2024. 6. 22. 11:57ㆍ관심있는 주제/LLM
다양한 사용자 질의 유형
RAG 애플리케이션에서 사용자 질의는 개별 의도에 따라 다양하게 달라집니다.
Microsoft는 다양한 사용자 질의 카테고리를 식별하였고 해당 내용은 다음과 같습니다.
| 질의 유형 (Query Type) | 설명 (Explanation) | 예시 (Example) |
| 개념 탐색 질의 (Concept Seeking Queries) | 여러 문장이 필요한 추상적인 질문 (Abstract questions that require multiple sentences to answer) | 시맨틱 검색을 사용하여 결과를 순위 매기는 이유는 무엇인가요? (Why should I use semantic search to rank results?) |
| 정확한 스니펫 검색 (Exact Snippet Search) | 원본 문장에서 정확히 일치하는 긴 구절 (Longer queries that are exact sub-strings from the original paragraph) | 관련 정보만 제공하여 LLM 투자의 품질과 가치를 가장 효율적으로 극대화할 수 있습니다 (enables you to maximize the quality and value of your LLM investments most efficiently by feeding only relevant information) |
| 웹 검색과 유사한 질의 (Web Search-like Queries) | 검색 엔진에 자주 입력되는 짧은 질의 (Shortened queries similar to those commonly entered into a search engine) | 최고의 검색 개념 질의 (Best retrieval concept queries) |
| 낮은 질의/문서 용어 중복 (Low Query/Doc Term Overlap) | 질문과 답변이 서로 다른 단어와 구를 사용하는 질의 (Queries where the answer uses different words and phrases from the question) | 정렬을 위한 최고의 기술 (greatest technology for sorting) - 문서 내용: Azure AI Search는 콘텐츠를 순위 매기는 데 가장 좋은 모델을 가지고 있습니다 (Azure AI Search has the best models for ranking your content) |
| 사실 탐색 질의 (Fact Seeking Queries) | 명확한 하나의 답변이 있는 질의 (Queries with a single, clear answer) | 시맨틱하게 순위 매겨진 문서는 몇 개입니까? (How many documents are semantically ranked?) |
| 키워드 질의 (Keyword Queries) | 중요한 단어들로만 구성된 짧은 질의 (Short queries that consist of only the important identifier words) | 시맨틱 랭커 (semantic ranker) |
| 오타가 있는 질의 (Queries with Misspellings) | 철자 오류나 일반적인 오타가 포함된 질의 (Queries with typos, transpositions and common misspellings introduced) | 시맨틱하게 r4nked 된 문서는 몇 개입니까? (Ho w mny documents are samantically r4nked) |
| 긴 질의 (Long Queries) | 20개 이상의 단어로 구성된 질의 (Queries longer than 20 tokens) | 이것은 구성이 길고 구조가 복잡한 매우 긴 질의입니다 (This is a very long query that uses a lot of tokens in its composition and structure because it is verbose) |
| 중간 길이의 질의 (Medium Queries) | 5개에서 20개의 단어로 구성된 질의 (Between 5 and 20 tokens long) | 이것은 중간 길이의 질의입니다 (This is a medium length query) |
| 짧은 질의 (Short Queries) | 5개 미만의 단어로 구성된 질의 (Queries shorter than 5 tokens) | 짧은 질의 (Short query) |
Hybrid Retrieval 필요 이유
키워드 검색과 벡터 검색은 각각 다른 관점에서 검색을 수행하며, 이 두 방법의 조합은 상호 보완적인 기능을 제공합니다.
벡터 검색은 의미적으로 질의와 유사한 의미를 가진 문장을 매칭합니다. 이는 철자 오류, 동의어, 구문 차이에 덜 민감하며, 심지어 다국어 시나리오에서도 작동할 수 있기 때문에 강력합니다.
반면에 키워드 검색은 중요한 특정 단어를 우선적으로 매칭하므로 임베딩에서 희석될 수 있는 중요한 단어를 강조할 수 있습니다.
