
LLM이 나오게 되면서 말을 엄청 잘하는 모델이 일상인 시대가 되었습니다.
여기서 좀 더 우리가 원하는 대로 만들기 위해서는 기존에 Pre training Model을 학습하거나 문맥 정보를 제공하여,
우리가 원하는 답을 생성하도록 할 수 있습니다.
이때 학습할 자료나 문맥을 제공할 때 우리는 문서를 잘 읽어서 제대로 전달해야지 LLM 성능을 그대로 활용할 수 있다.
하지만 실제로 문서를 보면 읽기 쉬운 문서만 있는 것이 아니라 복잡한 구조를 가지거나 그림을 해석해야 하는 등 다양한 작업들이 필요하다는 것을 알게 됩니다.
이번 글에서는 문서를 잘 이해하는 주제로 나온 논문인 Layout LM 들에 대해서 알아보고자 합니다.
Layout LM 이란?
LayoutLM은 스캔된 문서 이미지의 텍스트와 레이아웃 정보 간의 상호작용을 공동으로 모델링하는 신경망으로, 스캔된 문서에서 정보 추출과 같은 실질적인 문서 이미지 이해 작업에 매우 유용합니다.
기본적으로, 시각적으로 풍부한 문서에서 언어 표현을 실질적으로 향상시키는 두 가지 주요 특징이 있습니다:
문서 레이아웃 정보
시각적 정보
이 두 가지 특징은 문서 이미지에서 정보를 더 정확하게 이해하고 추출할 수 있게 합니다. 이를 통해 LayoutLM은 문서 이미지의 구조적 정보를 활용하여 텍스트와 그 레이아웃의 관계를 효과적으로 학습하고, 이를 다양한 문서 처리 작업에 적용할 수 있습니다.
쉽게 정리하면, LayoutLM은 문서의 텍스트와 그 배치 구조를 함께 고려하여 더 똑똑하게 문서의 내용을 이해하고 처리할 수 있게 하는 신경망 모델입니다.
이는 예를 들어, 스캔된 문서에서 필요한 정보를 자동으로 추출하는 데 매우 유용합니다.
Layout LM V1 (2019/12)
아키텍처 상세

Layout v1 에서는 BERT 와 같은 아키텍처에서 텍스트만 받는 것에서 문서 레이아웃에서 시각적으로 풍부한 정보를 활용하고 이를 입력 텍스트와 정렬하는 방안을 제안합니다.
두 가지 주요 특징:
- 문서 레이아웃 정보:
- 중요성: 문서에서 단어의 상대적 위치는 의미 표현에 크게 기여합니다. 예를 들어, 양식 이해에서는 "Passport ID:"와 같은 키가 있을 때 해당 값은 대개 오른쪽이나 아래에 위치합니다. 따라서 이러한 상대적 위치 정보를 2D 위치 표현으로 임베딩할 수 있습니다. Transformer 내의 자가 주의 메커니즘을 기반으로 2D 위치 특징을 언어 표현에 임베딩하면 레이아웃 정보와 의미 표현이 더 잘 정렬됩니다.
- 시각적 정보:
- 중요성: 텍스트 정보와 비교할 때, 시각적 정보는 문서 표현에서 또 다른 중요한 특징입니다. 일반적으로 문서는 문서 세그먼트의 중요성과 우선순위를 나타내기 위해 시각적 신호를 포함합니다. 시각적 정보는 이미지 특징으로 표현될 수 있으며, 문서 표현에 효과적으로 활용될 수 있습니다.
- 문서 수준 시각적 특징: 전체 이미지는 문서 레이아웃을 나타내며, 이는 문서 이미지 분류에 필수적인 특징입니다.
- 단어 수준 시각적 특징: 굵게, 밑줄, 이탤릭체 등의 스타일은 시퀀스 라벨링 작업에서 중요한 힌트가 됩니다. 따라서 이미지 특징과 전통적인 텍스트 표현을 결합하면 문서에 더 풍부한 의미 표현을 제공할 수 있습니다.
그래서 모델 구조를 보면 추가된 것은 다음과 같습니다. (2D 위치 임베딩, 이미지 임베딩)
- 2D 위치 임베딩:
- 정의: 시퀀스에서 단어의 위치를 모델링하는 위치 임베딩과 달리, 2D 위치 임베딩은 문서 내의 상대적 공간 위치를 모델링합니다.
- 방법: 문서 페이지를 좌상단을 원점으로 하는 좌표 시스템으로 간주합니다. 이 설정에서 바운딩 박스는 (x0, y0, x1, y1)로 정확하게 정의됩니다. 여기서 (x0, y0)는 바운딩 박스의 좌상단 위치를, (x1, y1)는 우하단 위치를 나타냅니다. 동일한 차원을 나타내는 임베딩 레이어는 동일한 임베딩 테이블을 공유하는 네 개의 위치 임베딩 레이어를 추가합니다. 즉, x0와 x1은 테이블 X에서, y0와 y1은 테이블 Y에서 임베딩을 찾아 사용합니다.
- 이미지 임베딩:
- 정의: 문서의 이미지 특징을 사용하여 텍스트와 이미지 특징을 정렬합니다.
- 방법: OCR 결과에서 각 단어의 바운딩 박스를 기준으로 이미지를 여러 조각으로 나누어 각 단어와 일대일로 대응시킵니다. Faster R-CNN 모델을 사용하여 이러한 이미지 조각으로부터 이미지 영역 특징을 생성하고 이를 토큰 이미지 임베딩으로 사용합니다. [CLS] 토큰의 경우, 전체 스캔 문서 이미지를 Region of Interest (ROI)로 사용하여 Faster R-CNN 모델을 통해 임베딩을 생성합니다. 이는 [CLS] 토큰의 표현이 필요한 다운스트림 작업에 도움이 됩니다.

