광고 한 번씩 눌러주세요! 블로그 운영에 큰 힘이 됩니다 :)
2020/05/01 - [관심있는 주제/RL] - 강화학습 - Dynamic Programming 공부
2020/05/05 - [관심있는 주제/RL] - chapter 4 Dynamic Programming Example Grid World
2020/05/05 - [관심있는 주제/RL] - chapter 4 Dynamic Programming Example Car Rental (in-place)
2020/05/05 - [관심있는 주제/RL] - chapter 4 Dynamic Programming Example 도박사 문제
강화학습을 공부하면서, 동적 프로그래밍 쪽에 대해서 깊게 할 이유가 있어서 자료 조사를 하고 있다.
일단 이전 것과 연관이 있기 때문에 직관적인 그림과 수식을 일단 복붙
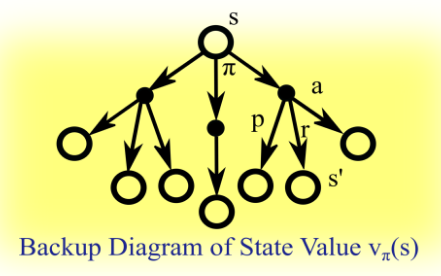
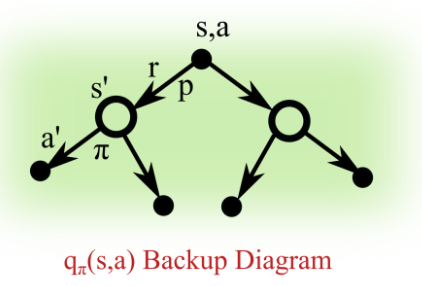

