2024. 7. 5. 15:57ㆍ관심있는 주제/LLM
SNS에서 요약된 내용과 이미지를 보고, 잘 정리가 되어있을 것 같아 정리해 보기로 하였습니다.
이 논문을 통해 현재 최신 RAG는 어떻게 하는 지 알아보고자 합니다.
논문 요약
- RAG의 효과성: 최신 정보를 통합하고, 오류를 줄이며, 특히 전문 분야에서 답변의 질을 높이는 데 효과적입니다.
- 현재 문제점: 많은 RAG 접근법이 복잡한 구현과 긴 응답 시간 문제를 가지고 있습니다.
- 연구 목적: 다양한 RAG 방법과 조합을 조사하여 성능과 효율성을 균형 있게 유지하는 최적의 RAG 방식을 찾는 것입니다.
- 멀티모달 검색: 시각적 입력에 대한 질문 답변 능력을 크게 향상시키고, “검색을 통한 생성” 전략을 통해 멀티모달 콘텐츠 생성을 가속화할 수 있습니다.
도입부
RAG란?
RAG는 컴퓨터가 질문에 답할 때, 최신 정보를 찾아와서 더 정확한 답변을 제공하도록 돕는 기술이에요. 이는 특히 전문 분야에서 유용하며, 정보가 오래되거나 잘못된 답변을 줄이는 데 도움을 줍니다.
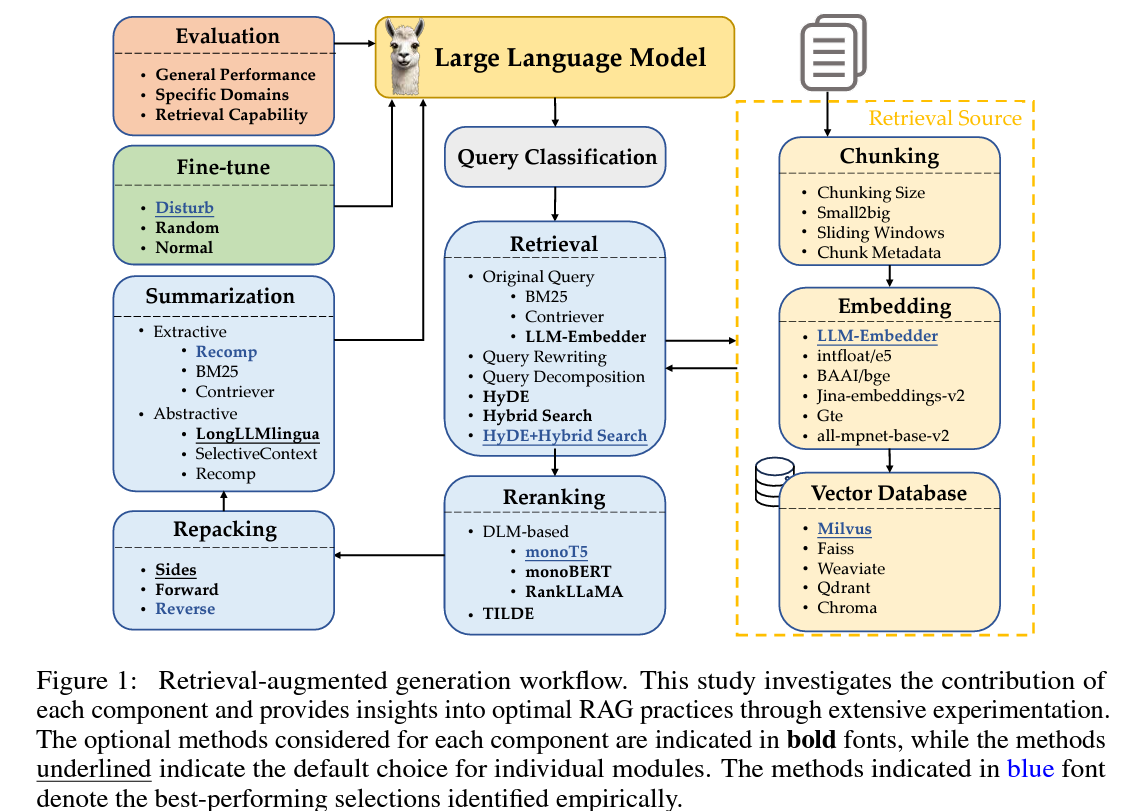
RAG의 주요 단계 (5단계)
- 쿼리 분류(Query Classification): 질문이 검색이 필요한지 결정해요.
- 정보 검색(Retrieval): 질문에 관련된 문서를 효율적으로 찾아요.
- 재랭킹(Reranking): 검색된 문서들의 중요도를 다시 정렬해요.
- 재포장(Repacking): 검색된 문서를 구조화된 형태로 정리해요.
- 요약(Summarization): 정리된 문서에서 핵심 정보를 추출해 답변을 만들어내요.
복잡성 해결 방법
RAG의 각 단계에서 다양한 방법을 사용할 수 있으며, 각 방법의 조합이 RAG 시스템의 효율성과 효과성에 큰 영향을 미칩니다. 이 연구에서는 가장 효율적인 방법을 찾기 위해 세 단계 접근 방식을 사용했습니다:
- 각 단계별로 대표적인 방법들을 비교해 최고 성능을 보이는 방법을 선택합니다.