Faster R-CNN Object Detection 예시
https://github.com/microsoft/unilm/blob/master/layoutlm/deprecated/layoutlm/modeling/layoutlm.py
class LayoutlmEmbeddings(nn.Module):
def __init__(self, config):
super(LayoutlmEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(
config.vocab_size, config.hidden_size, padding_idx=0
)
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size
)
self.x_position_embeddings = nn.Embedding(
config.max_2d_position_embeddings, config.hidden_size
)
self.y_position_embeddings = nn.Embedding(
config.max_2d_position_embeddings, config.hidden_size
)
self.h_position_embeddings = nn.Embedding(
config.max_2d_position_embeddings, config.hidden_size
)
self.w_position_embeddings = nn.Embedding(
config.max_2d_position_embeddings, config.hidden_size
)
self.token_type_embeddings = nn.Embedding(
config.type_vocab_size, config.hidden_size
)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
학습 방법 (사전 훈련)
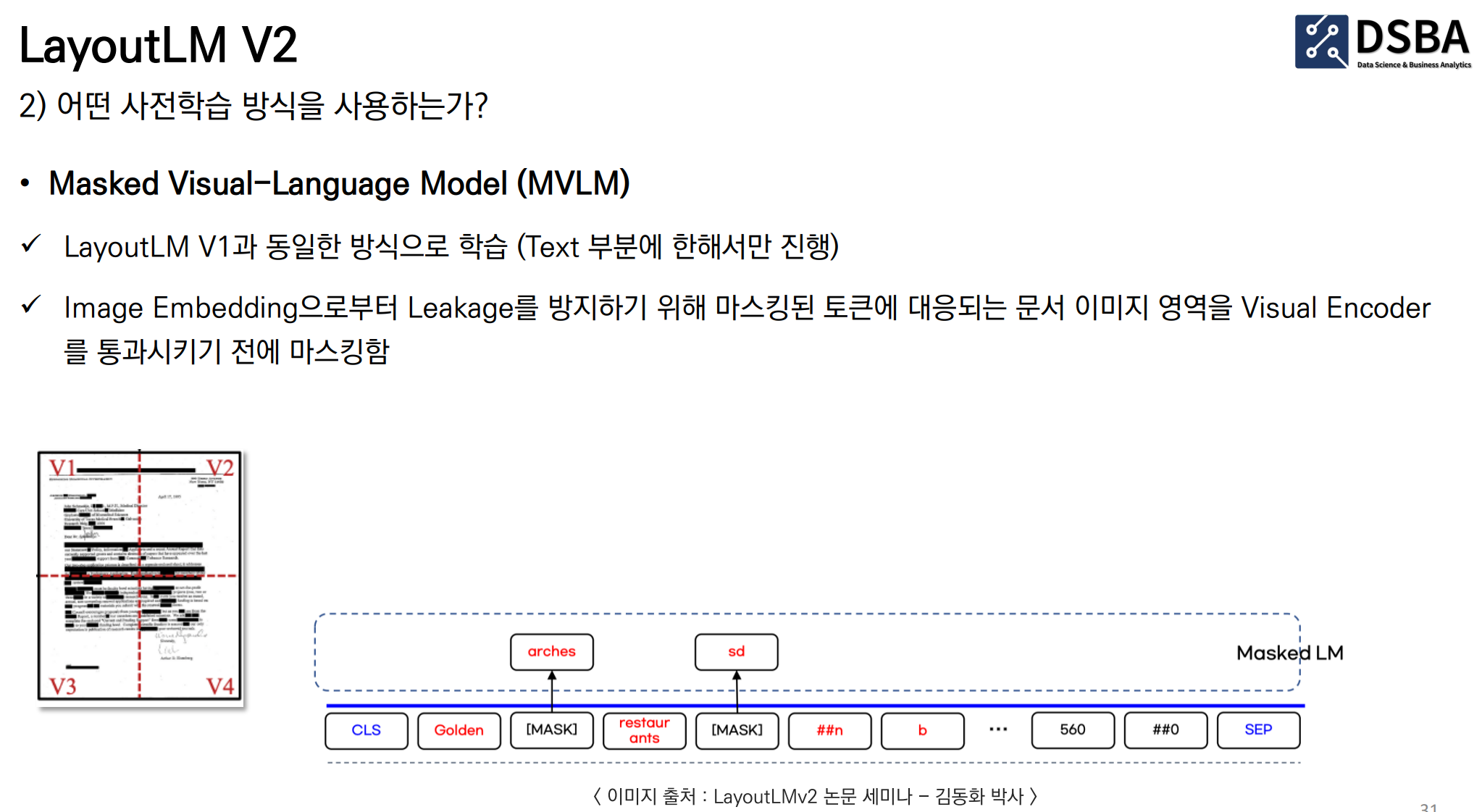
- 1: Masked Visual-Language Model (MVLM):
- 정의: Masked Language Model에서 영감을 받아, MVLM은 2D 위치 임베딩과 텍스트 임베딩의 단서로 언어 표현을 학습합니다.
- 방법: 사전 훈련 중 일부 입력 토큰을 무작위로 마스킹하지만, 해당 2D 위치 임베딩은 유지합니다. 그런 다음 모델은 컨텍스트를 기반으로 마스킹된 토큰을 예측하도록 훈련됩니다. 이를 통해 LayoutLM 모델은 언어 컨텍스트뿐만 아니라 시각적 정보도 이해하게 됩니다.
- 즉 빈칸을 뚤어 놓은 다음에 맞추는 식으로 학습함. / 특이한 점은 좌표는 유지하고 학습시킵니다.
- 2: 다중 레이블 문서 분류 (Multi-label Document Classification, MDC):
- 정의: 문서 이미지 이해를 위한 많은 작업에서 모델은 고품질의 문서 수준 표현을 생성해야 합니다.
- 방법: IIT-CDIP Test Collection에는 각 문서 이미지에 여러 태그가 포함되어 있으므로, 사전 훈련 단계에서 MDC 손실을 사용하여 문서 태그로 학습을 감독합니다. 이는 모델이 다양한 도메인의 지식을 클러스터링하고 더 나은 문서 수준 표현을 생성할 수 있도록 돕습니다. 다만, 큰 데이터셋에는 레이블이 없을 수 있으므로 MDC 손실은 선택적입니다.
결과물을 봤을 때, 이미지를 줬을 때 성능향상이 많이 됬다고 하고 이미지 정보가 유의미하다는 것을 의미합니다.
