
1. 바이브 코딩과 바이브 기획
현업 개발자 워크숍을 위한 50페이지 운영 가이드
이 문서는 "AI에게 어떻게 더 잘 물어볼까"보다 한 단계 앞의 문제를 다룬다. 실제 개발 조직에서 중요한 질문은 프롬프트 문장이 아니라, AI가 코드를 바꾸기 전에 어떤 제약, 검증, 책임선을 깔아두는가이다.
- 강의 가정: 대형 기술 조직의 시니어 개발자/개발자 교육자가 팀을 온보딩한다
- 대상: 1인 개발자, PM, 스타트업 팀, AI-assisted engineering 도입 조직
- 결론: 좋은 결과는 좋은 프롬프트보다 좋은 개발 운영 장치에서 더 자주 나온다
2. 이 덱을 어떻게 읽어야 하나
이 덱은 개념 설명 자료가 아니라 개발자 워크숍 자료다. 각 섹션은 "왜 필요한가"에서 멈추지 않고 "레포 어디에 설정할 것인가"까지 내려간다.
- 개념을 분리한다
- 왜 수정할수록 흔들리는지 이해한다
- 레포에 설치할 장치를 먼저 설계한다
- 실제 개발 루프와 CI에 연결한다
- 사례를 통해 운영 기준을 정한다
처음 듣는 개발자는 아래 하나만 먼저 해봐도 된다.
작은 UI 수정 하나를 정하고, AI에게 바로 구현시키지 말고 먼저 Explore -> Plan -> Verify 순서로만 시켜본다.
4. 바이브 코딩이란 무엇인가
바이브 코딩은 자연어 요청과 결과 확인, 다시 자연어 피드백을 빠르게 반복하는 방식이다. 코드 한 줄 한 줄을 직접 통제하기보다, 결과를 보면서 감각적으로 조정하는 면이 강하다.
짧은 원문 인용:
"forget that the code even exists" — Andrej Karpathy
이 말의 의미:
바이브 코딩의 원형은 코드를 세밀하게 리뷰하는 프로덕션 개발이 아니라, 결과를 보며 빠르게 감을 잡는 실험에 가깝다. 그래서 이 방식을 그대로 운영 코드에 가져오면 위험하고, 프로토타입에서 검증 체계로 넘어가는 경계가 필요하다.
- 저위험 실험, 버리는 프로토타입, 개인용 도구에 특히 잘 맞는다
- 구현 자체보다 반복 속도와 결과 체감에 무게가 실린다
- 아이디어를 빠르게 화면과 동작으로 바꾸는 데 강하다
flowchart LR A["자연어 요청"] --> B["AI 초안 생성"] B --> C["실행 결과 확인"] C --> D["자연어 피드백"] D --> B
flowchart LR
A["자연어 요청"] --> B["AI 초안 생성"]
B --> C["실행 결과 확인"]
C --> D["자연어 피드백"]
D --> B5. 바이브 기획이란 무엇인가
바이브 기획은 AI가 추측하지 않도록 문제, 사용자, 범위, 성공 기준, 검증 방법을 먼저 정리하는 방식이다. 여기서 중요한 것은 문서의 길이가 아니라, 빈칸을 줄이고 경계를 명확히 만드는 일이다.
짧은 원문 인용:
"the spec is the key" — Addy Osmani
이 말의 의미:
AI가 코드를 잘 쓰게 하려면 프롬프트를 멋지게 꾸미는 것보다, 먼저 좋은 스펙을 줘야 한다. 스펙은 요구사항 목록이 아니라 문제, 범위, 비목표, 완료 기준을 묶어 AI의 추측 공간을 줄이는 장치다.
- 누구의 어떤 문제를 줄이는지 먼저 고정한다
- 이번 반복에서 하지 않을 것을 분명하게 적는다
- 완료를 감이 아니라 관찰 가능한 조건으로 바꾼다
핵심 문장:
좋은 질문보다 좋은 경계가 먼저다.
6. 네 가지 운영 모드
실무에서는 모든 AI 작업을 한 단어로 부르면 자꾸 혼란이 생긴다. 그래서 아래 네 가지 모드를 구분해두는 것이 좋다.
| 모드 | 적합한 상황 | 사람이 책임질 것 |
|---|---|---|
| 바이브 코딩 | 개인 실험, 내부 도구 초안 | 결과 확인, 민감정보 배제, 비용 제한 |
| 바이브 기획 | 아이디어 구체화, 기능 설계 | 문제 정의, 비목표, 성공 기준 |
| AI-assisted engineering | 실서비스, 팀 개발 | 코드 이해, 테스트, 보안, 운영 |
| Agentic engineering | 장시간 작업, 병렬 에이전트 | 권한, 평가, 로그, 하네스 |
실무 해석은 단순하다. 프로덕션으로 갈수록 바이브 코딩보다 AI-assisted engineering 기준으로 옮겨가야 한다.
9. 왜 자꾸 수정할수록 망가지는가
많이 바꿨기 때문이 아니라, 바꾸는 단위와 판단 기준이 흔들렸기 때문에 망가진다. AI는 최신 지시를 잘 따르지만, 이전 판단이 남아 있는 코드 전체를 항상 깨끗하게 정리해주지는 않는다.
- 문제 정의가 흔들리면 코드 안에 서로 다른 의도가 공존한다
- 작은 수정이 누적되며 구조와 책임이 뒤섞인다
- 검증 없이 감각으로 수정하면 버그가 조용히 쌓인다
대표 증상:
- 고치라고 할수록 관련 없는 파일이 같이 바뀐다
- 기능은 되는데 구조가 납득되지 않는다
- 테스트는 통과해도 실제 요구사항은 어긋난다
11. 질문 전에 설치할 장치
좋은 프롬프트 하나로 모든 문제가 해결되지 않는 이유는, 프롬프트가 개발 운영체계를 대신해주지 못하기 때문이다. 개발자 관점에서 보면 이 장치들은 결국 "레포의 어떤 파일과 어떤 게이트로 AI를 제어할 것인가"의 문제다.
설계 장치
- 문제 프레임
- 비목표 울타리
- 성공 기준
- 컨텍스트 팩
통제 장치
- 계획 리뷰 게이트
- 변경 권한
- 검증 하네스
- 메모리 업데이트
워크숍 규칙:
장치가 말로만 있으면 실패한다. 반드시 docs/, AGENTS.md, package.json, CI, PR 템플릿 중 하나에 실제로 남긴다.