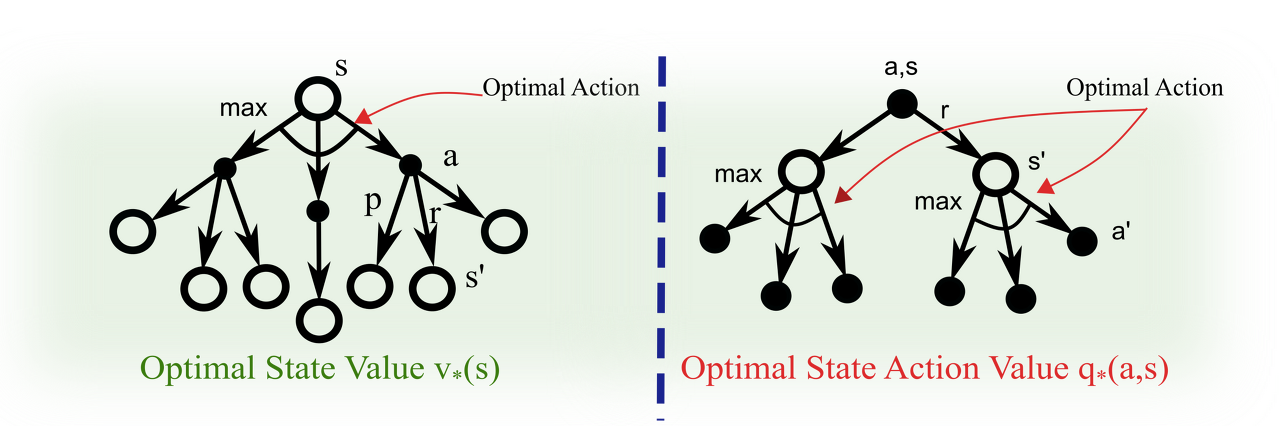


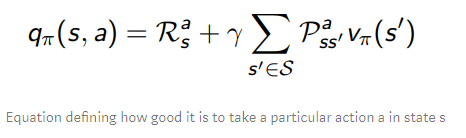


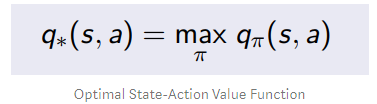



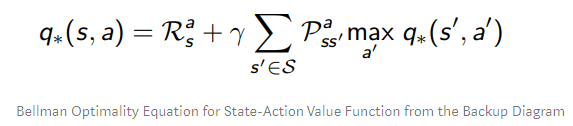
일단 어느 정도 위의 것에 대한 인지가 있어야 될 것 같아서 가지고 왔다.
Dynamic Programming(동적 계획법)이란?
Dynamic Programming은 전체 문제를 여러 개의 하위 문제로 나누어 풀고, 하위 문제들의 해결 방법들을 결합하여 최종 문제를 해결하는 문제 해결 방식이다.
(사실 의미만 동적이지, 실제 작동 방식에는 동적으로 되는 것이 없다고 함)
동적 계획법의 방법은 모든 작은 문제들을 한 번만 풀어야 한다고 함. 정답을 구한 것들은 저장해놓았다가
보다 큰 문제를 풀 때 똑같은 작은 문제가 나타나면 앞서 저장한 것들을 이용하여 결괏값을 내뱉음
이렇게 저장했다가 다시 재사용하는 것을 Memorization이라고 함. 이러한 예로는 피보나치 수열이 있음.
그러면 이게 강화학습에서는 어떻게 사용될까?
Sutton 교수님의 교재에서는 DP를 다음과 같이 정의한다고 함.
The term dynamic programming (DP) refers to a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP)


위의 글에서는 잘 정리를 해줬는데, 즉 하나의 문제를 2개로 쪼개 각각을 최적화하면 원래 문제를 최적화한다는 것과
서브 문제를 반복적으로 나타나기 때문에, 이 결과를 재사용 가능하다는 것이라는 이 2가지가 MDP에도 동일하게 적용이 되고
Bellman Equation과 Value function의 대표적인 특징을 가지고 때문에 강화학습에서 MDP를 가정한 상황에 그대로 적용할 수 있다고 말하는 것 같음
강화학습에서 동적 프로그래밍은 MDP 같은 환경 모델이 완벽하게 주어졌을 때 최적 정책을 계산하기 위해 사용되는 일군의 알고리즘이다. 여기서 설명하는 것은 Finite MDP로 모델링을 가정한다.
즉 상태 $S$ , 행동 $A$ 보상 $R$ 이 유한 집합이고, 환경의 동역학이 $p(s^',r|s,a)$로 주어진다고 가정한다.

모든 환경을 완벽하게 알기 때문에 Planning 할 수 있게 된다. 즉 아래 글처럼 Planning이라는 것은 환경을 알고 있을 때 미래에 대한 행동을 수행하지 않을 때도 할 수 있는 것을 의미한다.
What is meant by 'planning' in reinforcement learning?
Planning is coming up with future actions without performing them. This can be a sequence of actions, or a decision tree (“we’ll do this first, and then see if such-and-such are still true. If so, we’ll do this next, otherwise we’ll do that.”)
Planning requires a model of the world (since you need to be able to predict the possible or probable next situations) but does not require interaction with the environment.
(https://www.quora.com/What-is-meant-by-planning-in-reinforcement-learning)
그래서 우리가 보통 계획을 세우는 것처럼 무엇을 할 때 어떻게 될지(prediction) 그래서 어떻게 수정할지(control)를 세우는 것과 동일합니다. 그래서 강화학습에서 DP도 Prediction과 Control 이 2단계로 나눠집니다.
- Prediction (Policy Evaluation)
- MDP와 Policy가 있을 때 Value Function을 찾는 것
- Control (Policy Imporvement)
- MDP를 입력으로 하여, 기존의 Value Function을 더욱 최적화하는 것
- 즉 이것은 Optimal Value Function을 통해서 Optimal Policy를 찾을 수 있게 됨
Policy Evaluation
처음에는 아무것도 모르기 때문에 random policy를 진행할 것이다.
agent는 여러 번의 과정을 거쳐서 update를 하게 되고, 그러다가 결국 최적의 $V_{\pi}$를 찾게 됩니다.
이처럼 한 번에 하는 것이 어려우니 iteration을 반복해서 $V_{\pi}$에 접근하자는 것이 DP의 아이디어임
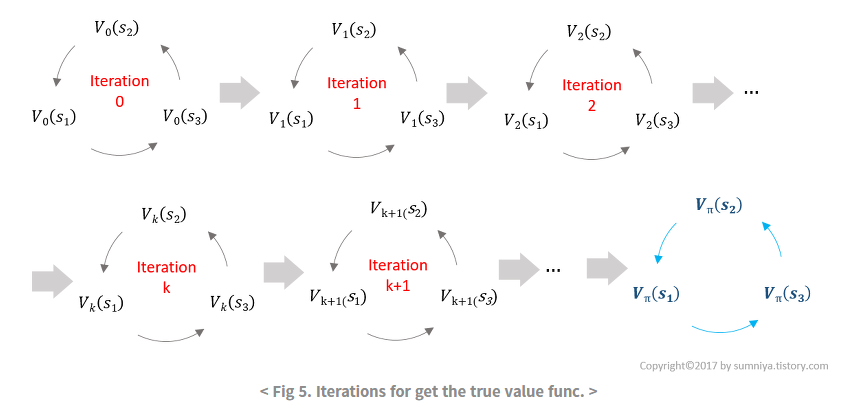
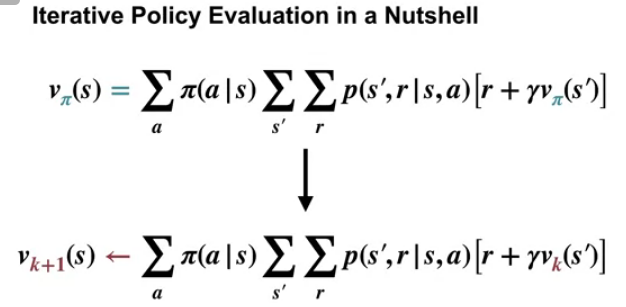
이렇게 반복하는 것이 Policy Evaluation임. 그리고 Policy Iteration에 사용하는 Value Function을 구하는 식은 계산 가능한 형태의 Bellman Expectation Equation임.

