2020. 2. 18. 21:30ㆍ관심있는 주제/RL
2017년 글이지만 contextual bandits에 대한 어느 정도 알 수 있는 글인 것 같아서 읽어보기로 함
Estimating an Optimal Learning Rate For a Deep Neural Network
The learning rate is one of the most important hyper-parameters to tune for training deep neural networks.
towardsdatascience.com
만약 앱 또는 사이트에서 사용자 경험의 개인화를 개발하고자 한다면, Contextual bandits이 도움이 된다고 한다.
context bandits을 사용하면, 사용자에게 표시할 콘텐츠를 선택하고, 광고 순위를 매기고, 검색 결과를 최적화하며, 페이지에 최적화할 이미지 등 많은 것을 할 수 있다.
이 종류의 알고리즘에는 많은 이름이 있다. (contextual bandits, multi-world testing, associate bandits, learning with partial feedback, learning with bandit feedback, bandits with side information, multi-class classification with bandit feedback, associative reinforcement learning, one-step reinforcement learning.)
연구자들은 2가지의 다른 각도들로 문제를 접근한다.
- multi-armed bandits의 확장으로써 contextual bandits
- reinforcement learning의 간단한 버전
multi-armed bandits의 bandit은 one-armed bandit으로부터 나왔다.(casino에 있는 기계들)
카지노 안에 있는 많은 one-armed bandit machines을 상상해보라. 각 머신 마다 승리의 확률을 다르게 가지고 있다.
당신의 목표는 총수입을 최대화하는 것이다.
- 당신은 arms 기계의 제한된 숫자로만 이용할 수 있다.
- 당신은 최적의 수입을 얻기 위해 사용하는 bandit이 어떤 것인지 모른다.
이 문제는 exploration과 exploitation의 trade off와 연관이 있다.
당신은 모든 기계의 기대된 수입에 대하여 더 배우기 위해 다른 bandits들을 시도하는 것 사이에서 균형을 잡아야 할 뿐만 아니라, 기대 수입을 높여줄 최고의 bandit을 찾기도 원한다.
이러한 문제는 많은 현실 문제에 적용할 수 있다.
- website optimization
- clinical trials
- adaptive routing and financial portfolio
똑똑한 A/B testing이라고 생각할 수 있다.
the multiarmed bandit 알고리즘은 액션을 내뱉지만, 환경의 state(context)에 대한 정보를 거의 사용하지 않는다.
예를 들어, 만약 당신이 웹사이트 사용자에게 고양이 이미지든지 개의 이미지를 보여주는 것을 선택하기 위해 multi-armed bandit을 사용한다면, 당신은 당신이 사용자의 선호도에 대해 무언가를 알고 있더라도 같은 무작위 결정을 내릴 것이다. the contextual bandit은 환경의 상태를 조건하에 의사 결정하는 모델로 넓힐 수 있다.

이러한 contextual bandit은 이전 관측치를 기반으로 결정을 최적화할 뿐만 아니라, 모든 상황에서 결정을 개인화할 수 있다.
고양이를 좋아하는 사람에게는 고양이, 강아지를 좋아하는 사람에게는 강아지를 보여줄 수 있거나 시간에 따라서 다른 이미지를 보여줄 수도 있을 것이다.
이 알고리즘(contextual bandit)은 다음과 같은 프로세스를 가진다.
- 전후 사정을 관측하고,
- 의사 결정을 하고,
- 대안에 있는 행동들로부터 하나의 행동을 선택하고,
- 결정의 결과를 관측한다.
예를 들어, 만약 click through rate를 최적화하기 위해 웹사이트의 주요 페이지의 가장 먼저 표시할 뉴스 기사를 선택하기 위해 contextual bandit을 사용할 수 있다.
the context는 사용자에 대한 정보이다.
- 그들이 어디 출신인지
- 이전에 방문한 사이트의 페이지는 어떤 것인지?
- 핸드폰은 어떤 것을 쓰는지?
- 어디에 있는지? 등등
행동은 이러한 정보를 사용하여 보여줄 새로운 기사를 무엇으로 할지 선택한다.
결과는 사용자가 클릭을 하거나 하지 않는 것이다.
보상은 클릭하면 1, 안 하면 0
만약 모든 예에 대해 모든 가능한 행동의 보상값을 가지고 있다면, label을 최적의 보상으로써 행동으로 사용하고, features의 context data를 사용하여 어떤 분류 알고리즘을 사용할 수 있다.
문제 어떤 행동이 최적이라는 것을 모른다는 것이고 우리는 오로지 부분적인 정보만을 가지고 있다는 것이다.
: 사례에 사용된 행동에 대한 보상 가치
당신인 이러한 작업을 머신러닝으로도 할 수 있지만, 하려면 cost function을 변경해야 할 것이다. 순진한 실행은 보상을 예측하게 하는 것으로 하면 된다.