- 선택된 방법을 통해 전체 RAG 성능에 미치는 영향을 평가합니다.
- 다양한 응용 시나리오에 적합한 최적의 조합을 탐구합니다.
관련 연구
정확한 답변의 중요성
큰 언어 모델(LLM)인 ChatGPT와 LLaMA는 종종 잘못된 정보를 생성하는 문제가 있습니다. 이를 해결하기 위해 RAG 기술이 사용됩니다. RAG는 외부 지식 기반에서 관련 문서를 검색하여, LLM이 보다 정확하고 최신의 맥락을 제공하도록 도와줍니다.
주요 기술
- 쿼리 및 검색 변환: 질문을 더 명확하고 상세하게 변환해 검색 성능을 향상시킵니다. 예를 들어, Query2Doc과 HyDE는 질문에서 가상 문서를 생성하여 검색 성능을 높입니다.
- 검색기 향상: 문서 조각화(Document chunking)와 임베딩 방법이 검색 성능에 중요한 영향을 미칩니다. 최적의 조각 크기를 결정하고, 관련 없는 문서를 필터링하는 것이 필요합니다.
- 미세 조정: RAG 시스템의 검색기와 생성기를 함께 미세 조정하여 전반적인 성능을 높입니다.
주요 기여
- RAG 방법 최적화: 다양한 RAG 접근법과 조합을 실험하여 최적의 방법을 제안합니다.
- 평가 프레임워크 제시: RAG 모델의 성능을 종합적으로 평가할 수 있는 평가 기준과 데이터셋을 소개합니다.
- 멀티모달 검색 기술: 시각적 입력에 대한 질문 답변 능력을 크게 향상시킵니다.

검색 요구 사항 분류 테이블
작업 종류검색 필요 여부세부 설명
정보의 충분성에 따른 방법
- 정보가 충분한 경우: 단순히 모델의 기능으로 해결 가능.
- 정보가 불충분한 경우: 외부 지식 기반에서 정보를 검색하여 해결 필요.
| Task | 검색 필요 여부 | 세부 설명 |
| 번역 (Translation) | 필요 없음 | 충분한 정보 제공: 예, "To be, or not to be"를 프랑스어로 번역 |
| 재작성 (Rewriting) | 필요 없음 | 충분한 정보 제공: 예, "Dave is attending his aunt's brother funeral" 재작성 |
| 추론 (Reasoning) | 필요 없음 | 충분한 정보 제공: 예, "Tom has three sisters, and each sister has a brother" 문제 해결 |
| 폐쇄형 질문 답변 (Closed QA) | 필요 없음 | 충분한 정보 제공: 예, Messi와 같은 축구 선수 식별 |
| 요약 (Summarization) | 필요 없음 | 충분한 정보 제공: 예, 르네상스에 대한 설명 요약 |
| 정보 추출 (Information Extraction) | 필요 없음 | 충분한 정보 제공: 예, ChatGPT의 소유 관계 제공 |
| 글 계속 작성 (Continuation Writing) | 필요 | 불충분한 정보 제공: 예, 워싱턴에 관한 문단 이어 쓰기 |
| 문맥 학습 (In-context Learning) | 필요 | 불충분한 정보 제공: 주어진 수학 문제 해결 |
| 검색 (Search) | 필요 | 배경 지식 필요: 예, "One Hundred Years of Solitude"만큼 유명한 소설 찾기 |
| 계획 (Planning) | 필요 | 배경 지식 필요: 예, 졸업 파티 계획 작성 |
| 의사결정 (Decision Making) | 필요 | 배경 지식 필요: 예, LA에서 뉴욕까지 가장 저렴한 이동 수단 선택 |
| 제안 (Suggestion) | 필요 | 배경 지식 필요: 예, 부모님을 설득하는 방법 |
| 질문 답변 (QA) | 필요 | 배경 지식 필요: 예, 다음 월드컵 개최 도시 찾기 |
| 역할 놀이 (Role-play) | 필요 | 배경 지식 불필요: 예, 컴퓨터 시스템 오류 해결 방법 |
| 글 작성 (Writing) | 필요 | 배경 지식 불필요: 예, 유럽 지리학에 관한 글 작성 |
이 표는 각 작업의 종류와 해당 작업이 검색이 필요한지 여부를 요약하여 제공합니다.
RAG 워크플로우 구성 요소
RAG(검색 보강 생성) 워크플로우는 여러 모듈로 구성됩니다.
각 모듈에 대해 자주 사용되는 접근법을 검토하고, 기본 및 대체 방법을 선택합니다. 아래는 각 모듈에 대한 설명입니다.
| 모듈 | 설명 | 방법들 |
| 쿼리 분류 (Query Classification) | 검색이 필요한지 여부를 판단합니다. | LLM 직접 처리 또는 RAG 모듈로 전환 |
| 검색 (Retrieval) | 관련 문서를 효율적으로 검색합니다. | 원본 쿼리, BM25, Contriever, LLM-Embedder 등 |
| 재랭킹 (Reranking) | 검색된 문서들의 중요도를 다시 정렬합니다. | monoT5, monoBERT, RankLLAMA, TILDE |
| 재포장 (Repacking) | 검색된 문서를 구조화된 형태로 정리합니다. | Sides, Forward, Reverse |
| 요약 (Summarization) | 정리된 문서에서 핵심 정보를 추출하여 답변을 생성합니다. | Extractive: Recomp, BM25, Contriever; Abstractive: LongLLMlingua 등 |
| 문서 조각화 (Chunking) | 문서를 작은 조각으로 나눕니다. | 조각 크기 설정, Small2Big, Sliding Windows 등 |
| 임베딩 (Embedding) | 문서 조각을 의미적으로 표현합니다. | LLM-Embedder, intfloat/e5, BAAI/bge 등 |
| 벡터 데이터베이스 (Vector Database) | 문서의 특징을 효율적으로 저장합니다. | Milvus, Faiss, Weaviate, Qdrant, Chroma 등 |
주요 포인트
1. 쿼리 분류(Query Classification)
쿼리 분류의 필요성
모든 쿼리가 RAG(검색 보강 생성)를 필요로 하지 않습니다.