수식적으로 보면 다음과 같음.
이전 챕터와 다른 것은 k가 있다는 것이고, 의미는
state $S$ 의 (k+1) 번째 Value Function을 구할 때 state $S$의 k 번째 Value Function을 이용한다는 것이다.
이렇게 k를 이용해 k+1을 구한다는 것이 Back-Up이라고 함.

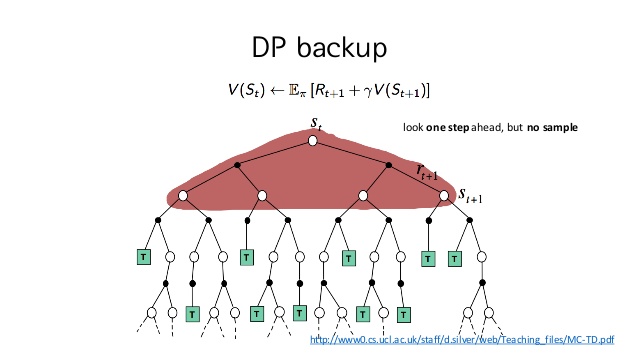

아래에 있는 영상에 1분 14초를 보면 iterative policy evaluation을 하는 과정이 나옴
3분 45초에는 grid world에서 수식적으로 풀어주는 부분이 나옴
https://ko.coursera.org/lecture/fundamentals-of-reinforcement-learning/iterative-policy-evaluation-ICAfp
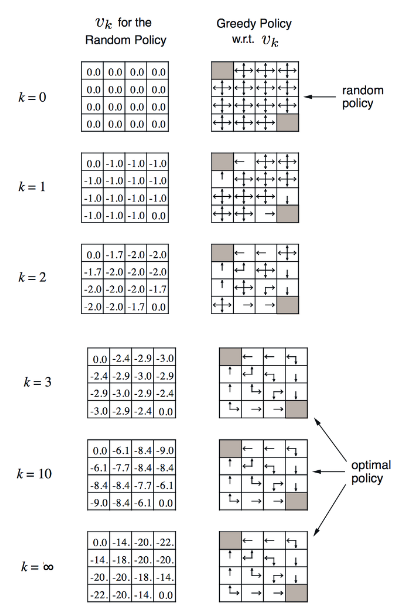
k=0일 때는 state value가 초기화되어 시작함.
k=1일 때는 0.25*(-1+0) * 4(동서남북) = -1
k=2일 때 한 가지만 계산해보면
-1.7 = 0.25*(-1+gamma*-1)+0.25*(-1+gamma * -1) + 0.25 *(-1+gamma*0) + 0.25*(-1+gamma*-1)
-1.7 = -1 + 0.75*gamma*-1 (gamma=0.9) (-1.675)
이러한 과정을 점점 반복하면 iteration k가 3 이상 되면 최적의 policy가 되면서 value가 업데이트가 된다.
여기서 최적의 policy는 반드시 1개가 아니라는 것을 알 수 있다.
그래서 이렇게 하다 보면 어떤 state든지 간에 policy를 따라 이동하면 terminal state에 도달할 수 있게 됩니다.
Policy Improvement
위에서 나온 Policy Iteration에서는 Iteration을 반복하면서 $V_{\pi}$를 찾았으면, 이 Policy를 따르는 것이 좋은지 안 좋은 지를 판단하고 Policy를 업데이트해야 함. 이를 통해 현재의 Policy보다 더 나은 Policy를 찾게 되고 점점 Optimal Policy에 가까워질 것임. 이러한 과정을 Policy Improvement
즉 다시 말하자면, 이전 Policy Iteration에서는 더 좋은 Policy를 찾는 것 그리고 Policy Evaluation을 통해서 임의의 $\pi$로부터 $V_{\pi}(S)$를 계산함. 여기까지 하면 State $S$에서는 현재 Policy $\pi$ 에 따르면 얼마나 좋은 지 $V_{\pi}(S)$ 알 수 있음.
그렇지만 더 좋은 Policy $\pi^*$를 찾으려면?
-> 탐욕적 정책(Greedy Policy)을 사용하면 구할 수 있고, 수렴성을 보장한다고 함