12. 장치 1: 문제 프레임
기능 목록보다 먼저 물어야 하는 질문은 "누구의 어떤 문제를 지금 줄일 것인가"이다. 문제 프레임이 약하면, AI는 멋진 기능을 만들어도 방향을 벗어나기 쉽다.
사용자:
현재 문제:
현재 우회 방법:
이 문제가 만드는 비용:
이번 버전에서 줄일 고통:어디에 두나:
docs/feature-spec.md맨 위- 작은 작업이면
.ai/tasks/<task-name>.md첫 섹션 - 팀이면 PRD의 opening summary
개발자 팁:
- "화면 만들기"보다 "사용자가 못 하던 행동 하나"로 적는다
- API나 DB보다 사용자 흐름 기준으로 쓴다
- 이 문단이 흔들리면 구현을 멈추고 다시 쓴다
강의에서 쓰는 체크:
git diff를 보기 전에 이 문제 프레임을 읽고, 이번 변경이 그 문제를 직접 줄이는지 먼저 확인한다.
13. 장치 2: 비목표 울타리
비목표는 생각보다 훨씬 중요하다. 무엇을 할지보다 무엇을 하지 않을지를 먼저 적어두면, AI가 그럴듯한 확장 제안을 해도 현재 반복을 지킬 수 있다.
이번 버전에서 하지 않을 것:
- 인증 전체 재설계
- 결제 연동
- 관리자 화면
- 새 프레임워크 도입
- 대규모 리팩터링어디에 두나:
feature-spec.md의Non-goalsAGENTS.md의Do not- 이슈/태스크 본문의 범위 섹션
개발자 팁:
- "안 한다"는 문장은 기술적으로 적는다
- 예:
auth schema change 금지,new dependency 추가 금지 - diff가 넓어질수록 비목표를 더 구체적으로 적는다
강의에서 쓰는 체크:
AI가 계획에 없는 파일을 열거나 새 패키지를 제안하면, 먼저 Non-goals와 충돌하는지 확인한다.
14. 장치 3: 성공 기준
완료를 감으로 판단하면, AI도 사람도 "대충 된 것 같은 상태"를 완료로 착각하기 쉽다. 성공 기준은 완료를 기능이 아니라 관찰 가능한 상태로 바꾸는 장치다.
- 사용자는 [행동]을 할 수 있다
- empty/loading/error/success 상태가 보인다
- 테스트 명령이 통과한다
- 민감정보가 로그에 남지 않는다어디에 두나:
feature-spec.md의Acceptance Criteriatest-plan.md의 시나리오 목록- PR 템플릿의 체크리스트
개발자 팁:
- UI는 상태 4종을 기본값으로 본다
- API는 성공/실패 응답과 에러 메시지 형식을 같이 적는다
- "빠르다" 대신
p95 2초 이하처럼 측정 가능한 문장으로 바꾼다
강의에서 쓰는 체크:
성공 기준 하나마다 테스트, 수동 QA, 로그 확인 중 최소 하나의 검증 방법이 연결되어야 한다.
15. 장치 4: 컨텍스트 팩
AI는 많이 안다고 무조건 잘하지 않는다. 오히려 무엇이 현재 진실인지 좁고 명확하게 주어졌을 때 더 안정적으로 작동한다. 그래서 컨텍스트 팩은 "많이 넣기"보다 "정확히 넣기"가 핵심이다.
최소 세트:
README.mdAGENTS.md또는CLAUDE.mdfeature-spec.mdtest-plan.md- 변경 가능 파일 목록과 금지 구역
어디에 두나:
- 루트:
README.md,AGENTS.md - 기능 폴더:
docs/feature-spec.md,docs/test-plan.md - 긴 세션용:
handoff.md,known-failures.md
개발자 팁:
- 전체 저장소를 한 번에 넣지 않는다
- 긴 로그는 스크립트로 요약한 뒤 일부만 넣는다
allowed files,forbidden files를 명시하면 엉뚱한 수정이 줄어든다
권장 폴더:
docs/ai/
feature-spec.md
test-plan.md
risk-log.md
handoff.md16. 장치 5: 계획 리뷰 게이트
코딩 전에 계획을 먼저 공격하는 단계가 필요하다. 여기서의 목적은 멋진 설계를 칭찬하는 것이 아니라, 아직 코드가 없을 때 값싸게 틀린 점을 찾는 것이다.
- 제품 리뷰어: 정말 이 문제가 맞는가
- 기술 리뷰어: 범위와 구조가 과한가
- 보안 리뷰어: 민감정보, 권한, 비용 폭주 위험이 있는가
- 단순화 리뷰어: 지금 더 작게 만들 수 있는가
어디에 두나:
plan.md또는 이슈 본문에Review Questions- PR 생성 전 체크리스트
- 팀이면 design review 코멘트 템플릿
개발자 팁:
- 이 단계에서는 코드 작성 금지
- 질문 예시:
왜 이 파일을 만져야 하나?,더 작은 diff로 쪼갤 수 있나? - plan review를 통과한 뒤에만 implementation prompt를 만든다
강의에서 쓰는 체크:
좋은 계획은 "무엇을 바꾸는지"뿐 아니라 "무엇을 절대 건드리지 않는지"를 같이 말한다.
17. 장치 6: 검증 하네스
빠르게 만들수록 검증은 더 자동화되어야 한다. 사람이 매번 감으로 확인하면, 속도가 올라갈수록 실수도 같이 빨라진다.
최소 검증:
- unit test
- lint
- typecheck
- build
- 수동 QA 체크리스트
고위험 기능 추가 검증:
- integration test
- secrets scan
- dependency vulnerability scan
- 권한 케이스 테스트
어디에 두나:
package.jsonscripts 또는Makefile.github/workflows/ci.ymldocs/test-plan.md
개발자 팁:
- 최소한
test,lint,typecheck,build명령은 한 번에 보이게 한다 - 브랜치 보호가 가능하면 CI 통과 전 병합 금지
- QA는 "눌러본다"가 아니라 시나리오 문장으로 남긴다
설정 예시:
{
"scripts": {
"verify": "npm run lint && npm run typecheck && npm test && npm run build"
}
}18. 장치 7: 메모리 업데이트
바이브 코딩이 반복될수록 중요한 것은 "이번 세션에서 배운 것을 다음 세션이 잊지 않게 만드는 일"이다. 세션은 끊기고, 사람도 맥락을 잊고, 모델도 오래된 판단과 새 판단을 혼동한다.