Microsoft published a whitepaper with an overview of the methodology and description of their implementation of a multi-world testing service.
이 서비스는 Microsoft Research Group에서 개발하였다. 이전에 이 그룹의 많은 연구자들은 야후에서 이 분야의 일을 하였다. Microsoft Multi-world test service는 Vowpal Wabbit을 사용한다. 이것은 contextual bandit을 위해 online과 offline 훈련 알고리즘을 실행하는 오픈 소스 라이브러리이다. offline training과 evaluation 알고리즘은 다음 논문에서 설명된다. “Doubly Robust Policy Evaluation and Learning”
두 가지 접근방식은 contextual bandits의 오프라인 학습을 다룬다.
- direct method(DM)이라고 부르는 것이 있는데, 주어진 데이터로부터 reward function을 추론하고, contexts의 셋에서 정책 값을 평가하기 위해 실제 보상 대신에 추정 값을 사용한다.
- inverse propensity score(IPS) historic data에서 잘못된 비율의 행동을 바로잡기 위해 중요 가중치를 사용한다.
1번째 접근은 정확한 보상 모델이 필요하고, 반면에 2번째 접근은 정확한 과거 정책 모델을 필요로 한다.
일반적으로 정확한 보상 모델을 만드는 것은 어렵다. 그래서 첫 번째 가정은 너무 제한적이다.
반면에 과거 정책을 모델하는 것은 충분히 가능하다. 그러나 두 번째 접근 방식은 종종 과거 정책이 평가된 정책으로부터 달라질 때 큰 분산을 가져서 고통받을 수 있다.
위의 논문에서는 doubly robust estimation을 사용하여 2가지 존재하는 접근법들에 대한 문제를 극복하려고 했다.
이 Doubly robust estimation은 중요한 속성을 가진 불완전한 데이터로부터 추정하기 위한 통계적인 접근이다.
두 추정자(DM, IPS) 중 하나라도 맞으면, 추정치는 편향되지 않는다고 한다.
따라서 이 방법은 신뢰할 수 있는 추론을 이끌어낼 가능성을 높인다.
아래 비디오는 contextual bandits에 tutorial이 있다.
| https://danmackinlay.name/notebook/bandit_problems.html
(더 다양한 자료) |
당신은 강화 학습을 contextual bandtis의 연장선상으로 생각할 수도 있다.
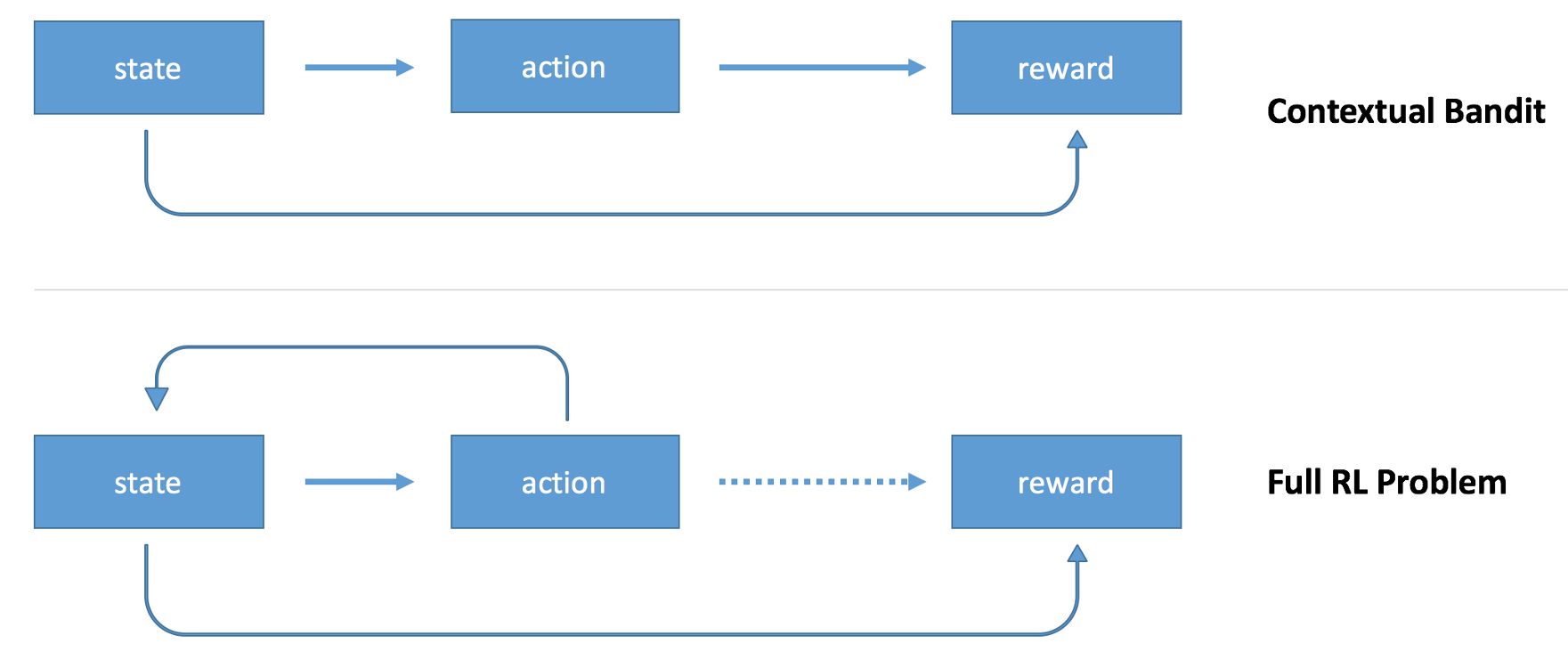
environment의 상태를 기반으로 행동을 하는 agent를 가질 수 있다. 그 후에 reward를 관측할 수 있다.