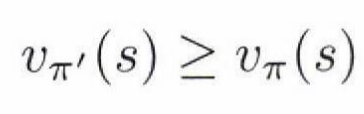
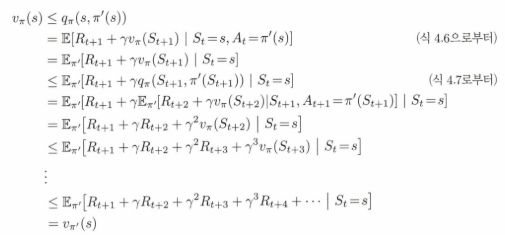
만약 식 4.7을 만족한다고 가정한다고 했을 때, 의미는 state에서 value function에 대한 action에 대한 평균값보다 새로운 정책을 취했을 때 state action value function이라는 가정이다. 이것의 평균에 의미해서 충분히 와 닿는 가정인 것 같다. 이제 그러면 이것을 t+1 시점에서도 t+2 시점에서도 쭉쭉쭉 적용한다면, 실제로 4.8을 만족하는 식이 나올 것이다.
즉 모든’ 상태에 대해,그리고 선택 가능한 ‘모든,행동에 대해, $q_{\pi}(s, a)$ 신의 측면에서 가장 좋아 보이는 행동을 선택하게 하는 정책의 변화를 생각해 보자. 다시 말해,다음과 같은 새로운 ‘탐욕적’ 정책 $\pi^*$’을 생각해 보자

위의 식에서 탐욕적 정책은 한 단계 앞을 보고 $v_{\pi}$ 측면에서 단기적으로 가장 좋아 보이는 행동을 선택한다(argmax) 탐욕적 정책은 위의 식 4.7의 조건을 만족하기 때문에 원래의 정책 이상으로 좋은 결과를 가져오게 한다.
이렇게 기존 정책 함수를 탐욕적(greedy)하게 함으로써, 기존 정책보다 좋아지게 만드는 과정을 Policy Improvement라고 한다.

만약에 새로운 탐욕적 정책이 기존 정책을 능가하지 못한다고 했을 때 $v_{\pi} = v_{\pi^*}$가 되고 다음의 관계가 성립한다.

이것은 아래에 4.1 최적 벨만 방정식과 같아지는 것을 알 수 있다!

다시 한번 말하지만, 모든 state $s$에 대해 $\pi^{*}$이 $\pi$보다 같거나 큰것을 찾기 위해서는 Greedy Policy를 통해 할 수 있다는 것이다.

https://www.coursera.org/lecture/practical-rl/policy-evaluation-improvement-UbMoQ
Policy Iteration
가치 함수 $v_{\pi}$를 이용하여 정책 $\pi$가 더 좋은 정책 $\pi^*$로 향상되고 나면 다시 $v_{\pi^*}$를 계산해서 더... 이런 것을 반복하게 된다. 이것을 Policy Iteration이라고 한다.
우리가 이러한 것이 가능한 이유는 Finite MDP를 가정하기 때문에 정책의 개수는 유한하며, 유한 횟수의 반복을 통해 최적 정책 및 최적 가치 함수로 수렴할 것이다.