RAG는 정보의 정확성을 높이고 오류를 줄일 수 있지만, 자주 검색하면 응답 시간이 길어질 수 있습니다.
따라서 쿼리를 분류하여 검색의 필요성을 판단합니다. 검색이 필요한 쿼리는 RAG 모듈을 통과하고, 그렇지 않은 쿼리는 LLM이 직접 처리합니다.
- 검색 필요 여부 판단
- 필요한 경우: 모델의 파라미터를 넘어서는 지식이 필요한 경우.
- 예: "Sora was developed by OpenAI" 번역은 LLM이 처리 가능하지만, 주제 소개는 검색 필요.
- 작업 분류: 15개의 작업을 충분한 정보 제공 여부에 따라 분류합니다. 사용자가 제공한 정보만으로 충분한 경우 검색이 필요 없고, 그렇지 않으면 검색이 필요합니다.
- 분류기 훈련: 쿼리 분류를 자동화하기 위해 분류기를 훈련합니다
- 필요한 경우: 모델의 파라미터를 넘어서는 지식이 필요한 경우.
- 오픈소스 모델에 대한 MPR 평가
- MRR (Mean Reciprocal Rank)
- 정의: MRR은 검색 시스템의 성능을 평가하는 지표입니다. 사용자 쿼리에 대한 검색 결과에서 정답이 몇 번째 순위에 나타나는지를 측정합니다.
- 계산 방식: 모든 쿼리에 대해 정답의 역순위를 평균 내어 계산합니다.
- 예를 들어, 정답이 1번째에 있으면 역순위는 1/1 = 1, 정답이 3번째에 있으면 역순위는 1/3 = 0.33입니다
- MRR (Mean Reciprocal Rank)
2. 문서 조각화 (Chunking)
조각화(Chunking)란?
문서를 더 작은 조각으로 나누는 것은 검색 정확성을 높이고 LLM의 길이 문제를 피하는 데 중요합니다. 다양한 수준에서 조각화가 가능합니다:
- 토큰 수준(Token-levelChunking): 간단하지만 문장을 나누어 검색 품질에 영향을 줄 수 있습니다.
- 의미 수준(Semantic-levelChunking): 문맥을 유지하지만 시간이 많이 소요됩니다.
- 문장 수준(Sentence-levelChunking): 텍스트의 의미를 보존하면서 단순함과 효율성을 균형 있게 유지합니다.
이 연구에서 사용한 방법
논문에서는 단순함과 의미 보존의 균형을 위해 Sentence-levelChunking 을선택했습니다.
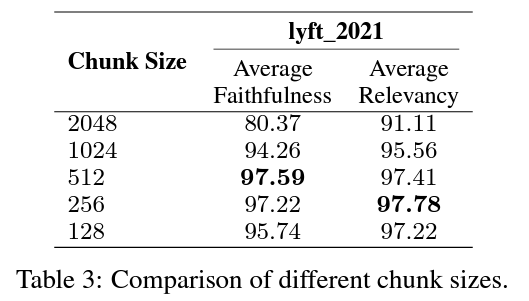
2.1 조각 크기 (Chunk Size)
크기의 영향: 조각 크기는 성능에 큰 영향을 미칩니다.
- 큰 조각: 더 많은 문맥 제공, 이해력 향상, 처리 시간 증가.
- 작은 조각: 검색 회수 향상, 처리 시간 단축, 문맥 부족 가능성.
최적의 조각 크기 찾기
균형 찾기: 성실성(답변이 환각이 아니고 검색된 텍스트와 일치하는지)과 관련성(검색된 텍스트와 답변이 쿼리와 일치하는지)을 고려합니다.
평가 방법: LlamaIndex의 평가 모듈을 사용하여 성능을 측정했습니다.
임베딩 모델: text-embedding-ada-0022.
생성 모델 및 평가 모델: zephyr-7b-alpha3와 gpt-3.5-turbo 사용.
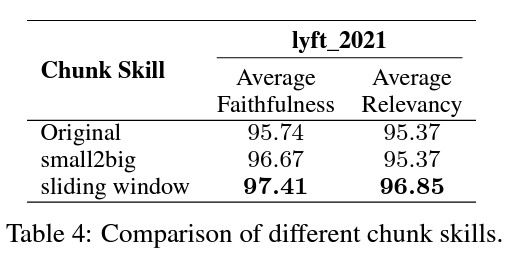
2.2 고급 조각화 기술(Adbanced Chunking)
고급 기술인 "small-to-big"과 "슬라이딩 윈도우"는 조각 블록 관계를 조직하여 검색 품질을 향상합니다.