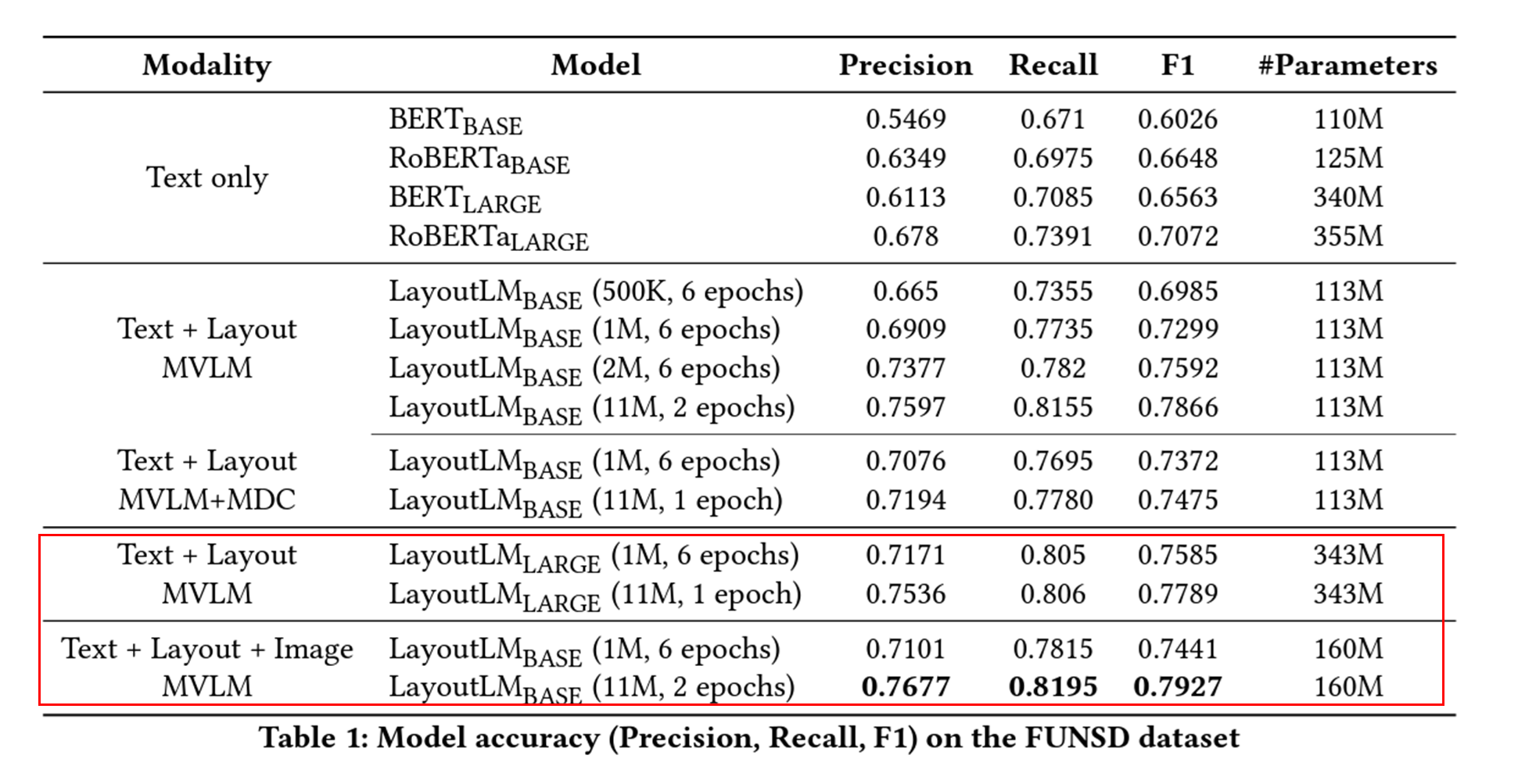
LayoutLM V2 (2020/12)
LayoutLM v1과 LayoutLM v2의 차이점 및 접근 이유
| 특징 | LayoutLM v1 | LayoutLM v2 | 변경 이유 |
| 기본 아키텍처 | BERT 기반 다층 양방향 Transformer 인코더 | 두 개의 스트림을 가진 다중 모달 Transformer 인코더 | 교차 모달리티 상호 작용을 더 잘 학습하기 위해 |
| 시각적 정보 통합 | 미세 조정 단계에서 통합 | 사전 훈련 단계에서 통합 | 텍스트와 시각적 정보의 관계를 사전 훈련 단계에서 더 깊이 이해하기 위해 |
| 위치 임베딩 | 절대적 2D 위치 임베딩 | 상대적 2D 위치 임베딩 | 토큰 간의 상대적 공간 관계를 명시적으로 모델링하여 문서 내 레이아웃 패턴을 더 잘 캡처하기 위해 |
| 추가 사전 훈련 작업 | 없음 | 텍스트-이미지 정렬, 텍스트-이미지 매칭 | 텍스트와 이미지 간의 복잡한 상호 작용을 더 잘 학습하기 위해 |
| Masked Visual-Language Modeling (MVLM) | 일부 입력 토큰을 무작위로 마스킹하고 해당 2D 위치 임베딩 유지 | 일부 입력 토큰을 무작위로 마스킹하고 해당 2D 위치 임베딩 유지 | 기존 MVLM 작업 유지 |
| 텍스트-이미지 정렬 | 없음 | 텍스트 라인과 해당 이미지 영역 정렬 | 텍스트와 시각적 요소의 대응 관계를 학습하여 문서에서 중요한 정보를 더 잘 추출하기 위해 |
| 텍스트-이미지 매칭 | 없음 | 문서 이미지와 텍스트 내용의 관련성 학습 | 시각적 정보와 텍스트 정보가 어떻게 결합되어 전체 문서의 의미를 구성하는지 이해하기 위해 |
| 성능 개선 | 여러 시각적으로 풍부한 문서 이해 작업에서 좋은 성능 | 모든 작업에서 큰 성능 향상, 새로운 최첨단 결과 달성 | 새로운 접근 방식이 모델의 교차 모달리티 상호 작용을 효과적으로 향상시킴 |
- 결론: LayoutLM v2는 시각적 정보와 텍스트 정보를 사전 훈련 단계에서 더 깊이 통합하고, 텍스트-이미지 정렬 및 매칭 작업을 추가하여 모델이 다양한 문서 형식에서 더 잘 일반화하고, 문서 내의 복잡한 상호 작용을 더 잘 이해할 수 있도록 개선되었습니다.