매 반복 후 남겨야 할 것:
- 결정한 규칙
- 실패한 패턴
- 테스트 명령
- 금지 구역
- 다음 세션 주의사항
어디에 두나:
AGENTS.md의 team ruleshandoff.md의 next session summaryknown-failures.md또는risk-log.md
개발자 팁:
- 길게 쓰지 말고 다음 세션 첫 5분을 줄여주는 정보만 남긴다
- "뭘 했는가"보다 "다음엔 뭘 조심해야 하나"를 적는다
- 장시간 작업일수록 compaction보다 handoff 파일이 더 중요해진다
handoff 최소 형식:
Done:
Next:
Do not touch:
Failed attempts:
Verify command:19. 바이브 기획 운영체계 개요
좋은 바이브 기획은 예쁜 문서 묶음이 아니라, 구현 전에 생각을 점점 더 구체적인 형식으로 압축해가는 과정이다. 개발자 워크숍에서는 이것을 "아이디어를 커밋 가능한 작업 계약으로 바꾸는 과정"이라고 설명한다.
핵심은 "생각 -> 스펙 -> 실행 계약"으로 점점 좁혀가는 데 있다.
flowchart LR A["Idea"] --> B["Problem"] B --> C["PR/FAQ"] C --> D["PRD"] D --> E["Agent Spec"] E --> F["Task Breakdown"] F --> G["Test Plan"] G --> H["Risk Review"] H --> I["Implementation Prompt"]
flowchart LR
A["Idea"] --> B["Problem"]
B --> C["PR/FAQ"]
C --> D["PRD"]
D --> E["Agent Spec"]
E --> F["Task Breakdown"]
F --> G["Test Plan"]
G --> H["Risk Review"]
H --> I["Implementation Prompt"]- 앞단은 방향을 정한다
- 중간은 범위와 작업 단위를 정한다
- 뒷단은 구현과 검증 계약을 만든다
레포에 남는 산출물:
docs/ai/feature-spec.md -> docs/ai/test-plan.md -> .ai/tasks/*.md -> PR
20. PR/FAQ
PR/FAQ는 제품 설명서이면서 동시에 사고 실험 도구다. 개발자에게 특히 유용한 이유는, 구현 전에 "이 기능이 왜 존재해야 하는지"를 한 번 고객 언어로 번역하게 만들기 때문이다.
포함 항목:
- 대상 사용자
- 해결되는 문제와 사용 전/후 변화
- 가치 제안
- 자주 묻는 질문
- 내부 우려와 반론
좋은 PR/FAQ는 팀을 설득하기 위한 문서가 아니라, 스스로를 설득해보는 장치다.
개발자용 변환:
PR/FAQ의 FAQ 항목은 나중에 edge cases, error states, support questions로 바뀐다.
21. PRD
PRD는 구현 지시서라기보다 판단 기준서에 가깝다. 길이가 중요한 것이 아니라, 팀과 AI가 같은 기준으로 "무엇이 맞는 구현인가"를 이해하게 만드는 것이 중요하다.
GitHub Spec Kit의 메시지는 개발자에게 아주 직접적이다.
"Focus on the what and why, not the tech stack." — GitHub Spec Kit
이 말의 의미:
초보 개발자는 AI에게 곧바로 "React로 만들어줘", "FastAPI로 짜줘"라고 말하기 쉽다. 하지만 좋은 PRD는 먼저 무엇을 왜 만드는지 고정한다. 기술 선택은 그 다음이고, 요구사항이 흔들리면 어떤 스택을 써도 구현은 흔들린다.
필수 항목:
- 문제 정의
- 목표와 비목표
- 사용자 시나리오
- 기능 요구사항
- 비기능 요구사항
- 성공 지표
- 리스크
- 오픈 질문
핵심은 요구사항을 많이 쓰는 것이 아니라, 추측하면 안 되는 부분을 분명히 쓰는 것이다.
개발자용 최소 PRD:
Problem
Goals / Non-goals
User flow
Acceptance criteria
Data / API contract
Risks
Open questions22. Agent Spec
사람용 문서와 에이전트용 문서는 다르다. 사람은 빈칸을 적당히 메우지만, 에이전트는 그 빈칸을 잘못 채우기 쉽다. 그래서 에이전트용 스펙은 특히 경계와 금지 구역이 중요하다.
에이전트용 스펙 필수 항목:
- 기술 스택
- 변경 범위
- 변경 금지 범위
- API 계약
- 데이터 모델
- 에러 처리
- 테스트 명령
- 완료 조건
좋은 Agent Spec은 창의성을 줄이는 문서가 아니라, 잘못된 자유도를 줄이는 문서다.
강의에서 강조하는 문장:
에이전트에게는 "원하는 결과"만 주지 말고, "건드리면 안 되는 표면"을 같이 준다.
23. Task Breakdown
큰 기능을 한 번에 맡기면 결과가 화려해 보일 수는 있어도, 흔들렸을 때 되돌리기 어려워진다. 그래서 태스크는 작고 리뷰 가능한 diff 단위로 끊는 편이 안정적이다.
좋은 태스크의 조건:
- 리뷰 가능한 diff 크기
- 되돌리기 쉬움
- 테스트 기준이 명확함
- 의존성이 적음
- 완료 조건이 관찰 가능함
예시:
- 나쁜 태스크:
사용자 인증 전체 구현 - 좋은 태스크:
로그인 폼 UI만 생성
실무 기준:
한 태스크는 가능하면 하나의 PR, 하나의 테스트 계획, 하나의 롤백 판단으로 끝나야 한다.
24. Test Plan
테스트는 구현 뒤에 붙이는 장식이 아니다. 무엇을 검증할지를 먼저 적어두면, AI가 코드를 만들 때도 어디까지 책임져야 하는지 더 잘 이해한다.
포함 항목:
- 정상 케이스
- 경계값
- 실패 케이스
- 권한 케이스
- 데이터 없음 상태
- 회귀 테스트
- 수동 QA 시나리오
테스트 계획이 약하면 구현은 빨라도, 결과 판단이 계속 감각 싸움이 된다.
개발자용 규칙:
acceptance criteria 하나에 최소 하나의 test 또는 manual QA step을 연결한다.
25. Risk Review
실패 비용이 큰 영역은 구현 전에 따로 멈춰서 보는 단계가 필요하다. 여기서의 질문은 "할 수 있나"가 아니라 "지금 이 방식으로 해도 되나"이다.
구현 전 확인:
- 개인정보가 들어가는가
- 권한 경계가 바뀌는가
- 외부 API 비용이 폭주할 수 있는가
- 롤백이 가능한가
- 로그와 프롬프트에 민감정보가 남는가
이 단계가 있으면 속도가 조금 느려지는 대신, 뒤에서 큰 사고를 줄일 수 있다.