사용자 검색의 다양한 형태
하이브리드 검색은 일관되게 두 검색 방법의 장점을 결합하여 모든 질의 유형에서 최고의 성능을 발휘합니다. 가장 효과적인 1단계(L1) 검색 후, 2단계(L2) 랭킹 단계에서 상위 위치의 결과 품질을 크게 향상할 수 있습니다.
다양한 질의 유형에 대한 NDCG@3 비교
아래 결과를 보게 되면 하이브리드를 단순히 쓰는 것 보다 Semantic Ranker를 써서 기존 결과를 잘 정리를 하니 훨씬 더 성능이 높아지는 게 인상적이긴 합니다.
| 질의 유형 (Query Type) | 키워드 (Keyword) [NDCG@3] | 벡터 (Vector) [NDCG@3] | 하이브리드 (Hybrid) [NDCG@3] | 하이브리드 + 시맨틱 랭커 (Hybrid + Semantic Ranker) [NDCG@3] |
| 개념 탐색 질의 (Concept Seeking Queries) | 39.0 | 45.8 | 46.3 | 59.6 |
| 사실 탐색 질의 (Fact Seeking Queries) | 37.8 | 49.0 | 49.1 | 63.4 |
| 정확한 스니펫 검색 (Exact Snippet Search) | 51.1 | 41.5 | 51.0 | 60.8 |
| 웹 검색과 유사한 질의 (Web Search-like Queries) | 41.8 | 46.3 | 50.0 | 58.9 |
| 키워드 질의 (Keyword Queries) | 79.2 | 11.7 | 61.0 | 66.9 |
| 낮은 질의/문서 용어 중복 (Low Query/Doc Term Overlap) | 23.0 | 36.1 | 35.9 | 49.1 |
| 오타가 있는 질의 (Queries with Misspellings) | 28.8 | 39.1 | 40.6 | 54.6 |
| 긴 질의 (Long Queries) | 42.7 | 41.6 | 48.1 | 59.4 |
| 중간 길이의 질의 (Medium Queries) | 38.1 | 44.7 | 46.7 | 59.9 |
| 짧은 질의 (Short Queries) | 53.1 | 38.8 | 53.0 | 63.9 |
위 표는 다양한 질의 유형과 검색 구성에서 NDCG@3 값을 비교한 것입니다. 모든 벡터 검색 모드는 동일한 문서 청크(512 토큰 청크, 25% 중첩, Ada-002 임베딩 모델 사용)를 사용하여 고객 질의/문서 벤치마크에서 테스트되었습니다.
참고로 아래에서 말하는 L1, L2는 Azure AI에서 정의한 개념입니다.
| 계층 (Layer) | 모드 (Mode) | 기능 (Functionality) | |
| 검색 (Retrieval) - L1 | 키워드 검색 (Keyword) | 전통적인 전체 텍스트 검색 방법을 사용하여 콘텐츠를 용어로 분해하고, 역색인을 생성하며, BM25 확률 모델로 점수 매기기 | |
| 검색 (Retrieval) - L1 | 벡터 검색 (Vector) | 임베딩 모델을 사용하여 문서를 텍스트에서 벡터 표현으로 변환하고, 쿼리에 가장 가까운 벡터를 가진 문서를 찾기 | |
| 검색 (Retrieval) - L1 | 하이브리드 검색 (Hybrid) | 키워드 검색과 벡터 검색을 모두 수행하고, 상호 순위 융합(RRF)을 사용하여 최상의 결과 선택 | |
| 랭킹 (Ranking) - L2 | 시맨틱 랭킹 (Semantic Ranking) | Microsoft Bing에서 적응된 다국어 심층 학습 모델을 사용하여 상위 50개 결과를 재정렬 | |
검색 (Retrieval)
일반적으로 L1이라고 불리며, 이 단계의 목표는 검색 기준을 충족하는 모든 문서를 인덱스에서 신속하게 찾는 것입니다. 이 단계에서는 수백만 또는 수십억 개의 문서 중에서 상위 몇 개(일반적으로 50개)를 선택하여 사용자에게 반환하거나 다음 계층으로 전달합니다. Azure AI 검색은 세 가지 L1 모드를 지원합니다:
- 키워드 검색 (Keyword): 전통적인 전체 텍스트 검색 방법을 사용합니다. 언어별 텍스트 분석을 통해 콘텐츠를 용어로 분해하고, 빠른 검색을 위해 역색인을 생성하며, BM25 확률 모델을 사용하여 점수를 매깁니다.