V1 대비 자세한 차이점은 다음과 같습니다.
1. 모델 아키텍처
- LayoutLM v1:
- 기본 아키텍처: BERT 기반의 다층 양방향 Transformer 인코더.
- 입력 임베딩: 텍스트, 2D 위치 임베딩, 이미지 임베딩을 포함.
- 시각적 정보: 미세 조정 단계에서 시각적 정보가 결합됨.
- LayoutLM v2:
- 기본 아키텍처: 두 개의 스트림을 가진 다중 모달 Transformer 인코더.
- 입력 임베딩: 텍스트, 2D 위치 임베딩, 이미지 임베딩을 포함.
- 시각적 정보: 사전 훈련 단계에서 시각적 정보가 결합됨.
- 공간 인식 자가 주의 메커니즘: 1D 상대적 위치 표현 대신 2D 상대적 위치 표현을 사용하여 토큰 간의 공간적 관계를 명시적으로 모델링.
2. 사전 훈련 작업
- LayoutLM v1:
- Masked Visual-Language Modeling (MVLM): 일부 입력 토큰을 무작위로 마스킹하고 해당 2D 위치 임베딩을 유지하여 언어 및 시각 정보를 학습.
- LayoutLM v2:
- Masked Visual-Language Modeling (MVLM): 기존의 마스킹된 시각-언어 모델링 작업 유지.
- 추가된 사전 훈련 작업:
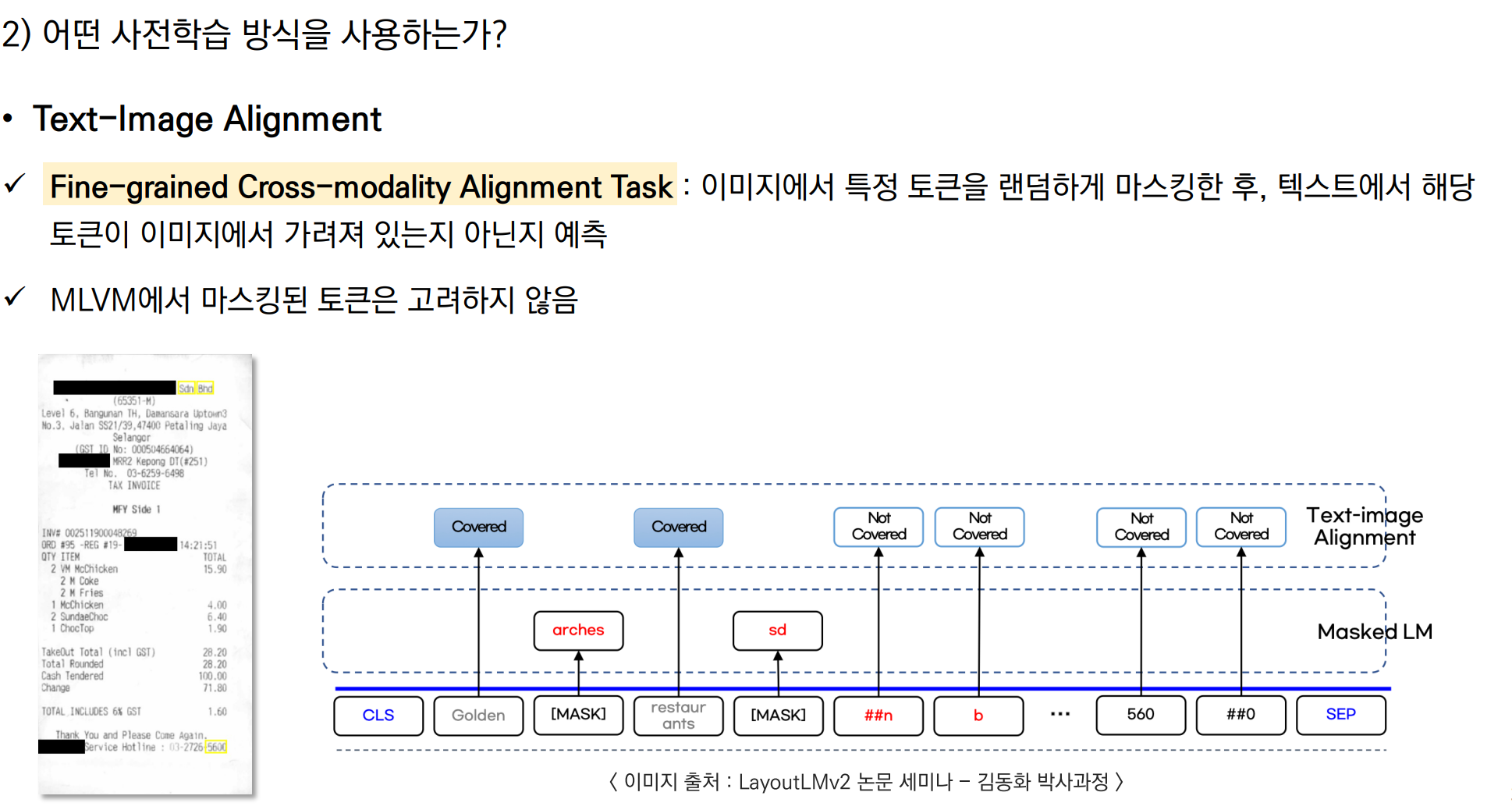
- 텍스트-이미지 정렬 (Text-Image Alignment): 텍스트 라인과 해당 이미지 영역을 정렬하여 학습.