26. Implementation Prompt
좋은 구현 요청은 전체 세계를 다시 설명하지 않는다. 승인된 계획 안에서 지금 맡길 1단계만 명확히 잘라서 주는 편이 결과가 안정적이다.
승인된 계획의 1단계만 구현해줘.
- 관련 없는 리팩터링 금지
- 새 라이브러리 추가 금지
- 변경 파일은 목록 안으로 제한
- 완료 후 검증 결과를 보고- 구현 단계에서 요구사항을 다시 바꾸지 않는다
- 계획과 구현 프롬프트를 분리하면 오류 원인을 추적하기 쉬워진다
- 작은 구현 지시는 작은 diff와 연결되기 쉽다
강의에서 쓰는 원칙:
implementation prompt는 스펙 문서가 아니라 실행 티켓이다. 내용이 길어지면 태스크가 너무 큰 것이다.
27. 바이브 코딩 실행 루프 개요
바이브 코딩은 감으로 툭툭 던지는 대화처럼 보일 수 있지만, 실제로 안정적인 결과를 내려면 반복 루프가 있어야 한다.
중요한 것은 루프의 속도보다 루프의 질이다.
flowchart LR A["Explore"] --> B["Plan"] B --> C["Review Plan"] C --> D["Implement Small"] D --> E["Verify"] E --> F["Explain Diff"] F --> G["Human Review"] G --> H["Document Learnings"]
flowchart LR
A["Explore"] --> B["Plan"]
B --> C["Review Plan"]
C --> D["Implement Small"]
D --> E["Verify"]
E --> F["Explain Diff"]
F --> G["Human Review"]
G --> H["Document Learnings"]- 앞단은 이해
- 중간은 실행
- 뒷단은 검증과 기억
개발자용 해석:
이 루프는 사실상 read code -> propose diff -> run verify -> explain diff -> update docs의 반복이다.
28. Explore
첫 프롬프트에서 바로 구현하지 않는 습관이 중요하다. 먼저 현재 코드와 규칙을 탐색하게 하면, AI가 자기 마음대로 패턴을 발명할 가능성을 줄일 수 있다.
먼저 물어볼 것:
- 관련 파일은 무엇인가
- 현재 구현 패턴은 무엇인가
- 비슷한 기능은 어디에 있는가
- 테스트는 어디에 있는가
- 위험한 영역은 무엇인가
탐색 단계가 짧더라도 생략하지 않는 편이, 뒤에서 고치는 시간보다 보통 더 싸다.
강사라면 이렇게 시킨다:
관련 파일을 읽고, 기존 패턴과 테스트 위치만 보고해줘. 아직 코드는 수정하지 마.
29. Plan
탐색이 끝나면 바로 구현이 아니라, 구현 계획만 먼저 받는다. 이때 계획은 글솜씨가 아니라 작업 계약이다.
포함 항목:
- 목표
- 비목표
- 변경 파일
- 단계별 작업
- 테스트 계획
- 리스크
- 롤백 방법
좋은 계획은 읽는 순간 "어디까지가 이번 일인지"가 분명해야 한다.
계획에서 반드시 보여야 하는 것:
files to change, files not to touch, verify command, rollback plan
30. Review Plan
코드 리뷰보다 계획 리뷰가 먼저다. 이 단계에서 계획을 공격적으로 검토하면, 구현 이후에 생길 큰 재작업을 미리 줄일 수 있다.
검토 기준:
- 요구사항 누락
- 애매한 성공 기준
- 과한 설계
- 보안 리스크
- 테스트 부족
- 더 작게 나눌 수 있는지
실무에서는 여기서 10분 더 쓰는 것이, 뒤에서 두 시간 디버깅하는 것보다 훨씬 이득인 경우가 많다.
리뷰 질문:
이 변경은 더 작게 쪼갤 수 있는가?테스트 없이 믿어야 하는 부분은 어디인가?
31. Implement Small
한 번에 하나의 작은 태스크만 구현하는 이유는 단지 관리가 편해서가 아니다. 작은 구현은 실패했을 때 원인을 찾기 쉽고, 성공했을 때 무엇이 효과 있었는지도 명확하다.
원칙:
- 관련 없는 리팩터링 금지
- 새 라이브러리 추가는 승인 후
- 테스트를 함께 추가
- 한 번에 한 태스크만 수행
효과:
- 리뷰 가능성이 올라간다
- 롤백 비용이 내려간다
- 다음 반복의 계획 품질도 올라간다
32. Verify
AI에게도 "검증 결과를 보고하라"고 명시적으로 요구해야 한다. 구현만 하게 하면, 모델은 보통 통과 여부보다 생성 완료 자체를 더 중요하게 취급하기 쉽다.
1. 테스트, 린트, 타입체크 실행
2. 실패 원인 분석
3. 수정 전 계획 설명
4. 수정 후 재실행
5. 최종 통과/실패 항목 보고- 실패한 명령과 남은 리스크를 숨기지 않게 한다
- 자동화 검증과 수동 확인을 모두 결과물에 묶는다
- "왜 이게 아직 불안한가"도 함께 기록하게 만든다
강의에서 쓰는 기본 명령:
npm run verify33. Explain Diff
사람이 설명할 수 없는 diff는 결국 팀과 미래의 나를 괴롭힌다. 그래서 구현 후에는 AI가 무엇을 왜 바꿨는지 다시 말로 설명하게 만드는 단계가 필요하다.
AI에게 설명시킬 것:
- 변경 파일별 목적
- 요구사항과 연결되는 부분
- 테스트가 검증하는 것
- 남은 리스크
- 롤백 방법
이 단계는 단순 보고서가 아니라 이해도 확인 장치다. 설명이 흐리면, 구현도 어딘가 흐릴 가능성이 높다.
34. Human Review
마지막 결정권은 여전히 사람에게 있다. 특히 프로덕션 코드에서는 "동작한다"보다 "우리가 이 변경을 이해하고 책임질 수 있는가"가 더 중요하다.
사람이 마지막으로 확인할 질문:
- 내가 이 diff를 설명할 수 있는가
- 요구사항을 충족하는가
- 불필요한 변경이 없는가
- 예외 처리가 되었는가
- 테스트가 진짜 요구사항을 검증하는가
사람 리뷰는 AI를 불신하기 위한 절차가 아니라, 책임 경계를 명확히 하는 절차다.