- Small-to-Big: 작은 블록으로 쿼리를 매칭하고, 이 작은 블록과 문맥 정보를 포함한 큰 블록을 반환합니다.
- sliding window: 문맥을 유지하면서 관련 정보를 검색합니다.
실험 설정
- 임베딩 모델: LLM-Embedder.
- 조각 크기: 작은 조각은 175 토큰, 큰 조각은 512 토큰, 겹침은 20 토큰.
2.3 임베딩 모델 선택
임베딩 모델 선택의 중요성
효과적인 의미 매칭을 위해 적절한 임베딩 모델을 선택하는 것이 중요합니다.
쿼리와 조각 블록의 의미적 매칭을 위해 우리는 FlagEmbedding의 평가 모듈을 사용했습니다.
평가 데이터셋
쿼리 데이터셋: namespace-Pt/msmarco.
코퍼스 데이터셋: namespace-Pt/msmarco-corpus.
모델 비교 결과 (Table 2)
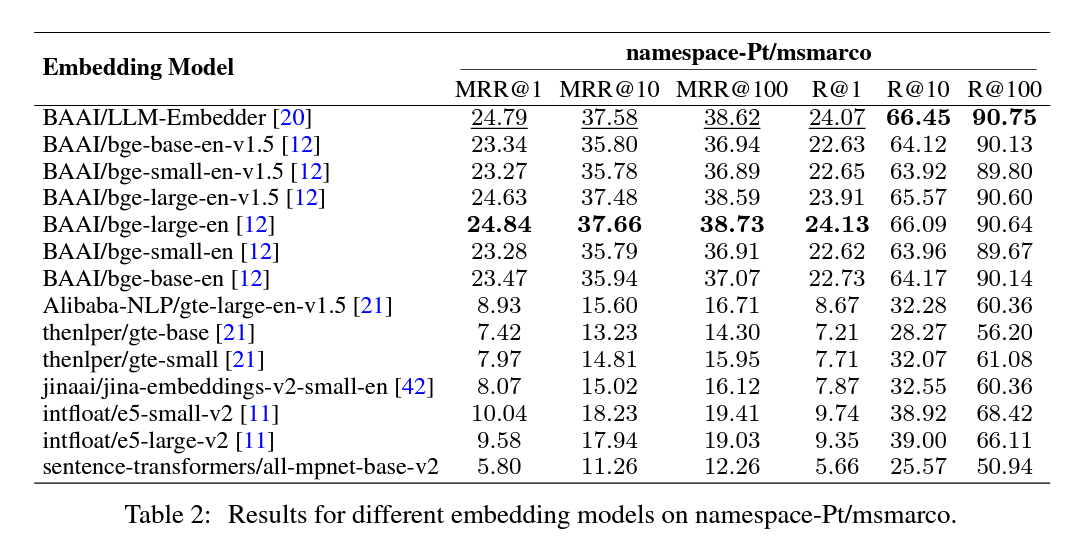
MRR@10: 상위 10개의 검색 결과에서 정답이 위치한 순위의 역수를 평균 내어 계산한 값입니다.
만약 두 쿼리에 대한 정답이 각각 2번째와 5번째에 위치한다면, MRR@10은 (1/2 + 1/5) / 2 = 0.3입니다.
- Namespace-Pt/msmarco
MS MARCO (Microsoft Machine Reading Comprehension) 데이터셋: 마이크로소프트가 만든 이 데이터셋은 질문 응답(task) 및 자연어 이해를 테스트하기 위해 만들어졌습니다. 실제 사용자 쿼리와 웹 문서로 구성되어 있으며, 질문에 대한 정답을 문서에서 찾아내는 것을 목표로 합니다.
메타데이터 추가의 중요성
조각 블록에 제목, 키워드, 가설 질문과 같은 메타데이터를 추가하면 검색 품질을 향상할 수 있습니다.
메타데이터는 검색된 텍스트를 후처리 하는 다양한 방법을 제공하며, LLM이 검색된 정보를 더 잘 이해하도록 돕습니다.
3. 벡터 데이터베이스(Vector Databases)
벡터 데이터베이스의 역할
벡터 데이터베이스는 임베딩 벡터와 메타데이터를 저장하여 쿼리에 관련된 문서를 효율적으로 검색할 수 있게 합니다.
다양한 인덱싱 및 근사 최근접 이웃(ANN) 방법을 사용하여 검색 효율성을 높입니다.
선택 기준
- 다양한 인덱스 유형 (Multiple Index Types): 다양한 데이터 특성 및 사용 사례에 최적화할 수 있습니다.
- 대규모 벡터 지원 (Billion-Scale Vector Support): 대용량 데이터셋을 처리할 수 있습니다.
- 하이브리드 검색 (Hybrid Search): 벡터 검색과 전통적인 키워드 검색을 결합하여 검색 정확도를 높입니다.
- 클라우드 네이티브 (Cloud-Native): 클라우드 환경에서의 통합, 확장성 및 관리가 용이합니다.
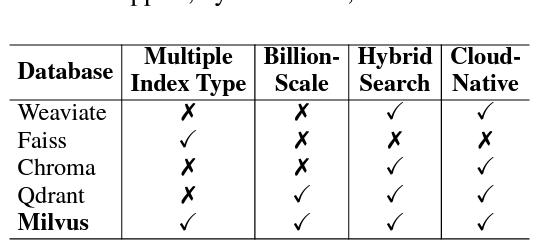
Milvus가 모든 필수 기준을 충족하며, 다른 오픈 소스 옵션보다 우수한 포괄적인 솔루션으로 평가되었습니다.