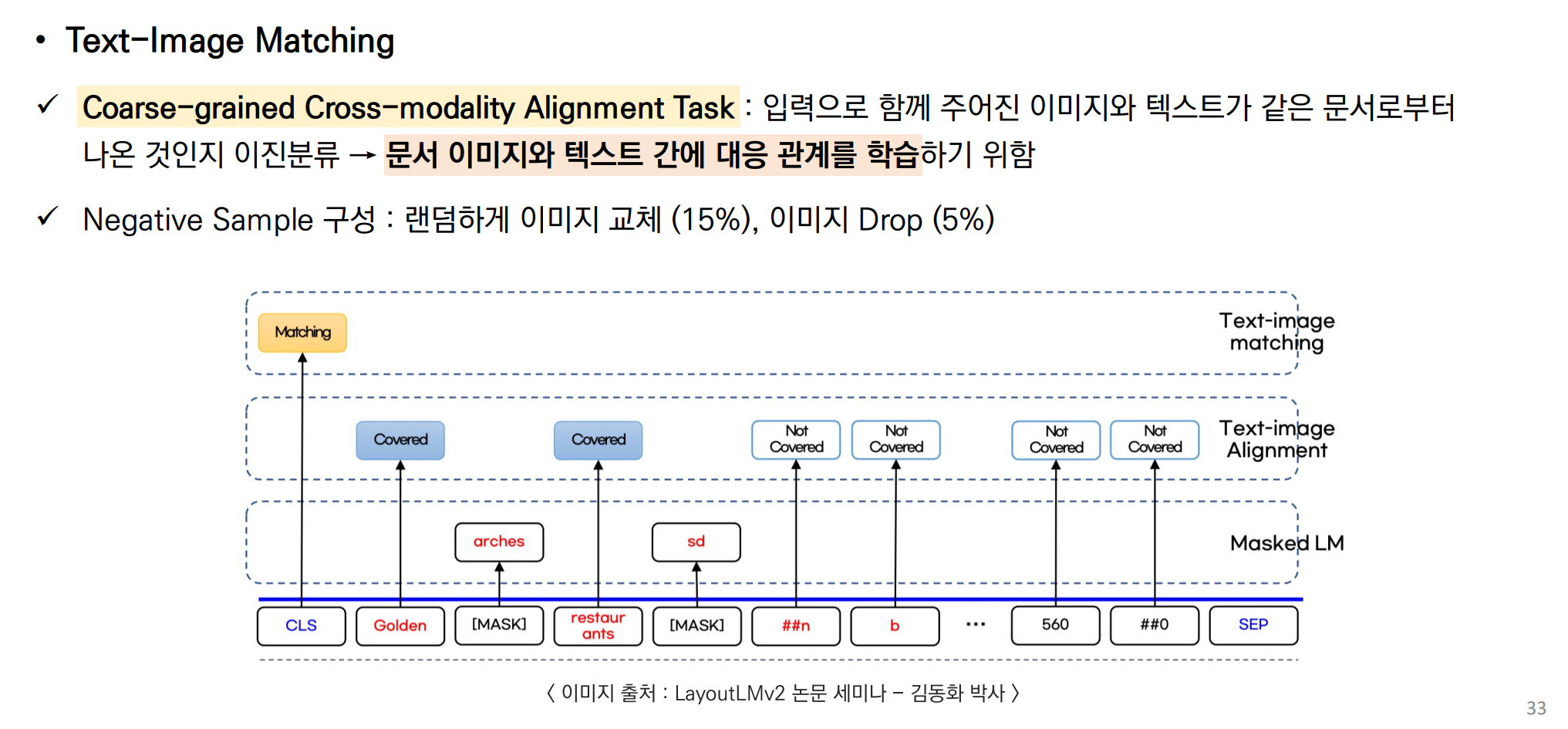
- 텍스트-이미지 매칭 (Text-Image Matching): 문서 이미지와 텍스트 내용이 관련이 있는지 학습.
3. 성능 개선
- LayoutLM v1:
- 여러 시각적으로 풍부한 문서 이해 작업에서 좋은 성능을 보임.
- LayoutLM v2:
- LayoutLM v1에 비해 다양한 작업에서 큰 성능 향상을 보여줌.
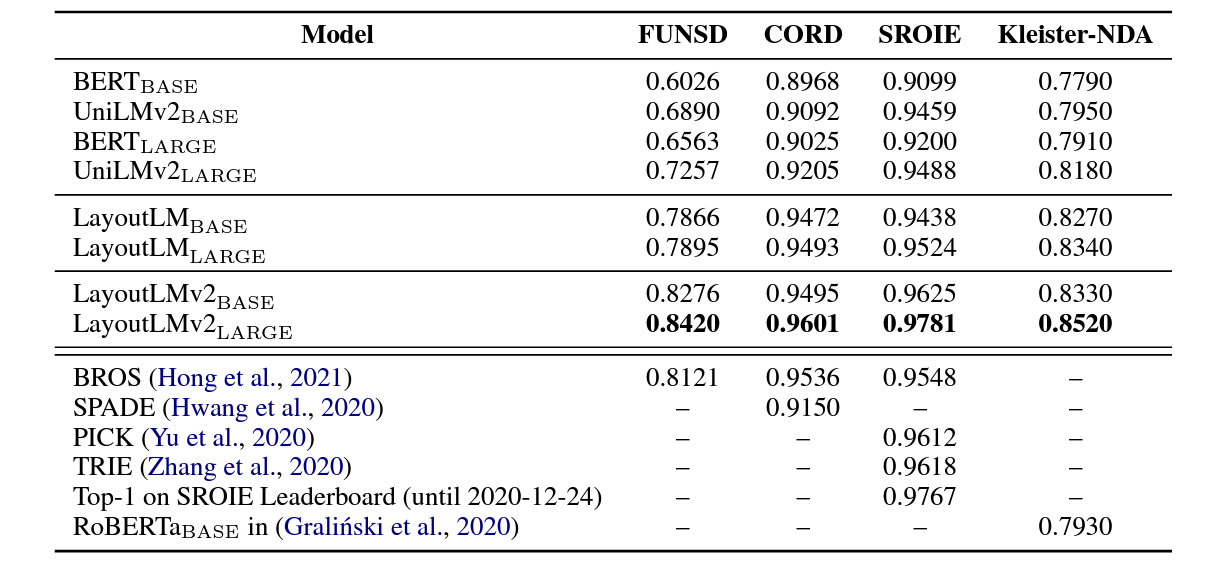
- 새로운 최첨단 결과 달성:
- FUNSD: 0.7895 → 0.8420
- CORD: 0.9493 → 0.9601
- SROIE: 0.9524 → 0.9781
- Kleister-NDA: 0.8340 → 0.8520
- RVL-CDIP: 0.9443 → 0.9564
- DocVQA: 0.7295 → 0.8672
LayoutLMv2 접근 방법 요약 (테이블 형식)
| 구성 요소 | 설명 |
| 모델 아키텍처 | 다중 모달 Transformer 아키텍처, 텍스트, 시각적, 레이아웃 정보 입력 |
| 텍스트 임베딩 | WordPiece로 토큰화, 토큰 임베딩 + 1D 위치 임베딩 + 세그먼트 임베딩 |
| 시각적 임베딩 | ResNeXt-FPN 백본 사용, 시각적 임베딩 생성 |
| 레이아웃 임베딩 | OCR 바운딩 박스 사용, 2D 위치 임베딩 생성 |
| 다중 모달 인코더 | 시각적, 텍스트 임베딩 통합, 레이아웃 임베딩 추가 |