35. Document Learnings
반복이 끝날 때마다 학습 내용을 문서화하면, 다음 세션의 품질이 좋아진다. 특히 장시간 작업에서는 세션이 새로 시작될 때 이 자산이 엄청난 차이를 만든다.
남기면 좋은 문서:
AGENTS.mdfeature-spec.mdtest-plan.mdrisk-log.mdknown-failures.md
이유:
다음 세션이 새로 시작돼도 같은 실수를 반복하지 않게 하기 위해서다. 문서화는 느린 일이 아니라, 재시작 비용을 줄이는 일이다.
36. 계획 변경 통제의 원칙
사용자 질문 중 가장 자주 나오는 것이 이것이다. 계획 변경은 한 번에 몰아서 해야 하는가, 아니면 생각날 때마다 즉시 반영해야 하는가. 답은 둘 다 아니다.
원칙:
- 아이디어는 실시간 수집
- 결정은 반복 끝에서 정리
- 구조와 기준을 흔드는 큰 변경은 즉시 재계획
flowchart TD
A["새 변경 아이디어"] --> B{"현재 목표에 직접 필요한가?"}
B -- "No" --> C["Parking Lot에 기록"]
B -- "Yes" --> D{"구조/API/테스트 영향이 큰가?"}
D -- "No" --> E["현재 반복 안에서 반영"]
D -- "Yes" --> F["즉시 재계획"]
flowchart TD
A["새 변경 아이디어"] --> B{"현재 목표에 직접 필요한가?"}
B -- "No" --> C["Parking Lot에 기록"]
B -- "Yes" --> D{"구조/API/테스트 영향이 큰가?"}
D -- "No" --> E["현재 반복 안에서 반영"]
D -- "Yes" --> F["즉시 재계획"]37. Parking Lot 방식
수정 충동은 나쁜 것이 아니다. 다만 그 충동이 현재 태스크를 매번 흔들어버리면, 결국 아무것도 깨끗하게 끝나지 않는다. Parking Lot은 이 충동을 버리지 않고 보관하는 장치다.
아이디어:
왜 바꾸고 싶은가:
지금 안 바꾸면 생기는 문제:
지금 바꾸면 깨질 수 있는 것:
현재 목표와 직접 관련 있는가:
처리 결정: 지금 / 다음 반복 / 폐기- 즉흥적 아이디어를 기록으로 바꾼다
- 현재 목표를 지키면서도 나중의 개선점을 잃지 않는다
- 1인 개발자에게는 집중 유지 장치, 팀에는 변경 합의 장치가 된다
38. 즉시 재계획이 필요한 신호
모든 변경을 다음으로 미룰 수는 없다. 아래 신호가 보이면, 코드부터 만지지 말고 계획 문서부터 다시 열어야 한다.
- 데이터 모델 변경
- 인증/권한 경계 변화
- 테스트 기준 재정의
- 여러 파일로 범위 확장
- 이전 결정 무효화
한 문장 신호:
"앞에서 만든 것도 다시 손봐야 하는데?"가 나오면, 그건 구현 문제가 아니라 계획 문제일 가능성이 높다.
39. 컨텍스트와 토큰 관리

장시간 바이브 코딩이 무너지기 쉬운 핵심 이유 중 하나는 컨텍스트 관리 실패다. 짧은 실험에서는 프롬프트 품질이 크게 느껴지지만, 긴 작업에서는 전체 토큰 상태와 세션 구조가 훨씬 중요해진다.
Addy Osmani의 표현을 빌리면, 큰 스펙을 그냥 던지는 방식은 잘 작동하지 않는다.
"Simply throwing a massive spec at an AI agent doesn't work" — Addy Osmani
이 말의 의미:
많은 정보를 한 번에 주는 것이 좋은 컨텍스트 설계는 아니다. 큰 스펙은 작은 태스크, 관련 파일, 검증 기준으로 나눠야 한다. AI에게는 저장 창고가 아니라 지금 작업할 작업대를 만들어줘야 한다.
- 도구 정의가 많아질수록 시작 비용이 커진다
- 긴 로그, 문서, 회의록이 그대로 들어오면 판단력이 흐려진다
- 오래된 실패 시도와 현재 진실이 같은 세션 안에 섞이면 품질이 떨어진다
핵심 해석:
context window는 저장 창고가 아니라 작업대에 가깝다. 작업대에는 지금 필요한 것만 올려야 한다.
40. 토큰을 아끼는 운영 규칙

토큰 절약은 비용 절감만의 문제가 아니다. 컨텍스트를 줄이면 대개 판단도 더 선명해진다. 공개 사례에서도 긴 작업은 "더 많은 정보"보다 "더 얇은 상태 관리"가 성능을 좌우했다.
운영 규칙:
- 처음부터 전체 저장소를 넣지 않는다
- 긴 데이터는 코드나 스크립트로 먼저 필터링한다
- 필요한 도구만 탐색해서 읽게 한다
- 세션 끝에는 handoff 파일을 남기고, 길어지면 새 세션으로 재시작한다
사례 요약:
Anthropic은 시스템 프롬프트도 너무 구체적이거나 너무 모호하면 둘 다 문제가 된다고 설명한다. 이 원리는 컨텍스트 설계 전체에도 똑같이 적용된다.
41. 1인 개발자 운영 모델
1인 개발자는 모든 역할을 혼자 맡기 때문에 더 자유롭지만, 동시에 더 쉽게 흔들린다. 그래서 스스로 planner, generator, evaluator 역할을 나눠서 운영하는 것이 중요하다.
- planner: 문제 프레임, 비목표, 성공 기준을 먼저 적는 나
- generator: 실제 구현을 AI와 함께 빠르게 만드는 나
- evaluator: 테스트, 체크리스트, diff 설명을 확인하는 나
핵심:
1인 개발자는 멀티에이전트 시스템이 없어도 문서와 루프로 역할 분리를 흉내낼 수 있다. 이 역할 분리만 해도 작업 품질이 크게 달라진다.
42. 1인 개발자 주간 리듬
혼자 일할 때 가장 무서운 것은 판단 피로다. 생각날 때마다 바로 바꾸는 식으로 가면, 주말이 끝났을 때 남는 것은 코드보다 미완성 의도가 되기 쉽다.
추천 리듬:
- 월: 문제 프레임, PR/FAQ, 우선순위 정리
- 화-수: 작은 태스크 단위 구현
- 목: 검증, 리팩터링 후보 분리, Parking Lot 정리
- 금: 회고, 메모리 업데이트, 다음 주 handoff 작성
이 리듬의 목적은 생산성을 꾸미는 것이 아니라, 변경 욕구가 시스템을 깨지 않게 받쳐주는 것이다.