4. 검색 방법
검색 모듈의 역할
사용자 쿼리가 주어지면, 검색 모듈은 쿼리와 문서 간의 유사성에 따라 사전 구축된 코퍼스에서 상위 k개의 관련 문서를 선택합니다. 생성 모델은 이러한 문서를 사용해 적절한 응답을 만듭니다. 하지만 원본 쿼리는 표현 부족과 의미 정보의 부족으로 성능이 저하될 수 있습니다.
쿼리 변환 방법
- 쿼리 재작성 (Query Rewriting): 쿼리를 더 잘 매칭하도록 재작성합니다. Rewrite-Retrieve-Read 프레임워크에서 영감을 받았습니다.
- 쿼리 분해 (Query Decomposition): 원본 쿼리에서 파생된 하위 질문을 기반으로 문서를 검색합니다.
- 가상 문서 생성 (Pseudo-documents Generation): 사용자 쿼리를 기반으로 가상 문서를 생성하고, 이 가상의 응답 임베딩을 사용해 유사한 문서를 검색합니다. HyDE가 이 방법의 대표적인 구현입니다.
- 혼합 검색 방법
최근 연구에 따르면, 어휘 기반 검색과 벡터 검색을 결합하면 성능이 크게 향상됩니다. 이 연구에서는 BM25를 희소 검색, Contriever를 밀집 검색의 기준으로 사용합니다.
다양한 검색 방법의 결과
실험 결과 요약
TREC DL 2019 및 2020 데이터셋을 사용해 다양한 검색 방법의 성능을 평가했습니다.
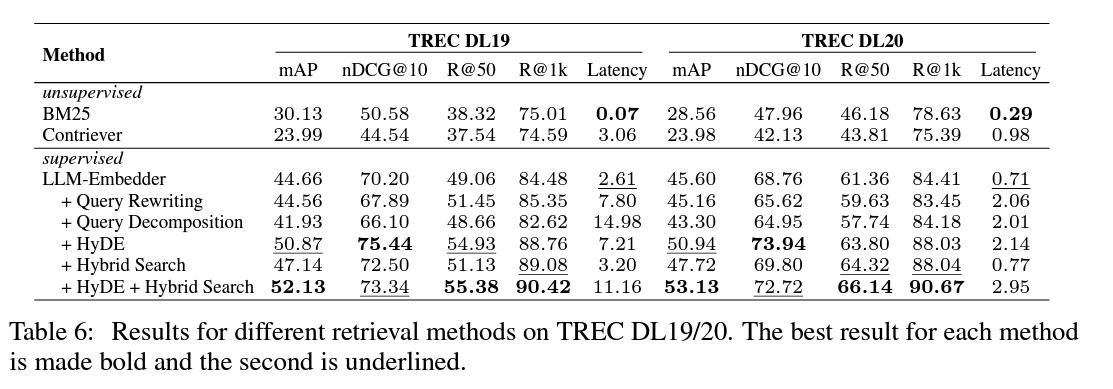
Table 6의 주요 결과
- 감독 학습 방법이 비감독 학습 방법보다 성능이 훨씬 우수합니다.
- LLM-Embedder를 HyDE와 혼합 검색(Hybrid Search)과 결합하면 최고 점수를 기록했습니다.
- 쿼리 재작성(Query Rewriting) 및 쿼리 분해(Query Decomposition)는 검색 성능을 크게 향상시키지 못했습니다.
권장 방법
혼합 검색(Hybrid Search)과 HyDE를 기본 검색 방법으로 권장합니다.
혼합 검색은 BM25(희소 검색)와 원본 임베딩(밀집 검색)을 결합하여 상대적으로 낮은 지연 시간으로 주목할 만한 성능을 발휘합니다.
혼합 검색에서 희소 검색 가중치의 영향
α 값은 희소 검색과 밀집 검색 간의 가중치를 조절합니다.
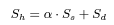
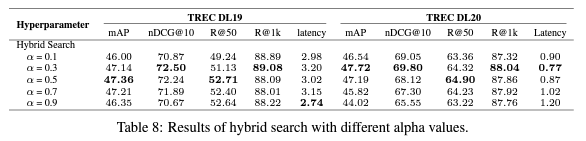
α 값 0.3이 최고의 성능을 보였습니다.
적절한 α 값 조정이 검색 효과를 향상시킬 수 있습니다.
S_a 는 희소 검색(sparse retrieval) , S_d 는 dense retrieval이라고 볼 수 있습니다.
5. 재랭킹 방법(RerankingMethods)
재랭킹의 목적
초기 검색 후, 재랭킹 단계를 통해 검색된 문서의 관련성을 높여 가장 관련성 높은 정보가 목록 상단에 나타나도록 합니다. 이 단계는 보다 정밀하고 시간이 많이 소요되는 방법을 사용하여 문서들을 효과적으로 재정렬합니다.
재랭킹 접근 방식
- DLM 재랭킹 (DLM Reranking):
딥 언어 모델(DLM)을 사용하여 문서의 관련성을 "참" 또는 "거짓"으로 분류합니다.