| 공간 인식 자가 주의 메커니즘 | 상대적 위치 정보 삽입, 공간적 관계 모델링 |
| 세부 구성 요소 | 설명 |
| 텍스트 임베딩 | - 토큰화: WordPiece로 텍스트 시퀀스를 토큰화 - 구성 요소: 토큰 임베딩, 1D 위치 임베딩, 세그먼트 임베딩 |
| 시각적 임베딩 | - 기본 아키텍처: ResNeXt-FPN 백본 사용 - 프로세스: 페이지 이미지를 224x224로 크기 조정 후 처리 - 출력: 고정 크기 출력 맵 생성 및 평탄화 - 1D 위치 임베딩: 텍스트 임베딩과 공유 - 세그먼트 임베딩: 시각적 토큰에 [C] 할당 |
| 레이아웃 임베딩 | - 정의: 축 정렬 토큰 바운딩 박스를 사용 - 구성 요소: x축과 y축 특징을 개별적으로 임베딩 |
| 다중 모달 인코더 | - 인코더: 시각적 임베딩과 텍스트 임베딩을 단일 시퀀스로 결합 - 레이아웃 임베딩 추가: 첫 번째 레이어 입력에 포함 |
| 공간 인식 자가 주의 메커니즘 | - 원래 메커니즘: 입력 토큰 간의 관계를 암묵적으로 포착 - 변경된 메커니즘: 상대적 위치 정보를 명시적으로 삽입 - 공간 인식 주의 점수: 상대적 위치 바이어스를 추가하여 계산 |
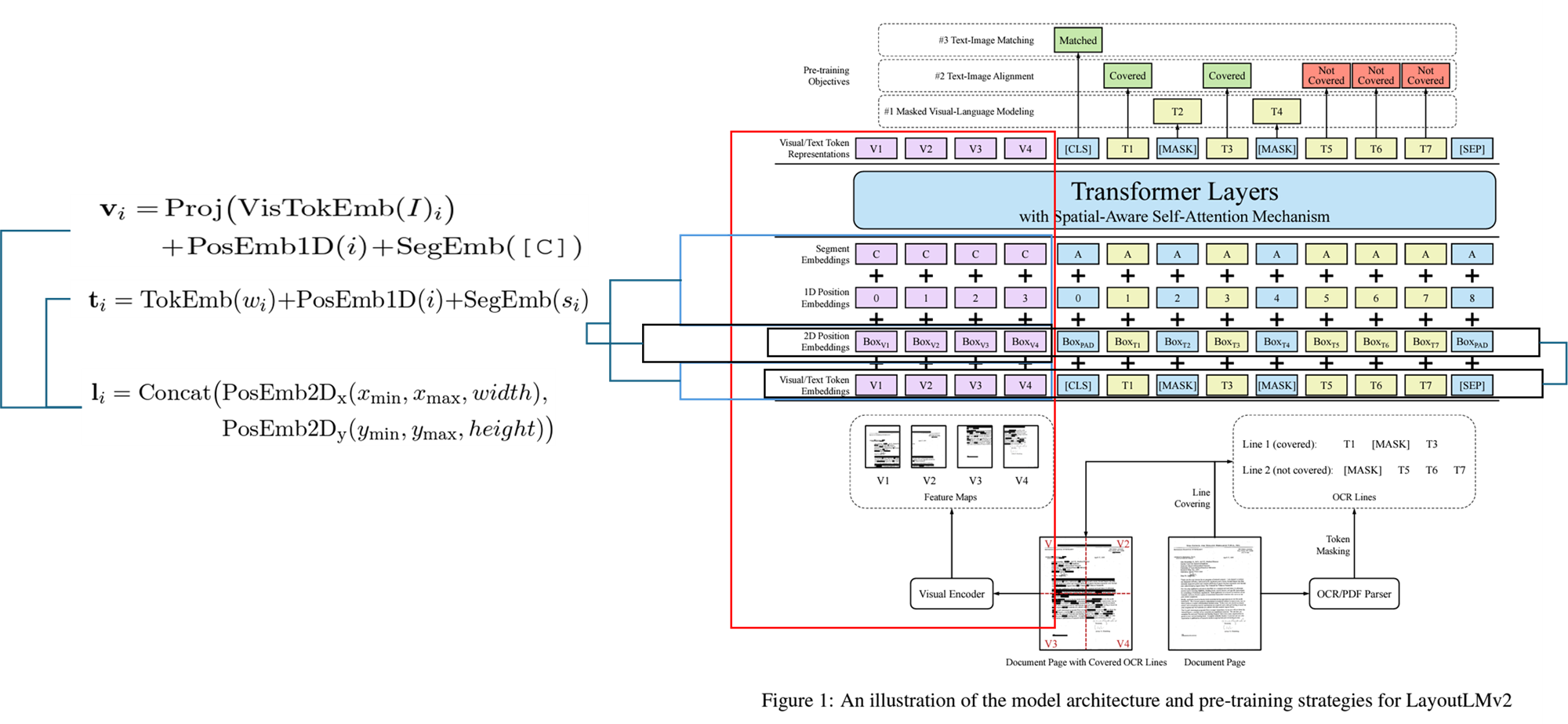
위의 그림처럼 Vi + Li = Layout Embedding / Ti + Li = Text Embbedding으로 되어있고 각각의 임베딩 값으로 보면 좋을 것 같다.