차이점은 agent가 연이은 행동을 할 수 있고, reward 정보는 sparse 하다는 것이다.
예를 들어, 만신이 체스를 플레이하는 모델을 훈련시킨다고 하자.
모델은 다음과 같은 프로세스를 가진다.
- context 로써 체스 판의 상태를 사용할 것이고,
- 어디로 움직 일지를 결정하고
- 그러나 오직 게임이 끝나는 순간에 보상을 얻을 것이다. (win / loss / draw)
reward 정보의 희소성은 모델을 훈련시키기 더 어렵게 한다. 당신은 신용 거래 문제의 한 종류로 접하게 할 수 있다.
얼마나 융자할지 또는 개인적인 행동을 책임으로 하던지.
강화 학습 알고리즘의 다양한 변종들이 있다. 강화 학습의 연장선 중에 하나는 Deep Reinforcement Learning이다.
DRL은 시스템의 일부를 딥 뉴럴 넷을 사용한다.
Simple Reinforcement Learning with Tensorflow Part 0: Q-Learning with Tables and Neural Networks
For this tutorial in my Reinforcement Learning series, we are going to be exploring a family of RL algorithms called Q-Learning algorithms…
medium.com
위의 글 참고
contextual bandits에 관심이 있는 연구원들은 더 나은 통계적 특성을 가진 알고리즘을 만드는 데 더 중점을 두는 것 같다. 예를 들어, regret guarantees.
Regret은 최적의 정책을 사용할 때 보상들의 합의 기댓값과 데이터로부터 배운 contextual bandit 정책을 사용한 보상들의 합 사이에서의 차이이다.
몇몇 알고리즘들은 regret의 upper bound에 대한 이론적인 보장을 가진다.
강화 학습에 관심이 있는 연구자들은 새로운 문제에 기계 학습 알고리즘을 적용하는 것에 더 관심이 있는 것 같다.
- robotics
- self-driving cars
- inventory management
- trading systems
그들은 종종 몇몇 문제들에 대한 state of the art를 개선할 수 있는 알고리즘 개발에 초점을 맞춘다.
이론적인 접근은 또한 다르다. Microsoft Multiworld Testing Whitepaper는 loss function을 negative IPS(inverse propensity score)를 사용한 training algorithm을 기술한다. loss function을 최소화하는 것은 IPS estimator의 최대화를 이끈다. 강화 학습 알고리즘에서 IPS estimator를 사용한 것을 찾을 수 없었다고 한다. 만약 당신이 policy gradient 기반의 강화 학습을 가지고 있고, 여러 단계를 1단계로 줄여 contextual bandit까지 간소화한다면, 그 모델은 마치 supervised classification model과 유사하게 될 것이다.
손실 함수의 경우 교차 엔트로피를 사용하지만 보상 값에 곱한다.
contextual bandits의 좁은 영역에 모여 있는 두 종류의 알고리즘을 비교하는 것은 흥미로웠다.
> 개인적으로 흥미롭게 읽었고, contextual bandits에 대해서 더 많이 공부해야겠다.
More Robust Doubly Robust Off-policy Evaluation
https://arxiv.org/abs/1802.03493
More Robust Doubly Robust Off-policy Evaluation
We study the problem of off-policy evaluation (OPE) in reinforcement learning (RL), where the goal is to estimate the performance of a policy from the data generated by another policy(ies). In particular, we focus on the doubly robust (DR) estimators that
arxiv.org
'관심있는 주제 > RL' 카테고리의 다른 글
| chapter 4 Dynamic Programming Example Grid World (0) | 2020.05.05 |
|---|---|
| 강화학습 - Dynamic Programming 공부 (0) | 2020.05.01 |
| state value / state action value 관련 자료 (0) | 2020.04.27 |
| Using Deep Q-Learning in the Classification of an Imbalanced Dataset - 리뷰 (0) | 2020.01.07 |
| RL A2C 관련 Loss Function, Advantage 확인 자료 (0) | 2019.11.16 |