하지만 문제는 이 방식에는 단점이 존재한다.
최적의 가치 함수 $V_{\pi}$ 를 업데이트할 때 Policy Evaluation에서 진행하는데, 문제는 수렴할 때까지 어느 정도 기다려야 한다는 것이다.
하지만 위의 Grid World에서 보면 converge를 기다릴 필요 없이 할 수 있었다.
여러 가지 방법이 있을 것이다. 중간에 멈춘다 할지라도 Policy Iteration의 수렴성은 보장이 된다.
Policy Evaluation의 계산 과정이 오직 한 번의 일괄 계산 이후에 중단되는 것이다.
이것을 Value Iteration라고 함.
Value Iteration
Policy Iteration과 다른 것은 Bellman Expectation Equation이 아니라 Bellman Optimality Equation을 사용한다는 것. Bellman Optimality Equation을 optimal value function 들의 사이의 관계식입니다.

state $S$ 의 (k+1) 번째 Value Function을 구할 때 state $S$의 k 번째 Value Function을 기댓값이 아닌 max를 통해서 greedy 하게 향상하겠다는 것임.(위에선 belleman expectation equation 사용 즉 평균(policy iteration))

위에서는 행동에 대한 평균값을 구했지만 각 iteration에서 max를 통해서 state value function을 얻는 방식을 사용함.
즉 k=2 state 1에서는 기존에 평균값을 이용했으면 -1.7이었지만, 여기서는 max를 취하므로 -1이 됨
k=2 state 2에서는 max를 취하므로 -2가 나옵니다. 위(policy iteration)에서는 평균을 취해서 -2가 나오는 것이다.
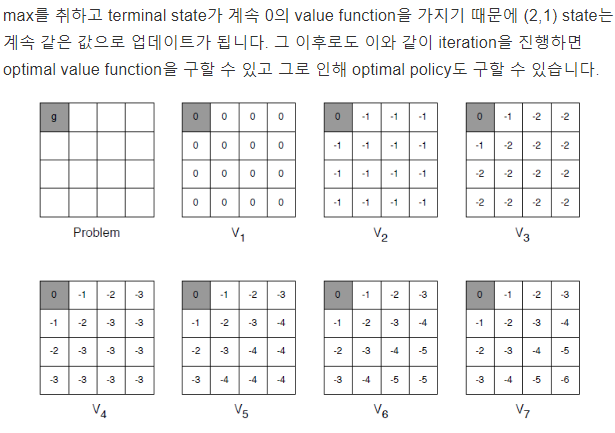
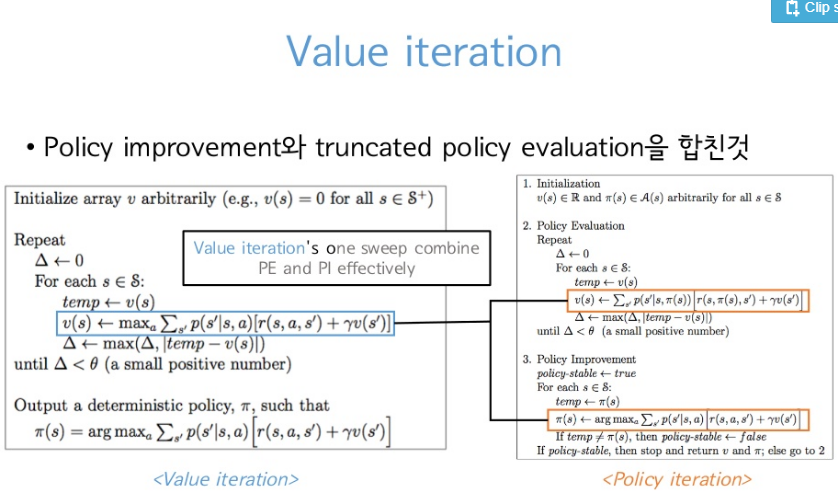
그래서 Value Iteration에서는 Policy Iteration 1 STEP + Policy Improvement이기 때문에 한 번의 업데이트를 하는 것을 알 수 있음