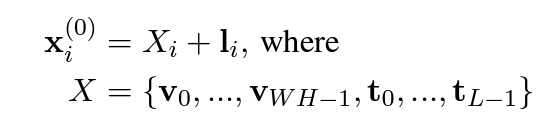
사전 학습 부분을 시각적인 내용과 함께 잘 설명해준 DSBA 이미지를 공유드린다.
| 사전 훈련 작업 | 목적 | 세부 사항 | 이유 |
| Masked Visual-Language Modeling (MVLM) | 언어 모델링과 시각적 정보의 상호 작용을 통해 모델의 언어 이해 능력 향상 | - 일부 텍스트 토큰을 마스킹하여 모델이 이를 복원하도록 학습 - 텍스트와 레이아웃 정보를 통합하여 텍스트의 위치를 인식 |
단순한 언어 모델링을 넘어서, 텍스트와 레이아웃의 관계를 학습하여 시각적 단서가 포함된 문서 이해 능력을 향상 |
| Text-Image Alignment (TIA) | 이미지와 텍스트 간의 공간적 위치 관계 학습 | - 텍스트 라인의 일부를 덮어서 모델이 해당 영역이 덮였는지 여부를 예측 - 라인 단위로 덮기 작업 수행 |
텍스트와 이미지의 공간적 위치를 정밀하게 정렬하여, 문서의 구조적 이해 능력을 향상 |
| Text-Image Matching (TIM) | 문서 이미지와 텍스트 내용 간의 전반적인 대응 관계 학습 | - [CLS] 토큰을 사용하여 문서 이미지와 텍스트가 같은 페이지에서 왔는지 예측 - 긍정 샘플과 부정 샘플 구성 |
문서 이미지와 텍스트의 전반적인 상관 관계를 학습하여 다양한 문서 형식에서의 이해 능력을 향상 |
요약
이 표는 LayoutLMv2가 Masked Visual-Language Modeling (MVLM), Text-Image Alignment (TIA), Text-Image Matching (TIM) 세 가지 주요 사전 훈련 작업을 수행하는 이유를 목적, 세부 사항, 그리고 각 작업을 수행하는 이유로 정리한 것입니다.
사전 학습 1. MVLM
사전 학습 2. Text-Image Alignment
사전 학습 3. Text-Image Matching
성능 결과
기존 v1보다 앞서는 결과를 얻을 수 있었다고 합니다.
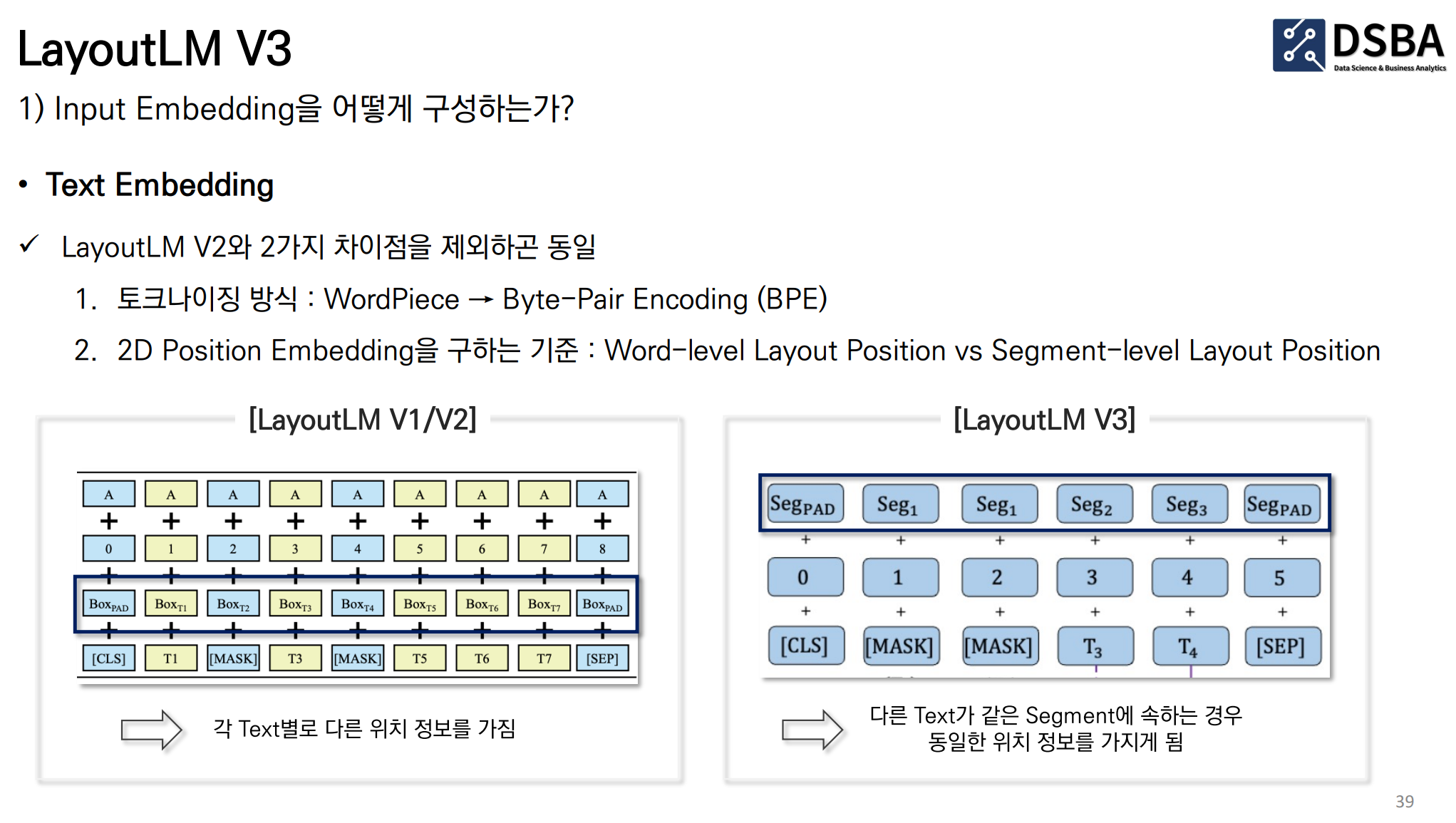
Layout LM V3 (2022/01)
기존 모델과의 비교
| 항목 | LayoutLMv2 | LayoutLMv3 |
| 시각적 특징 추출 | CNN 기반 백본(Faster R-CNN 등)을 사용하여 시각적 특징을 추출함 | 사전 훈련된 CNN 없이 시각적 특징을 추출함. 대신, 문서 이미지에서 직접 선형 패치를 사용하여 특징을 추출 |
