH_SIZE = 1024
SEED = DEFAULT_SEED
# default column name
ratings.columns = ["userID","itemID","rating"]
ratings["timestamp"] = pd.to_datetime('2022-01-23') + pd.to_timedelta(np.random.randint(-100,0,size=(len(ratings),)), unit='d')
train, test = python_chrono_split(ratings, 0.75)
data = NCFDataset(train = train, test = test, seed=SEED,col_timestamp=None)
model = NCF (
n_users=data.n_users,
n_items=data.n_items,
model_type="NeuMF",
n_factors=4,
layer_sizes=[16,8,4],
n_epochs=EPOCHS,
batch_size=BATCH_SIZE,
learning_rate=1e-3,
verbose=1,
seed=SEED
)
# fitting the model
model.fit(data)
# predict the data in the test set
predictions = [[row.userID, row.itemID, model.predict(row.userID, row.itemID)]
for (_, row) in test.iterrows()]
item_input = np.array([model.item2id[i] for i in test["itemID"].values.tolist()])
item_emb = model.sess.run( model.embedding_mlp_Q , feed_dict = {model.item_input : item_input[..., None] })
item_corr_mat = cosine_similarity(item_emb)
print("\nThe top-k similar movie to item_id 99")
similar_items = top_k_items(name2ind['99'],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])다만 아이템 유사도를 계산하기 위해서는 일부 코드를 좀 뜯어봐야 한다.
그리고 tensor flow 버전 1로 되어있어서, 수정하기도 쉬워 보이지는 않는다.
해당 패키지에는 다른 방법론들도 많이 있다.
- Bilateral Variational Autoencoder (BiVAE)
- Bayesian Personalized Ranking (BPR)
- Light Graph Convolutional Network (LigthGCN)
- Transformaer4Rec provided by Nvidia-Merlin
- List of Recommender System
Reference
https://github.com/microsoft/recommenders/tree/98d661edc6a9965c7f42b76dc5317af3ae74d5e0
'관심있는 주제 > Recommendation' 카테고리의 다른 글
| Paper) A Critical Study on Data Leakage in Recommender System Offline Evaluation 리뷰 (0) | 2022.03.26 |
|---|---|
| Paper) 추천 알고리즘들의 Data Split 전략에 대한 논문 리뷰 (2) | 2022.03.24 |
| Python) text content based recommendation (0) | 2022.01.23 |
| 추천-2 이웃 기반 협업 필터링(Nearest Neighbor Collaborative Filtering) (0) | 2022.01.19 |
| 추천-1 시스템의 목표 (0) | 2022.01.15 |