- 벡터 검색 (Vector): 문서를 임베딩 모델을 사용하여 텍스트에서 벡터 표현으로 변환합니다. 검색은 쿼리 임베딩을 생성하고 쿼리에 가장 가까운 벡터를 가진 문서를 찾는 방식으로 수행됩니다. 이 게시글의 모든 테스트에서 Azure Open AI의 text-embedding-ada-002 (Ada-002) 임베딩과 코사인 유사성을 사용했습니다.
- 하이브리드 검색 (Hybrid): 키워드 검색과 벡터 검색을 모두 수행하고, 각 기술에서 최상의 결과를 선택하기 위해 융합 단계를 적용합니다. Azure AI 검색은 현재 상호 순위 융합(Reciprocal Rank Fusion, RRF)을 사용하여 단일 결과 세트를 생성합니다.
랭킹 (Ranking)
일반적으로 L2라고 불리며, 상위 L1 결과의 일부를 가져와 더 높은 품질의 관련성 점수를 계산하여 결과 세트를 재정렬합니다. L2는 각 결과에 더 많은 계산 능력을 적용하여 L1의 랭킹을 개선할 수 있습니다. L2 랭커는 L1에서 이미 찾은 것을 재정렬할 수만 있으며, L1이 이상적인 문서를 놓친 경우 L2가 이를 수정할 수는 없습니다. L2 랭킹은 RAG 애플리케이션에서 최상의 결과가 상위에 위치하도록 하는 데 중요합니다.
Azure AI 검색의 L2 랭커는 Microsoft Bing에서 적응된 다국어 심층 학습 모델을 사용하여 시맨틱 랭킹을 수행합니다. 시맨틱 랭커는 L1의 상위 50개 결과를 랭킹 할 수 있습니다.
Semantic Ranking
시맨틱 랭킹은 텍스트 기반 질의의 초기 BM25 또는 RRF로 순위가 매겨진 검색 결과의 품질을 향상시키기 위한 고급 검색 기능입니다. 시맨틱 랭킹은 검색 서비스에서 활성화되며, 쿼리 실행 파이프라인을 두 가지 주요 방식으로 확장합니다:
- 2차 랭킹 (Secondary Ranking):
- 초기 BM25 또는 RRF로 순위가 매겨진 결과 집합에 대해 다국어 심층 학습 모델을 사용하여 2차 랭킹을 수행합니다.
- 문맥이나 시맨틱 의미를 기반으로 가장 관련성 높은 결과를 선택하여 우선시합니다.
- 캡션 및 답변 추출 (Captions and Answers Extraction):
- 문서에서 가장 관련성 높은 문장과 구절을 추출하여 캡션과 하이라이트로 반환합니다.
- 질문처럼 보이는 쿼리에 대한 직접적인 답변을 제공하여 사용자의 검색 경험을 개선합니다.
시맨틱 랭킹의 주요 기능
| 기능 | 설명 |
| 시맨틱 랭킹 (Semantic Ranking) | 쿼리의 문맥 또는 시맨틱 의미를 사용하여 사전 순위가 매겨진 결과에 대해 새로운 관련성 점수를 계산합니다. |
| 시맨틱 캡션 및 하이라이트 (Semantic Captions and Highlights) | 문서에서 콘텐츠를 가장 잘 요약하는 문장과 구절을 추출하여 그대로 표시하며, 주요 구절에 하이라이트를 추가하여 쉽게 스캔할 수 있도록 합니다. |
| 시맨틱 답변 (Semantic Answers) | 질문처럼 보이는 쿼리에 대한 직접적인 답변을 제공합니다. 문서에 답변의 특성을 가진 텍스트가 있어야 합니다. |
시맨틱 랭킹의 작동 방식 요약
- 입력 수집 및 요약: 초기 BM25 또는 RRF로 순위가 매겨진 결과 집합을 요약하고, 최대 2,000개의 토큰으로 입력을 구성합니다. 요약 문자열은 최대 256개의 토큰으로 제한됩니다.