| 마스킹 목표 | 텍스트 마스킹 (MLM)과 이미지 마스킹을 개별적으로 사용 | 통합된 텍스트 및 이미지 마스킹 목표 (MLM 및 MIM)를 사용하여 두 모달리티 간의 불일치를 완화 |
| 교차 모달 정렬 목표 | Text-Image Alignment (TIA)와 Text-Image Matching (TIM)를 사용 | Word-Patch Alignment (WPA) 목표를 도입하여 텍스트 단어와 해당 이미지 패치의 교차 모달 정렬을 학습 |
| 아키텍처 단순성 | CNN 백본을 사용하여 복잡한 시각적 특징 추출 단계를 포함 | 단순하고 깔끔한 아키텍처로, 복잡한 전처리 단계를 제거하고 범용적인 모델로 설계 |
| 응용 작업 | 주로 텍스트 중심 작업(예: 양식 이해, 영수증 이해, 문서 이미지 분류 등) | 텍스트 중심 작업 뿐만 아니라 이미지 중심 작업(예: 문서 레이아웃 분석)에서도 뛰어난 성능 발휘 |
| 모델 성능 | 기존 모델 대비 우수한 성능을 보임 | 기존 모델 대비 뛰어난 성능을 보이며, 여러 공공 벤치마크에서 최첨단 성능을 달성 |
| 파라미터 효율성 | CNN 기반 백본을 사용하여 상대적으로 많은 파라미터 필요 | CNN 백본을 사용하지 않아 파라미터가 절약되고, 단순한 구조 덕분에 재현이 용이 |
모델 아키텍처
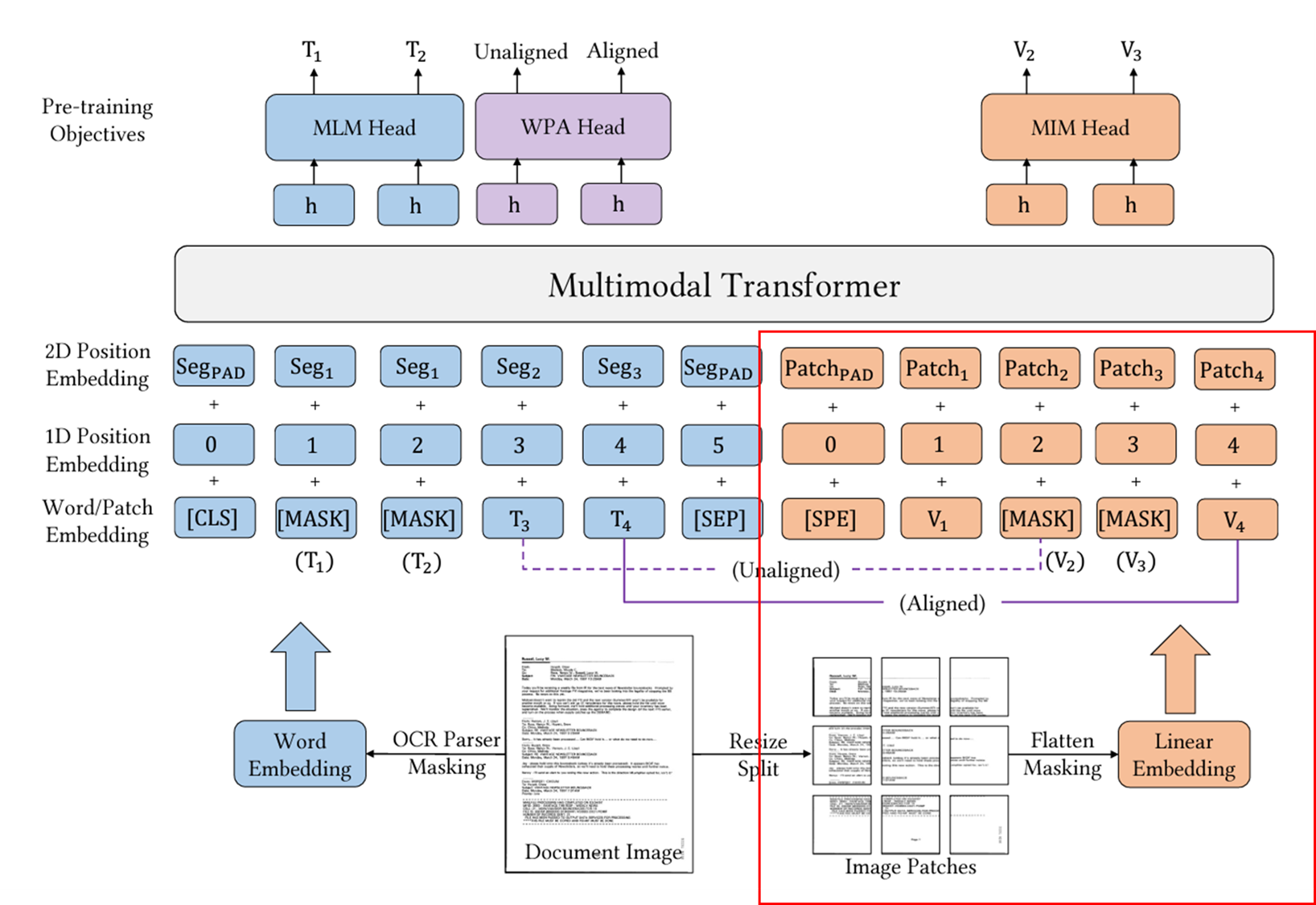
출처
'관심있는 주제 > LLM' 카테고리의 다른 글
| LangChain Products 알아보기 (LangChain, LangGraph, LangSmith, LangServe) (0) | 2024.08.07 |
|---|---|
| LLM) LLAVA 13b로 caption(설명) 또는 table 텍스트 데이터 생성해보기 (1) | 2024.07.30 |
| 논문 정리) Searching for Best Practices in Retrieval-Augmented Generation (0) | 2024.07.05 |
| LangGraph) LangGraph에 대한 개념과 간단한 예시 만들어보기 (0) | 2024.06.29 |
| Advanced RAG - 질문 유형 및 다양한 질문 유형을 위한 방법론(Ranker) (1) | 2024.06.22 |