쿼리와 문서를 결합하여 모델을 미세 조정하고, 추론 시 "참" 토큰의 확률을 기반으로 문서를 재정렬합니다. - TILDE 재랭킹 (TILDE Reranking):
각 쿼리 용어의 확률을 독립적으로 예측하여 문서의 점수를 계산합니다.
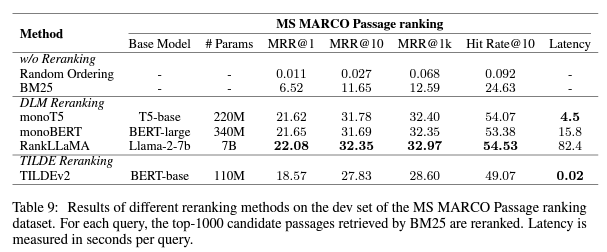
- 결론
- monoT5: 성능과 효율성의 균형.
- RankLLaMA: 최고의 성능.
- TILDEv2: 가장 빠른 재랭킹 경험 제공.
6. 문서 재포장(DocumentRepacking)
문서 재포장의 필요성
LLM 응답 생성 등의 후속 프로세스의 성능은 문서 제공 순서에 영향을 받을 수 있습니다.
이를 해결하기 위해 재랭킹 후 워크플로우에 콤팩트 재포장 모듈을 통합합니다.
재포장 방법
- Forward: 재랭킹 단계의 내림차순으로 문서를 재포장합니다.
- Reverse: 재랭킹 단계의 오름차순으로 문서를 배치합니다.
- Sides: 중요한 정보를 입력의 머리나 꼬리에 배치하는 방식입니다.
기본 재포장 방법
Sides 방법을 기본 재포장 방법으로 선택합니다. 이는 후속 모듈의 성능에 중요한 영향을 미칩니다.
7. 요약
요약의 필요성
검색된 결과에는 불필요하거나 중복된 정보가 포함될 수 있어, LLM이 정확한 응답을 생성하는 데 방해가 될 수 있습니다. 긴 프롬프트는 추론 과정을 느리게 하므로, 효율적인 요약 방법이 RAG 파이프라인에 중요합니다.
요약 방법
- 추출적 요약(extractive): 텍스트를 문장 단위로 나누고 중요도에 따라 점수화하여 순위를 매깁니다.
- 추상적 요약(abstractive): 여러 문서에서 정보를 종합하여 새로운 문장으로 재구성합니다.
Query-based 요약 방법
- Recomp: 유용한 문장을 선택하고, 정보를 종합하여 요약합니다.
- LongLLMLingua: 쿼리와 관련된 중요한 정보에 집중합니다.
- SelectiveContext: 입력 문맥에서 중복된 정보를 제거합니다.
비교 결과 (Table 10)
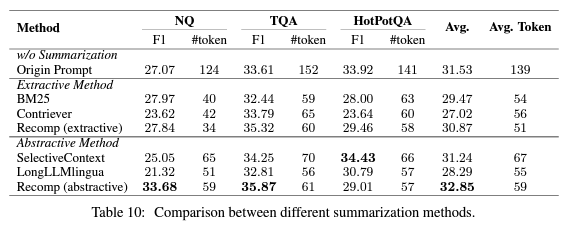
- Recomp: 가장 우수한 성능을 보임.
- LongLLMLingua: 데이터셋에 훈련되지 않았음에도 불구하고 좋은 일반화 능력을 보임.
- 권장 방법
- Recomp: 기본 요약 방법으로 추천.
- LongLLMLingua: 대체 방법으로 고려.
8. 세부 조정 방법 (Fine-Tuning) 및 결과(Generator Fine-tuning)
목표
- 생성기를 미세 조정하여 관련 또는 무작위 문맥이 성능에 미치는 영향을 조사합니다.
설정
- 쿼리(x)와 문맥(D):
- Dg: 관련 문서만 포함
- Dr: 무작위 문서 포함
- Dgr: 관련 문서와 무작위 문서 포함
- Dgg: 동일한 관련 문서 두 개 포함
모델
- Mb: 미세 조정되지 않은 기본 모델
- Mg, Mr, Mgr, Mgg: 각각 Dg, Dr, Dgr, Dgg로 미세 조정된 모델
결과
- Mgr이 가장 우수한 성능을 보임.
- 혼합 문맥을 사용한 훈련이 생성기의 강인성과 효율성을 증대시킴.
결론
- 관련 문서와 무작위 문서를 혼합하여 문맥을 확장하는 것이 가장 효과적임.
자세한 데이터셋 정보, 하이퍼파라미터 및 실험 결과는 부록 A.5에서 확인할 수 있습니다.
최적 RAG 구현 방법 탐색
목표
RAG 구현을 위한 최적의 방법을 조사합니다. 이를 위해 각 모듈에 대해 Section 3에서 확인된 기본 방법을 사용했습니다.
워크플로우 최적화
- 워크플로우를 따라 각 모듈을 순차적으로 최적화하고, 대안 중 가장 효과적인 옵션을 선택했습니다.
- 최종 요약 모듈을 구현하기 위한 최적의 방법을 결정할 때까지 이 반복 과정을 계속했습니다.
구체적인 설정
- 생성기 모델: Llama2-7B-Chat 모델을 사용하여 각 쿼리를 몇 개의 무작위로 선택된 관련 문서로 보강했습니다.
- 벡터 데이터베이스: Milvus를 사용하여 1천만 개의 영어 위키피디아 텍스트와 4백만 개의 의료 데이터를 포함했습니다.