- 점수 매기기: 요약 문자열의 시맨틱 관련성을 평가하여 @search.rerankerScore를 부여합니다. 점수는 4에서 0까지의 범위로, 높은 점수가 더 높은 관련성을 나타냅니다.
- 출력 구성: 가장 관련성 높은 결과를 캡션과 답변 형태로 구성하여 사용자에게 제공됩니다.
시맨틱 랭킹을 통해 검색 결과의 품질을 향상시키고, 사용자에게 더욱 직관적이고 유용한 검색 경험을 제공합니다.

예시 설명
다음 그림은 문맥을 위한 벡터 표현을 설명합니다.
- "capital"이라는 단어는 여러 의미를 가질 수 있습니다.
- 금융(Finance) 문맥: 세금, 돈, 투자, 자본 이득, 재정
- 법(Law) 문맥: 범죄, 처벌
- 지리(Geography) 문맥: 주, 상태, 건물, 국가
- 문법(Grammar) 문맥: 대문자
시맨틱 랭커는 이러한 다양한 문맥을 이해하고, 질의와 가장 관련성이 높은 결과를 우선시할 수 있습니다.
Diagram of a search scoring workflow
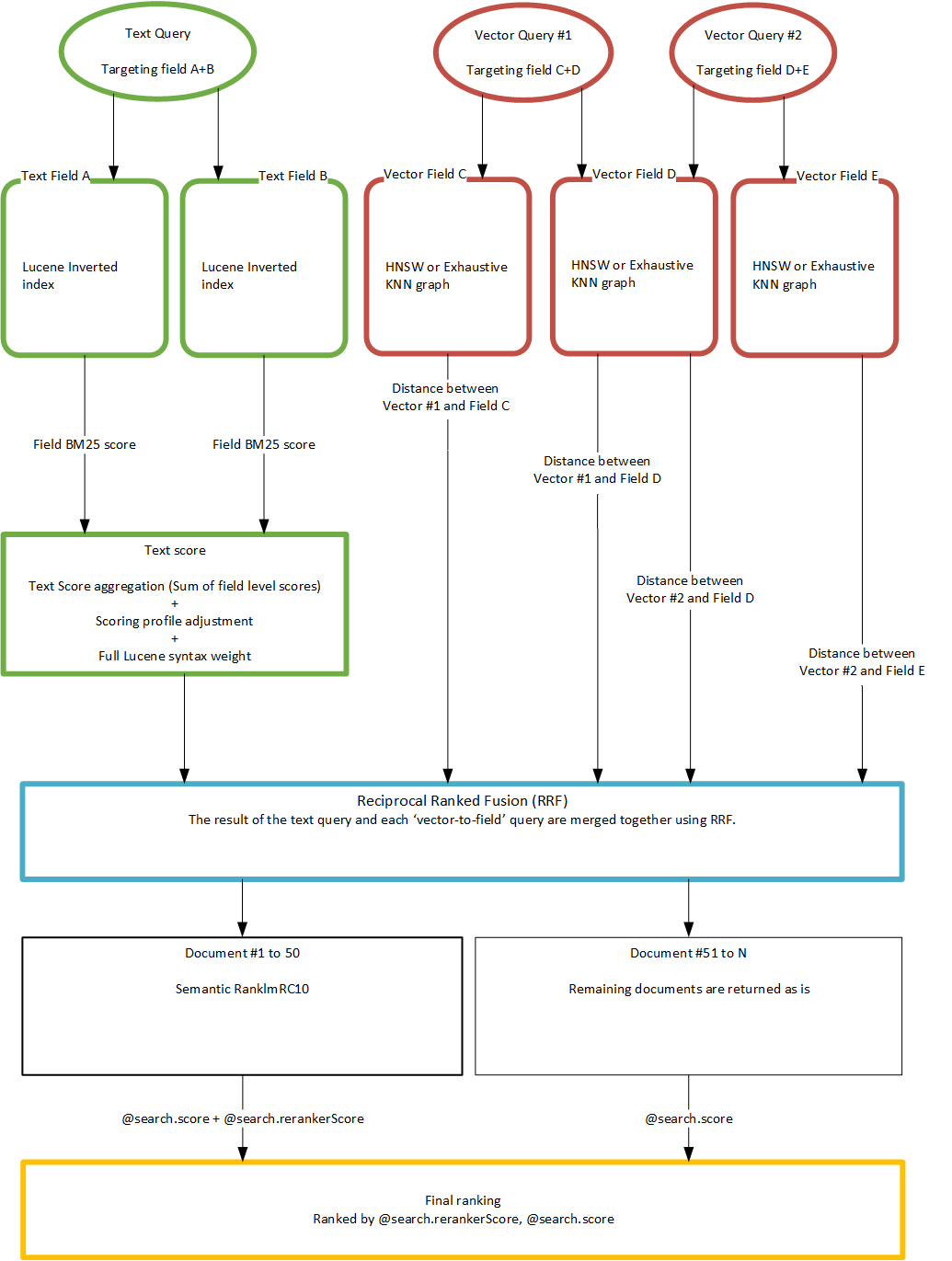