43. 팀 운영 모델
팀에서는 개인의 즉흥성이 곧 협업 비용으로 번진다. 그래서 바이브 코딩을 도입하더라도 개인 플레이가 아니라, 공통 규약과 품질 게이트 안에서 움직이게 해야 한다.
팀 운영의 핵심 축:
- 공유 스펙: PR/FAQ, PRD, Agent Spec
- 작업 계약: 태스크 단위, 변경 파일 범위, 완료 조건
- 품질 게이트: 테스트, 리뷰, 보안 점검, 롤백 계획
- 상태 전달: PR 설명, runbook, handoff 파일
요약하면, 팀에서는 "누가 잘 쓰느냐"보다 "어떤 시스템 안에서 쓰느냐"가 더 중요하다.
44. 팀 역할 분담
AI가 들어와도 역할은 사라지지 않는다. 오히려 더 명확해진다. AI가 실행을 빨리 하는 만큼, 사람의 역할은 방향, 검증, 책임 경계를 선명하게 만드는 쪽으로 이동한다.
| 역할 | 주 책임 | AI와의 관계 |
|---|---|---|
| PM / 기획 | 문제 정의, 비목표, 성공 기준 | 추측할 빈칸을 줄인다 |
| Tech Lead | 구조, 범위, 변경 경계 | 구현 전략과 위험을 제어한다 |
| Engineer | 탐색, 구현, 검증 | 작은 diff로 실행한다 |
| Reviewer / QA / Security | 품질 게이트 | 마지막 신뢰 장치를 맡는다 |
좋은 팀은 AI를 잘 쓰는 사람 몇 명이 있는 팀이 아니라, AI 작업의 책임선을 공유하는 팀이다.
45. 사례 1: OpenAI Harness Engineering
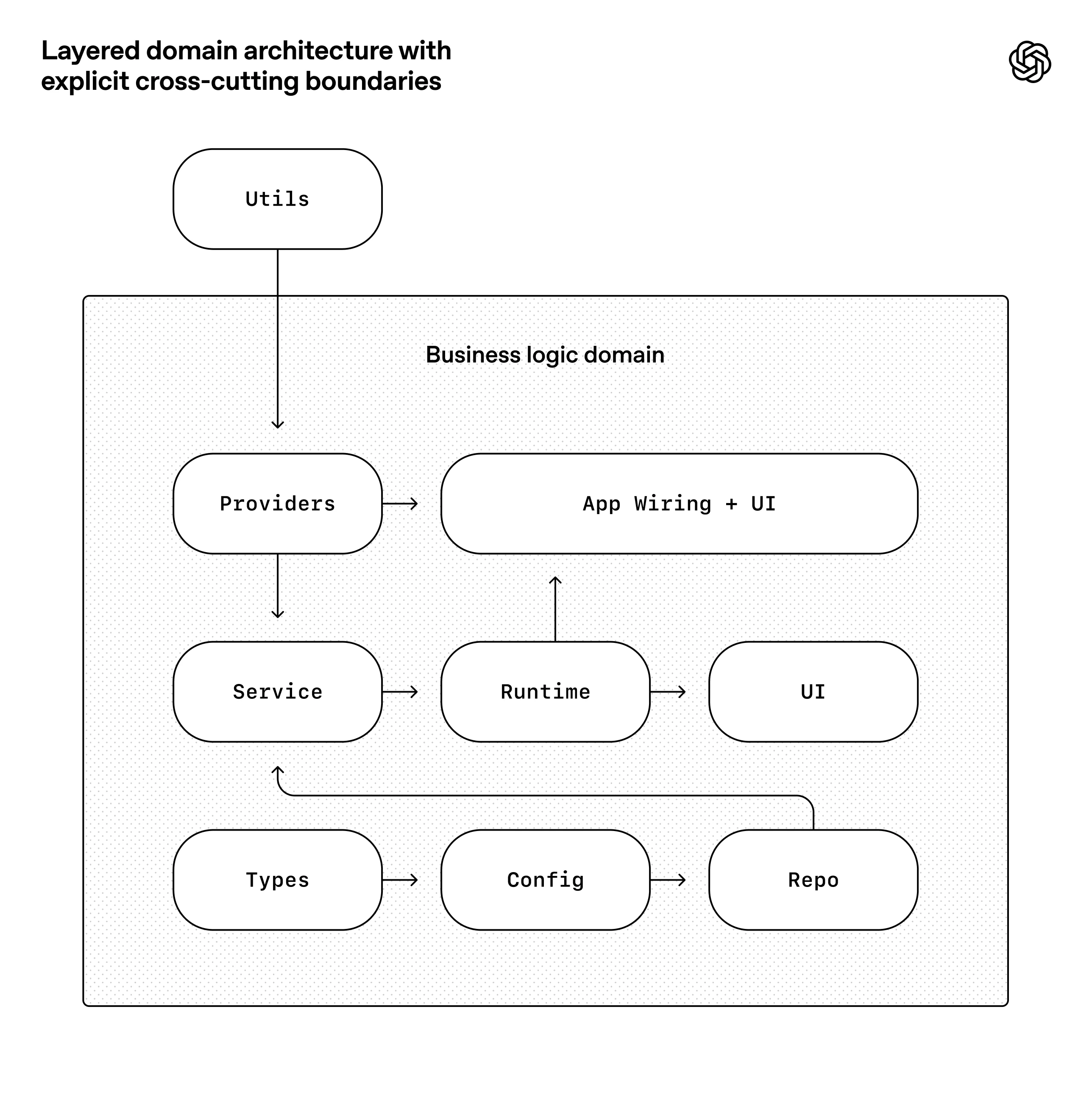
OpenAI는 내부 베타 제품을 사람의 직접 코딩보다 에이전트 중심으로 만드는 실험을 설명하며, 핵심 역량이 코드 작성에서 하네스 설계로 이동했다고 말한다. 여기서 중요한 것은 "AI가 다 했다"가 아니라, 사람이 어떤 환경을 만들어줬는가이다.