- 모듈 영향 조사: 쿼리 분류, 재랭킹, 요약 모듈을 제거하여 각각의 기여도를 평가했습니다.
주요 발견
- 쿼리 분류, 재랭킹, 요약 모듈은 RAG 성능에 중요한 역할을 합니다.
- 문서와 쿼리를 혼합하여 문맥을 확장하는 방법이 가장 효과적입니다.
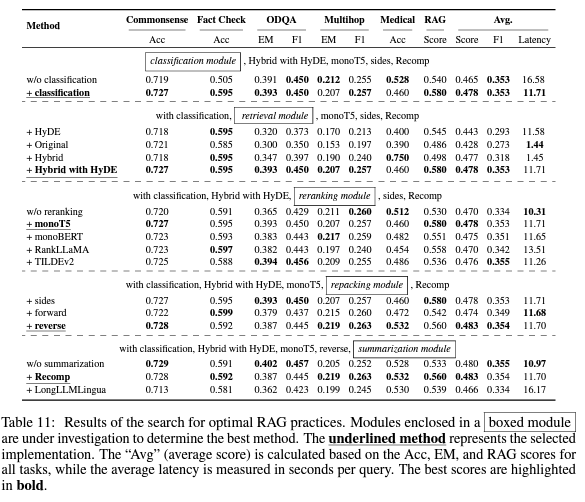
1. 종합 평가
실험 세부 사항 다양한 NLP 작업과 데이터셋에서 RAG 시스템의 성능을 평가했습니다.
- 작업: 상식 추론, 사실 확인, 오픈 도메인 QA, 멀티홉 QA, 의료 QA.
- 평가 지표: 성실성, 문맥 관련성, 답변 관련성, 답변 정확성, 검색 유사성.
- 기타 지표: 상식 추론, 사실 확인, 의료 QA에서는 정확도, 오픈 도메인 QA와 멀티홉 QA에서는 토큰 수준 F1 점수와 정확 매칭 점수를 사용했습니다.
2. 결과 및 분석
주요 통찰
- 쿼리 분류 모듈: 성능을 향상시키고 지연 시간을 줄였습니다.
- 전체 점수: 0.428에서 0.443으로 향상.
- 지연 시간: 쿼리당 16.41초에서 11.58초로 감소.
- 검색 모듈: "Hybrid with HyDE"가 최고 점수를 기록했으나 계산 비용이 높음.
- 추천: "Hybrid" 또는 "Original" 방법은 지연 시간을 줄이면서 유사한 성능을 유지.
- 재랭킹 모듈: 재랭킹이 없는 경우 성능이 크게 떨어짐.
- 최고 성능: MonoT5가 가장 높은 평균 점수를 기록.
- 재포장 모듈: Reverse 구성 방식이 우수한 성능을 보임.
- 점수: 0.560.
- 요약 모듈: Recomp가 최고의 성능을 보였지만, 요약 모듈을 제거하면 낮은 지연 시간으로 유사한 결과를 얻을 수 있음.
- Recomp는 생성기의 최대 길이 제한 문제를 해결하는 데 유용.
결론
각 모듈이 RAG 시스템의 전반적인 성능에 독특하게 기여합니다. 쿼리 분류는 정확성을 높이고 지연 시간을 줄이며, 검색 및 재랭킹 모듈은 다양한 쿼리를 처리하는 능력을 크게 향상시킵니다. 재포장 및 요약 모듈은 시스템의 출력을 더욱 정제하여 다양한 작업에서 높은 품질의 응답을 보장합니다.
Discussion
RAG 구현을 위한 최적의 방법
| 최고 성능 구현 | 효율성 균형 구현 | |
| 쿼리 분류 모듈 | 포함 | 포함 |
| 검색 | Hybrid with HyDE | Hybrid |
| 재랭킹 | monoT5 | TILDEv2 |
| 재포장 | Reverse | Reverse |
| 요약 | Recomp | Recomp |
| 평균 점수 | 0.483 | - |
| 특징 | 계산 집약적 | 지연 시간 감소, 성능 유지 |
멀티모달 확장
| 카테고리 | 텍스트-이미지 검색 (Text-to-Image Retrieval) | 이미지-텍스트 검색 (Image-to-Text Retrieval) |
| 과정 | 텍스트 쿼리로 유사한 이미지 검색 | 제공된 이미지를 데이터베이스의 이미지와 비교 |
| 유사한 이미지가 있으면 반환 | 유사한 이미지가 있으면 설명 반환 | |
| 유사한 이미지가 없으면 이미지 생성 모델 사용 | 유사한 이미지가 없으면 이미지 캡션 생성 모델 사용 | |
| 장점 | - 검증된 자료에서 정보 제공<br>- 빠른 응답<br>- 유지 관리 용이 | - 검증된 자료에서 정보 제공<br>- 빠른 응답<br>- 유지 관리 용이 |
| 워크플로우 | 상단 섹션 참고 | 하단 섹션 참고 |
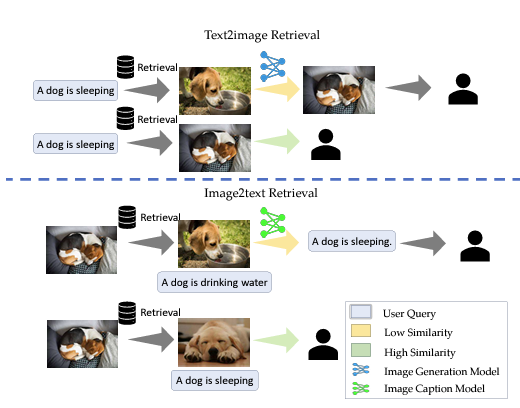
| 섹션 | 설명 |
| 텍스트-이미지 검색 | 텍스트 쿼리를 사용하여 데이터베이스에서 가장 유사한 이미지를 검색합니다. 유사한 이미지가 있으면 직접 반환하고, 없으면 이미지 생성 모델을 사용하여 적절한 이미지를 생성하고 반환합니다. |
| 이미지-텍스트 검색 | 사용자가 제공한 이미지를 데이터베이스의 이미지와 비교하여 가장 유사한 이미지를 찾습니다. 유사한 이미지가 있으면 사전 저장된 설명을 반환하고, 없으면 이미지 캡션 생성 모델이 새로운 설명을 생성하여 반환합니다. |
장점
- 정확성: 검증된 멀티모달 자료에서 정보 제공.