그래서 Semantic Ranking 은 Azuere AI Search에서 제공하는 것이고 실제로 저걸 사용하기 위해선 비슷한 Reranker라는 것을 활용해야 할 것 같다.
Reranker
리랭킹 모델(또는 크로스-인코더)은 주어진 쿼리와 문서 쌍에 대해 유사성 점수를 출력하는 모델입니다. 이 점수를 사용하여 문서를 쿼리와의 관련성에 따라 재정렬합니다.
두 단계 검색 시스템 (Two-Stage Retrieval System)
검색 엔지니어들은 오랜 기간 동안 두 단계 검색 시스템에서 리랭커를 사용해 왔습니다. 이러한 시스템에서는 첫 번째 단계 모델(임베딩 모델 또는 검색기)이 더 큰 데이터 세트에서 관련 문서 세트를 검색합니다. 그런 다음 두 번째 단계 모델(리랭커)이 첫 번째 단계 모델이 검색한 문서를 재정렬합니다.
두 단계 시스템을 사용하는 이유는 큰 데이터 세트에서 작은 문서 세트를 검색하는 것이 많은 문서를 재정렬하는 것보다 훨씬 빠르기 때문입니다. 리랭커는 느리고 검색기는 빠릅니다.
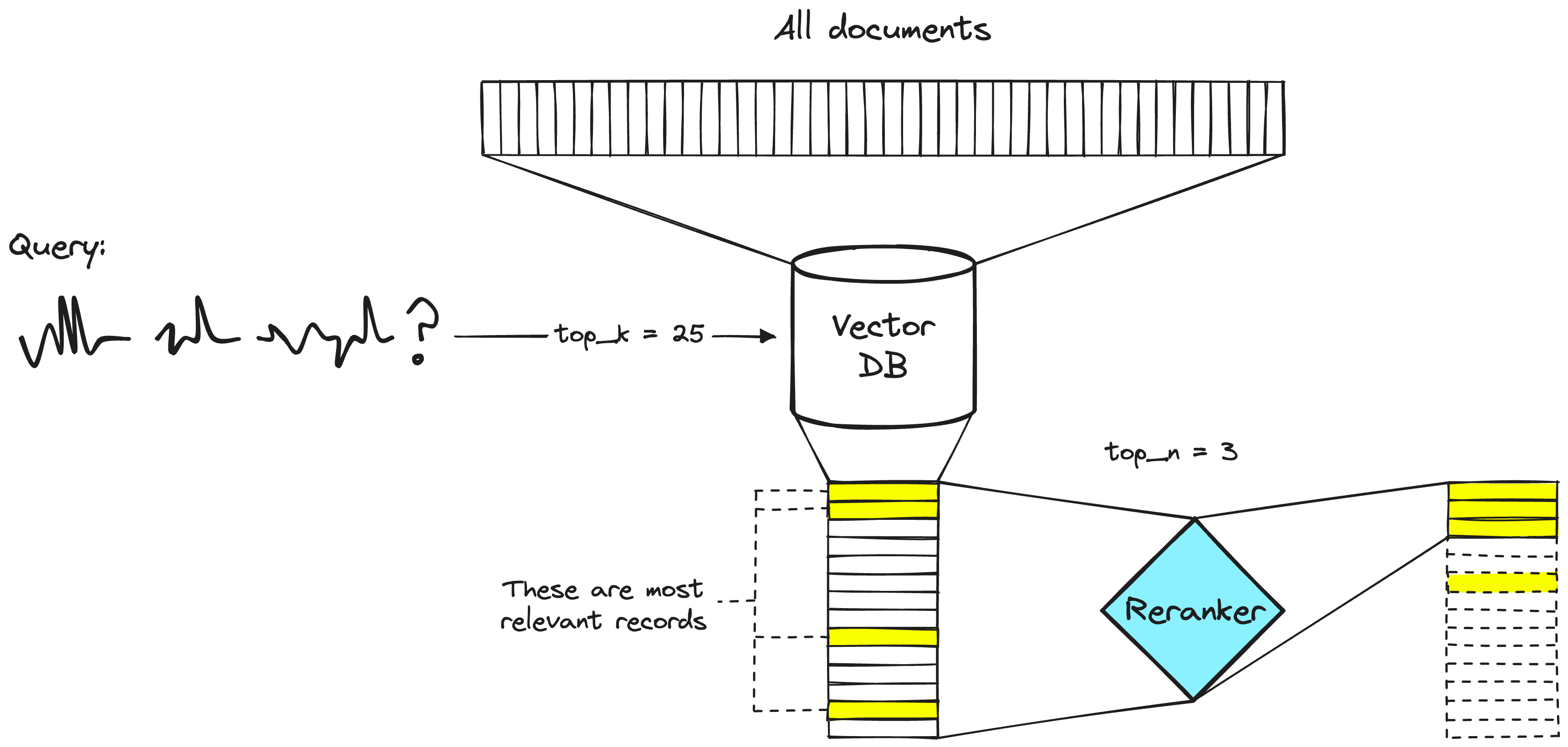
사용 이유