Policy Iteration나 Value Iteration 모두 Optimal Policy로 수렴은 하지만 오로지 discounted Finite MDP에서만 가능함

그리고 단점이 MDP의 모든 State를 계산하여하며, 각 계산마다 수렴할 때까지 필요한 Iteration이 있음
만약 State가 $10^20$개의 상태가 있다면, 한번 일괄적으로 계산하는데 몇 년이 걸릴 것임
그래서 이러한 문제를 해결하기 위해 비동기 동적 계획법(Asynchronous Dynamic Programming)이 나오게 됨
Asynchronous Dynamic Programming(비동기 동적 계획법)
비동기 동적 계획법은 상태 집합에 대해서 일괄 계산을 하지 않고 개별적인 (in-place) 반복 DP 알고리즘임
그래서 상태의 가치를 갱신하는 순서가 무엇이든 신경 쓰지 않고, 다른 상태의 가치를 이용할 수 있는 상황이라면, 그 값이 무엇이든 상관없이 다른 상태의 가치를 이용하여 해당 상태의 가치를 경신한다. 어떤 상태의 가치가 한 번 갱신될 동안 다른 상태의 가치는 여러 번 갱신될 수도 있다. 하지만 정확하게 수렴하도록 하기 위해 비동기 알고 리즘은 모든 상태의 가치가 갱신될 때까지 갱신을 계속 수행해야 한다. 따라서 갱신 과정이 어 느 정도 진행된 이후에는 모든 상태에 대해 갱신을 수행해야 한다 비동기 DP 알고리즘은 갱신할 상태를 선택하는 데 있어 대단히 유연한 알고리즘이다.


Generalized Policy Iteration
Policy iteration 은 현재 policy에 맞게 value function을 만드는 policy evaluation과 현재 value function에 맞게 greedy 한 policy를 만드는 policy improvement의 두 가지 프로세스로 이루어진다. Policy iteration에서 이 두 가지 프로세스가 번갈아가면서 진행되고, 각 프로세스는 다른 프로세스가 시작하기 전에 완료되지만 필수는 아니다. 예를 들어서, Value iteration에서는 각 policy improvement 사이에 policy evaluation 가 딱 한 번씩 진행된다. 비동기(asynchronous) DP에서는 더 미세하게 교차한다. 경우에 따라서 프로세스에서 오직 하나의 state 가 업데이트되어 다른 프로세스로 반환된다. 두 프로세스가 모든 state를 업데이트하기만 한다면, 궁극적으로 최종 결과는 optimal value function과 optimal policy로 수렴한다.
Policy evaluation과 Policy improvement의 세부사항과는 관계없이 두 가지 프로세스가 상호작용하는 일반적인 아이디어를 generalized policy iteration (GPI)로 표현한다.


GPI에서 evaluation과 improvement 프로세스는 경쟁하면서 동시에 협력하는 것으로 볼 수 있다. 서로 반대 방향으로 당긴다는 의미에서 둘은 경쟁한다. 일반적으로, Value function에 대해서 greedy 하게 policy를 만드는 것은 변경되는 policy에 대해서 value function을 부정확하게 만든다. 그리고 policy와 일치하는 방향으로 value function을 만드는 것은 policy 가 더 이상 greedy 하지 않다는 것을 의미한다. 그러나 장기적인 관점에서, 이 두 프로세스는 optimal value function과 optimal policy이라는 공통된 설루션을 찾기 위해서 상호작용한다.
또한, GPI에서 evaluation과 improvement 프로세스의 상호작용을 두 경계나 목표(goal) 측면에서 생각할 수도 있다. 예를 들어서, 위의 2차원 공간에서 두 선처럼 말이다. 사실 이것보다 더 복잡하지만, 다이어그램은 실제로 어떤 일이 벌어지는지 보여준다.
Efficiency of Dynamic Programming
DP는 매우 큰 문제에서는 실용적이지 않을 수 있다. 그러나 MDPs를 해결하는 다른 방법들과 비교하면 상대적으로 DP는 매우 효율적이다. 만약 기술적인 세부사항을 무시한다면, 최악의 경우 optimal policy를 찾기 위한 시간은 state와 action 수에 따른 다항식과 같다. nn과 kk를 state와 action의 개수라고 지칭하면, DP 식은 nn과 kk의 다항식보다 적은 계산을 한다는 것을 의미한다. DP 식은 policy의 총개수가 knkn 일지라도, optimal policy를 찾는 것을 보장한다. 이런 의미에서, DP는 모든 policy를 직접 조사하는 것(direct search) 보다 기하급수적으로 더 빠르다.
DP는 상태와 행동이 커지게 되면 차원의 저주(Curese of Dimensionality) 때문에 실용성에 한계가 있다고 여겨진다.
이는 문제 자체의 문제이지 알고리즘 DP의 문제는 아니다. 실제로 상태가 큰 문제에서는 direct search나 linear programming이 더 적합하다.
그래도 쓰고 싶기 때문에 비동기 동적 계획법 같은 것이 나오게 된 것 같다.
마지막