- 효율성: 저장된 자료를 사용하여 더 빠르게 응답.
- 유지 관리 용이성: 검색 자료 확장으로 새로운 요구사항에 쉽게 대응.
결론
이 연구는 대형 언어 모델의 콘텐츠 품질과 신뢰성을 향상시키기 위해 최적의 RAG(검색 보강 생성) 구현 방법을 식별하는 것을 목표로 했습니다. 각 모듈에 대한 다양한 솔루션을 체계적으로 평가하고, 가장 효과적인 접근 방식을 추천했습니다. 또한, RAG 시스템을 위한 종합적인 평가 벤치마크를 도입하고, 다양한 대안을 통해 최적의 방법을 도출했습니다. 우리의 연구는 RAG 시스템에 대한 이해를 심화하고, 미래 연구의 기초를 마련합니다.
한계
생성기 미세 조정 방법의 영향 평가에 집중했으며, 검색기와 생성기를 공동으로 훈련하는 가능성을 미래 연구에서 탐구하고자 합니다.
모듈식 설계를 채택하여 최적의 RAG 구현을 단순화했으나, 벡터 데이터베이스 구축과 실험 비용으로 인해 조각화 모듈의 대표적인 기법에만 초점을 맞췄습니다.
RAG의 NLP 도메인 응용과 이미지 생성 확장을 논의했으며, 향후 음성 및 비디오 등 다른 모달리티로의 확장이 흥미로운 연구 주제가 될 것입니다.
개인 생각
이 논문을 통해 전반적인 RAG에 대해서 다시 한번 정리할 수 있었던 논문이었던 것 같습니다.
논문의 결과도 유의미하게 볼 부분도 있겠지만 전체적으로 실험을 하는 방법이나 테스트 방법이 눈여겨 볼만합니다.
RAG에 fine tuning을 할 때 task나 지식 정보에 따라서 학습 여부를 정의하는 것과 vector db를 선택할 때 기준 같은 것을 정해서 선택하는 것이 좋았다.
그래서 아래는 최종적으로 이러한 것이 좋다고 말한 거라서 참고할 만할 것 같다.
최고 성능을 위한 방법
- 쿼리 분류 모듈: 포함
- 검색: "Hybrid with HyDE" 방법 사용
- 재랭킹: monoT5 사용
- 재포장: Reverse 방법 사용
- 요약: Recomp 방법 사용
- 평균 점수: 0.483, 계산 집약적
효율성과 성능 균형을 위한 방법
- 쿼리 분류 모듈: 포함
- 검색: Hybrid 방법 사용
- 재랭킹: TILDEv2 사용
- 재포장: Reverse 방법 사용
- 요약: Recomp 방법 사용
- 특징: 지연 시간 감소, 성능 유지
그리고크게 workflow에 다음과 같이 정의한 것도 RAG workflow를 이해하는 데 도움이 되었습니다.
- 쿼리 분류(Query Classification): 질문이 검색이 필요한지 결정해요.
- 정보 검색(Retrieval): 질문에 관련된 문서를 효율적으로 찾아요.
- 재랭킹(Reranking): 검색된 문서들의 중요도를 다시 정렬해요.
- 재포장(Repacking): 검색된 문서를 구조화된 형태로 정리해요.
- 요약(Summarization): 정리된 문서에서 핵심 정보를 추출해 답변을 만들어내요.
출처
| 논문 | https://arxiv.org/abs/2407.01219 |
| 논문에서 나온 코드 | https://github.com/FudanDNN-NLP/RAG |
'관심있는 주제 > LLM' 카테고리의 다른 글
| LLM) LLAVA 13b로 caption(설명) 또는 table 텍스트 데이터 생성해보기 (1) | 2024.07.30 |
|---|---|
| Layout LM(=Language Model) 알아보기 - TODO (1) | 2024.07.23 |
| LangGraph) LangGraph에 대한 개념과 간단한 예시 만들어보기 (0) | 2024.06.29 |
| Advanced RAG - 질문 유형 및 다양한 질문 유형을 위한 방법론(Ranker) (1) | 2024.06.22 |
| LLM) HuggingFace 에 사용하는 Tokenizer 의 결과 비교하는 Streamlit APP (0) | 2024.06.01 |