좋았던 점:
- 구현 속도가 매우 빨랐다
- 문서, 테스트, CI, 관측성까지 함께 생성할 수 있었다
- 사람은 방향과 제약 설계에 더 집중할 수 있었다
어려웠던 점과 교훈:
- 에이전트가 만든 시스템은 엔트로피가 빠르게 쌓인다
- 정리하지 않으면 오래된 결정과 쓰레기 맥락이 누적된다
- 결론적으로, 사람은 작성자보다 환경 디자이너이자 조향자 역할을 더 많이 맡게 된다
46. 사례 2: 검증 루프를 시스템에 넣는 법
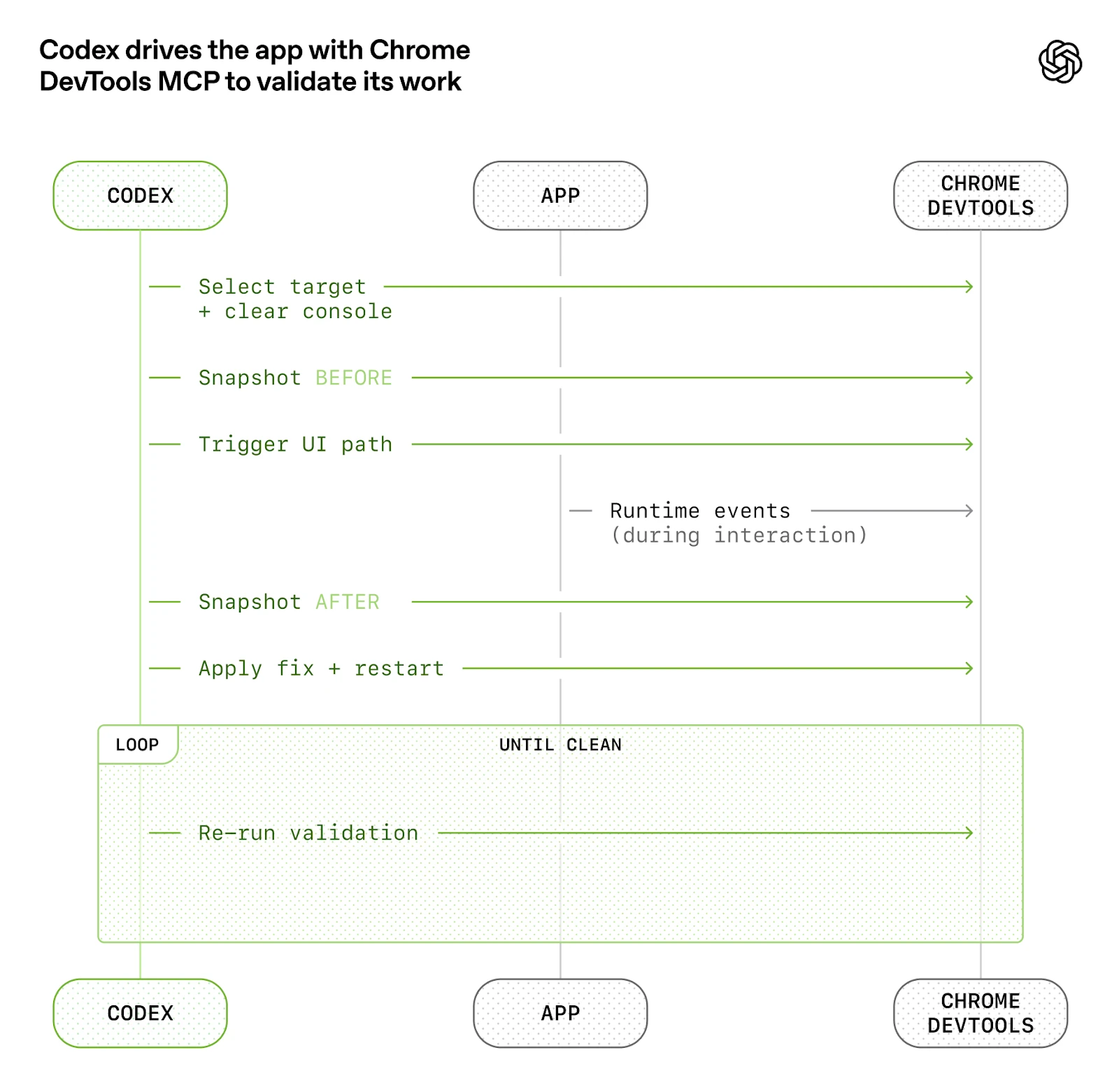
OpenAI가 공개한 이 그림은 "검증을 나중에 하는 일"이 아니라, 에이전트 루프 안에 직접 넣어야 한다는 사실을 잘 보여준다. 우리가 말한 planner -> generator -> evaluator 구조도 결국 같은 철학을 갖는다.
좋았던 점:
- 실행 전후 상태를 비교하는 구조가 명확하다
- 검증과 수정이 한 루프 안에 묶인다
- 사람이 잠든 동안에도 반복 품질 개선이 가능해진다
교훈:
- evaluator는 덧붙이는 옵션이 아니라 핵심 컴포넌트다
- UI, 로그, 테스트 결과를 에이전트가 읽을 수 있어야 품질 루프가 닫힌다
- 긴 작업은 큰 한 방이 아니라 작은 검증 루프의 연속이어야 한다
47. 사례 3: 멀티에이전트와 스펙 중심 개발
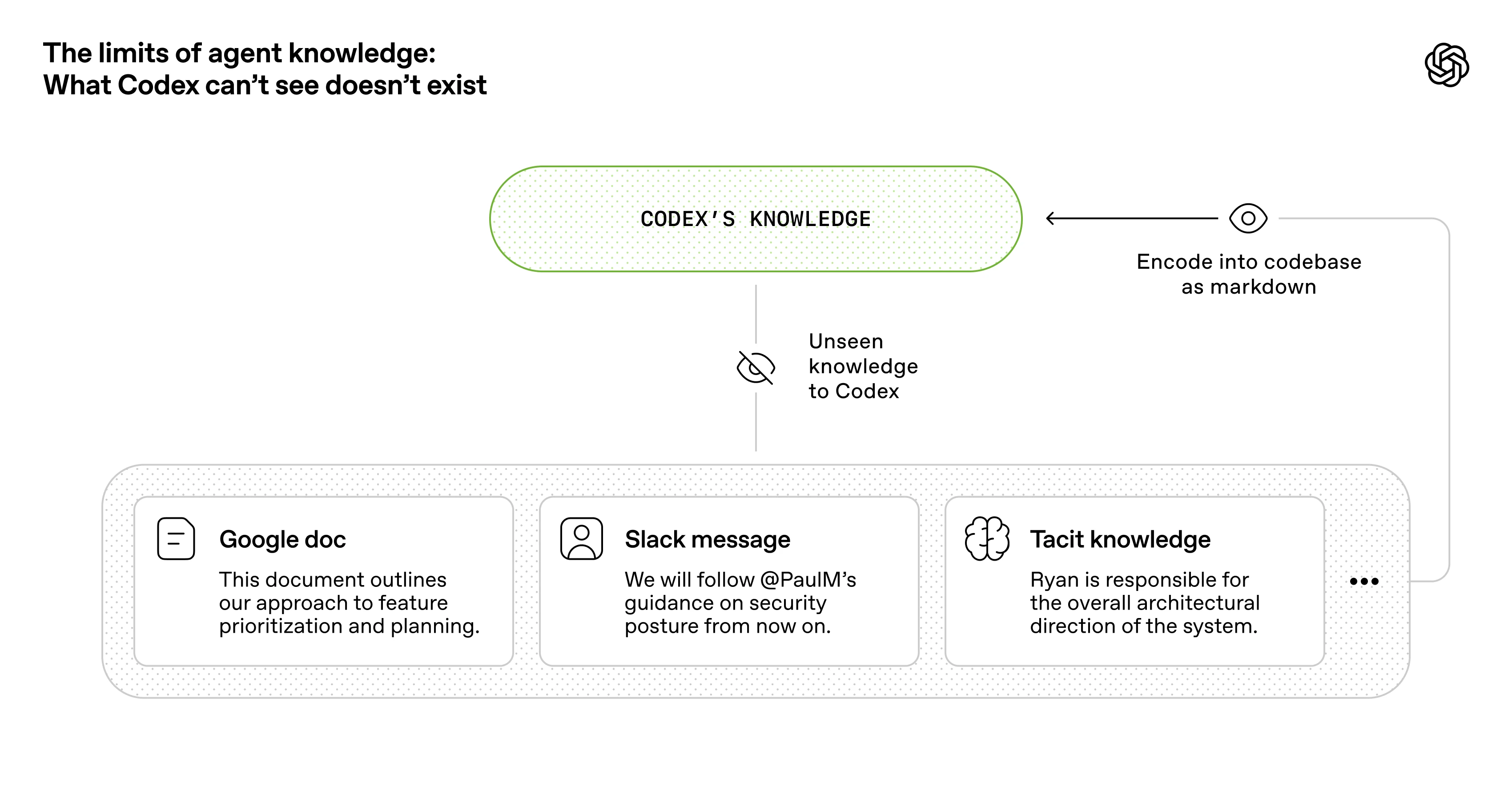
Anthropic의 멀티에이전트 연구 시스템과 GitHub의 spec-driven development 자료는, 분해 규칙과 스펙이 왜 필요한지를 다른 각도에서 보여준다. 위 그림의 핵심도 같다. 에이전트가 볼 수 없는 지식은 실제 운영에서 존재하지 않는 것과 비슷하다.
좋았던 점:
- 복잡한 문제를 병렬 탐색할 수 있다
- citation, evaluator 같은 역할 분리가 신뢰도를 높인다
- 스펙이 있으면 여러 사람이 같은 방향으로 움직이기 쉽다
나빴던 점과 교훈:
- 지시가 애매하면 하위 에이전트가 중복 작업을 반복한다
- 단순한 질문에 과도한 리소스를 쓰기 쉽다
- 멀티에이전트는 무조건 강력한 것이 아니라, effort scaling과 분해 규칙이 있을 때만 유용하다
48. 보안과 생산성 환상에서 벗어나기

AI가 속도를 올려준다고 해서, 자동으로 품질과 보안이 따라오는 것은 아니다. 공개 자료들은 오히려 더 섬세한 결론을 준다. 어떤 환경에서는 빨라지지만, 어떤 환경에서는 오히려 느려질 수 있고, 보안 사고는 경계 설계가 약할 때 더 쉽게 생긴다.
- OWASP LLM Top 10은 프롬프트, 데이터, 권한, 도구 사용의 새로운 위험을 지적한다
- 보안 취약점은 보통 "AI가 이상하게 코딩해서"보다 "사람이 경계를 설계하지 않아서" 생긴다
- GitHub Copilot 연구는 체감 생산성 향상을 보여줬지만, METR의 2025 오픈소스 개발자 연구는 특정 조건에서 오히려 작업 시간이 늘어날 수 있음을 보여줬다
결론:
속도 향상은 출발점일 뿐이다. 우리가 정말 관리해야 할 것은 코드 품질, 책임 범위, 검증 가능성, 그리고 장기 운영 비용이다. 그래서 생산성은 항상 "언제, 어떤 작업에서, 어떤 하네스로" 빨라졌는지까지 같이 봐야 한다.