여기서 보게 되면 검색을 많이 하게 해서 답변의 성능을 높이려고 하면, 현재 알고리즘의 구조 적인 한계로 인해서, 모든 문서를 잘 탐색하지 못하고 문서의 위치 자체도 중요한 것을 알 수 있습니다.
그래서 이러한 구조적인 문제로 뽑힌 문서의 위치도 잘 설정하는 것이 중요하고 그때 Ranker 방식을 사용해서 문서를 정렬시킬 수 있습니다.
리랭커가 느리다면, 왜 사용하는 걸까요? 답은 리랭커가 임베딩 모델보다 훨씬 더 정확하기 때문입니다.
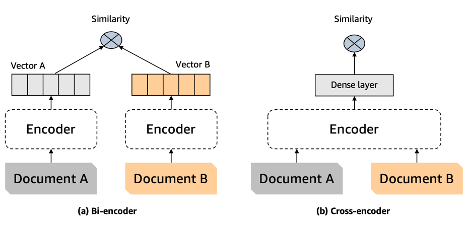
Bi-Encoder의 한계:
바이-인코더는 문서의 모든 가능한 의미를 하나의 벡터로 압축해야 하므로 정보 손실이 발생합니다.
또한, 바이-인코더는 쿼리를 받기 전에는 쿼리에 대한 문맥을 알 수 없습니다(임베딩은 사용자 쿼리 시간 전에 생성됨).
Rerak (Crodss Encoder)의 장점:
리랭커는 쿼리 시간에 문서의 의미를 분석하여 사용자 쿼리에 맞춘 의미를 도출할 수 있습니다.
이로 인해 정보 손실이 줄어듭니다. 하지만 리랭커는 시간이 많이 소요됩니다.