Sample BackUP
이렇게 Dynamic Programming에 대해서 살펴보았습니다. 처음에 언급했다시피 DP는 MDP에 대한 정보를 다 가지고 있어야 optimal policy를 구할 수 있습니다. 또한 DP는 full-width backup(한 번 update 할 때 가능한 모든 successor state의 value function을 통해 update 하는 방법)을 사용하고 있기 때문에 단 한 번의 backup을 하는 데도 많은 계산을 해야 합니다. 또한 위와 같은 작은 gridworld 같은 경우는 괜찮지만 state 숫자가 늘어날수록 계산량이 기하급수적으로 증가하기 때문에 MDP가 상당히 크거나 MDP에 대해서 다 알지 못할 때는 DP를 적용시킬 수 없습니다.
이때 등장하는 개념이 sample back-up입니다. 즉, 모든 가능한 successor state와 action을 고려하는 것이 아니고 Sampling을 통해서 한 길만 가보고 그 정보를 토대로 value function을 업데이트한다는 것입니다. 이렇게 할 경우 계산이 효율적이라는 장점도 있지만 "model-free"가 가능하다는 특징이 있습니다. 즉, DP의 방법대로 optimal 한 해를 찾으려면 매 iteration마다 Reward function과 state transition matrix를 알아야 하는데 sample backup의 경우에는 아래 그림과 같이 <S, A, R, S'>을 training set으로 실재 나온 reward와 sample transition으로서 그 두 개를 대체하게 됩니다. 따라서 MDP라는 model을 몰라도 optimal policy를 구할 수 있게 되고 "Learning"이 되는 것입니다. sample이라면 개념이 좀 어렵게 다가올 수도 있는데 처음에 강화 학습이 trial and error로 학습한다 했던 것을 떠올려서 sample이 하나의 try라고 생각하면 이해가 잘 될 것 같습니다. 즉, 머리로 다 계산하고 있는 것이 아니고 일단 가보면서 겪는 experience로 문제를 풀겠다는 것입니다.
DP를 sampling을 통해서 풀면서부터 "Reinforcement Learning"이 시작됩니다.
여기에는 Monte Carlo(MC) Temporal Difference(TD) SARSA





2020/05/01 - [관심있는 주제/RL] - 강화학습 - Dynamic Programming 공부
2020/05/05 - [관심있는 주제/RL] - chapter 4 Dynamic Programming Example Grid World
2020/05/05 - [관심있는 주제/RL] - chapter 4 Dynamic Programming Example Car Rental (in-place)
2020/05/05 - [관심있는 주제/RL] - chapter 4 Dynamic Programming Example 도박사 문제
'관심있는 주제 > RL' 카테고리의 다른 글
| chapter 4 Dynamic Programming Example Car Rental (in-place) (0) | 2020.05.05 |
|---|---|
| chapter 4 Dynamic Programming Example Grid World (0) | 2020.05.05 |
| state value / state action value 관련 자료 (0) | 2020.04.27 |
| Contextual Bandits and Reinforcement Learning - 리뷰 (0) | 2020.02.18 |
| Using Deep Q-Learning in the Classification of an Imbalanced Dataset - 리뷰 (0) | 2020.01.07 |