49. 전체 출처
이 문서는 내부 코드명이 아니라, 외부 공개가 가능한 자료만 기준으로 재구성했다. 아래 묶음은 "정의", "운영", "기획", "보안", "생산성"을 따라 읽기 좋게 정리한 것이다.
정의와 경계:
- Andrej Karpathy, vibe coding 원문
- Simon Willison, Not all AI-assisted programming is vibe coding
- Simon Willison, not-vibe-coding 비판
운영과 하네스:
- OpenAI, Harness engineering
- Anthropic, Best practices for Claude Code
- Anthropic, Effective context engineering for AI agents
- Anthropic, Effective harnesses for long-running agents
- Anthropic, Harness design for long-running application development
- Anthropic, Code execution with MCP
- Anthropic, How we built our multi-agent research system
- Anthropic, Demystifying evals for AI agents
기획과 스펙:
- GitHub Blog, Spec-driven development with AI
- GitHub Spec Kit
- Addy Osmani, How to write a good spec for AI agents
- Marty Cagan, Product Discovery
- Working Backwards, PR/FAQ Process
보안과 생산성:
- OWASP Top 10 for LLM Applications
- Escape, LLM vulnerabilities and risks
- METR, Measuring AI Ability to Complete Long Tasks
- METR, Measuring the Impact of Early-2025 AI on Experienced Open-Source Developers
- METR, We are Changing our Developer Productivity Experiment Design
- GitHub, Quantifying GitHub Copilot's impact
- SWE-bench
'관심있는 주제' 카테고리의 다른 글
| 실시간 뉴스 클러스터링과 요약 시스템 설계: AWS 샘플에서 최신 이벤트 중심 분석까지 (3) | 2026.03.14 |
|---|---|
| React2Shell: React Server Components에서 발생한 치명적 RCE 취약점 정리 (0) | 2025.12.12 |
| EAI(Enterprise Application Integration) 간단하게 알아보기 (7) | 2025.07.29 |
| Context Engineering 알아보기 (12) | 2025.07.08 |
| Mary Meeker의 "AI" 트렌드 보고서 - 2025 (10) | 2025.06.06 |