Bi-Encoder와 리랭커의 비교
바이-인코더 모델: 문서나 쿼리의 의미를 하나의 벡터로 압축합니다. 초기 벡터 생성 시점에 모든 무거운 변환 계산을 완료하고, 사용자 쿼리 시간에는 단일 변환 계산과 벡터 비교(코사인 유사도 등)만 수행합니다.
리랭커 모델: 사전 계산 없이 쿼리와 문서를 변환 모델에 입력하고, 전체 변환 추론 단계를 거쳐 단일 유사성 점수를 출력합니다. 리랭커는 쿼리와 문서 쌍에 대해 실시간으로 추론을 수행합니다.
예시 코드
아래는 `what is panda` 라는 질의가 왔을 때 2개의 pari의 유사도를 계산하는 코드입니다.
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
결론
이번 내용을 통해 RAG 시스템에서 자주 물어보는 질문의 유형을 알게 되었고, 효율적인 검색을 위해 현재는 키워드 검색과 벡터 검색을 사용하여 하이브리드 방식을 채택하는 경우가 많다는 것을 알게 되었습니다.
하지만 이렇게 하면 많은 문서를 검색할 수 있지만, 문서의 순서가 검색 결과의 품질에 큰 영향을 미치는 구조적인 문제가 있습니다.
이를 해결하기 위해 Azure에서는 시맨틱 검색(Semantic Search) 방식을 도입하고 있으며, 일반적으로 리랭커(Ranker)를 사용하여 검색된 문서의 순위를 재정렬하거나 필터링하여 성능을 향상하는 방법을 채택합니다.
이러한 접근 방식은 고급 RAG 시스템에서 포스트 리트리벌(Post-Retrieval) 단계와 관련이 있으며, 현재 Transformer 구조의 LLM 모델에서 어텐션(Attention) 메커니즘의 개선이 없는 한, 이러한 랭크 방식은 검색 성능을 향상하기 위해 필요할 것입니다.
또한, 데이터를 큰 청크로 나누어 관리하고 의미 있는 단위로 묶는 것이 중요하다고 생각했으나, 리랭킹 방식을 보고 최대한 유사한 결과를 도출하고 순위를 조정하는 것이 더 중요하다는 것을 알게 되었습니다.
따라서 청크의 의미적인 묶음보다는 유사성을 높이는 것이 검색 성능에 더 유리할 수 있다고 생각하고 시도해볼만한 방법인 것 같습니다.
참고
|
|
https://techcommunity.microsoft.com/t5/ai-azure-ai-services-blog/azure-ai-search-outperforming-vector-search-with-hybrid/ba-p/3929167 |
| Semantic ranking in Azure AI Search | https://learn.microsoft.com/en-us/azure/search/semantic-search-overview |
| LlamaIndex: Enhancing Retrieval Performance with Alpha Tuning in Hybrid Search in RAG | https://medium.com/llamaindex-blog/llamaindex-enhancing-retrieval-performance-with-alpha-tuning-in-hybrid-search-in-rag-135d0c9b8a00 |
| Relevance scoring in hybrid search using Reciprocal Rank Fusion (RRF) | https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking |
| 한국어 Reranker를 활용한 검색 증강 생성(RAG) 성능 올리기 | https://aws.amazon.com/ko/blogs/tech/korean-reranker-rag/ |
| https://huggingface.co/BAAI/bge-reranker-large | |
| https://www.purpleslate.com/the-ultimate-guide-to-understanding-advanced-retrieval-augmented-generation-methodologies/ |
'관심있는 주제 > LLM' 카테고리의 다른 글
| 논문 정리) Searching for Best Practices in Retrieval-Augmented Generation (0) | 2024.07.05 |
|---|---|
| LangGraph) LangGraph에 대한 개념과 간단한 예시 만들어보기 (0) | 2024.06.29 |
| LLM) HuggingFace 에 사용하는 Tokenizer 의 결과 비교하는 Streamlit APP (0) | 2024.06.01 |
| LLM) Quantization 방법론 알아보기 (GPTQ | QAT | AWQ | GGUF | GGML | PTQ) (0) | 2024.04.29 |
| LLM) Chat Vector 논문 내용 및 실험해보기 (2) | 2024.04.26 |