2020. 12. 24. 00:38ㆍ관심있는 주제/뉴럴넷 질문
첫 번째 에폭부터 트레이닝 로스는 감소하지만, 검증 로스는 올라가는 경우 어떻게 해야 할 까?
보통 이런 경우에는 일반화가 되지 않는 경우를 크게 2가지로 나눌 수 있다고 함.
Aleatory Uncertainty
흔히 알고 있는 오버 피팅이라고 불리는 것은 aleatory uncertanity라는 현상이다.
즉, 노이즈 데이터로부터 발생되는 오버 피팅이다.
기존 생성 프로세스에다가 랜덤을 다음과 같이 추가할 수 있다.
$$\tilde y = y+n$$
n은 noise 값으로 임의적인 확률분포를 따른다고 가정한다.
분명 실제 데이터에서는 랜덤 성이 발생하는 메커니즘은 더 복잡할 것이다.

오버 피팅의 영향을 설명하기 위해서, 기존에 생성 프로세스보다 더 고차원의 polynomial로 적합할 것이다.
여기서는 4차 다항식 회귀를 해보면 다음과 같다.
$$y=ax^4 + bx^3 + cx^2+dx + \epsilon$$
이 예제에서 예측된 값$\hat y$ 와 잡음이 섞인 실제값 사이의 평균 거리를 손실로 정의했다.
목표는 평균 거리를 최소화하는 모델을 접한 및 훈련시키는 것이다.

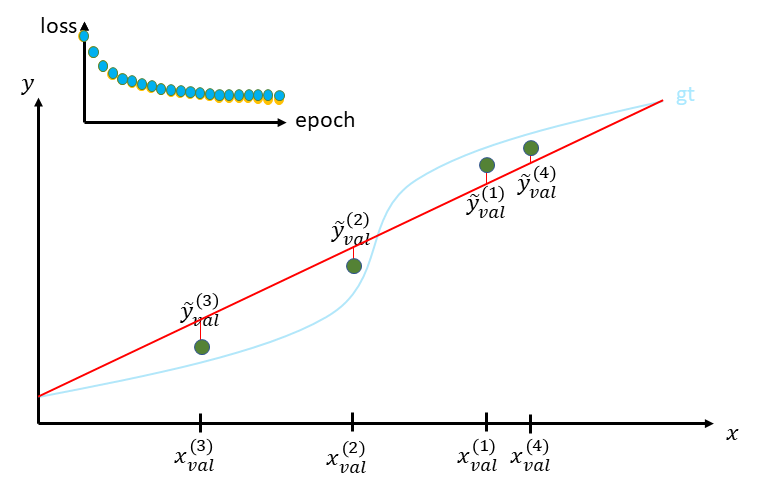
몇 번의 epoch을 거치다 보면, 위의 그림처럼 noise에 적응하게 시작한다.
실제로 그런 식으로 학습하게 했으니 이러한 결과는 놀라운 일이 아닐 것이다. 이로 인해서 실제 값과의 차이는 점점 더 커지게 된다.
훈련 후에, 아래와 같이 training loss는 0에 가까워지는 이유는 빨간 선은 4개의 점 만만 정확히 거치게 되기 때문이다.
그러나 적합 모델의 일반화 능력에 대해 아무것도 말하지 않으므로 낮은 훈련 손실에 속지 말라고 한다.
실제 상황이 얼마나 나쁜지는 검증 세트에서 평가된 손실을 살펴보면 분명해진다.
그래서 실제로 training loss보다 validation loss가 더 커진다. 이것은 바로 우리 모델이 지금 오버 피팅을 하고 있다는 강력한 힌트라고 한다.
첫 번째 인사이트로는 우리가 작은 데이터셋에서 neural network를 훈련시키려고 할 때, 데이터의 일반적은 구조를 학습하는 대신에, 트레이닝 데이터셋을 기억하려고 하는 현상이 발생한다.
이러한 이유로 모델은 트레이닝 데이터셋에서는 잘하지만, 새로운 데이터에는 성능이 좋지 않다.

그렇다면 우리는 overfitting인 것을 알았을 때 어떻게 해야 할까?
Solutions: More data
가장 어려우면서 쉬운 방법은 데이터를 늘리는 것이다. 4 차 다항식의 능력은 8 개의 훈련 포인트를 모두 정확하게 통과하기에 충분하지 않습니다. 그러므로 이 전거 다르게 노이즈에 적응할 수가 없다. 그래서 더 좋은 성능을 내게 된다.

그래서 이상향은 아래와 같이 둘 다 감소하는 방향이다.

충분히 많은 양의 데이터로 훈련시키면, 트레이닝과 validation이 낮아질 것이다.
그리고 그 2개의 갚은 위의 그림처럼 유사 해질 것이다.
실제로 데이터를 더 모을 수 있다면 분명히 좋은 해결책이 되지만, 실제로 데이터를 모으는 것은 비싸며,. 어려운 작업입니다. 데이터를 추가해도 최종 골을 달성하지 못했다면, 아래와 같은 방법이 있습니다.
Solutions: Reducing model’s capacity
바로 capacity를 줄이는 것은 알다시피 정규화를 적용하는 것이다.

capacity가 감소된 모델에서는 트레이닝 데이터에 포함되어 있는 noise를 적응할 수 있게 된다.
그러므로, 보지 않은 데이터에서 일반화를 더 잘할 수 있게 된다.
그러나 위의 그림처럼 적합된 모델이 capacity로 인해서 실제 블루 라인을 잘 반영하지 못했다.
이 방법론에는 L1 , L2 ,. SN 등등이 있다.
또 다른 흥미로운 것으로는 Dropout이 이 있다.
Solutions: Early stopping
학습시, 정규화 기술중 하나인 early stopping을 쓸 수 있다.
초기 학습 때에는 네트워크의 가중치는 매우 작은 값으로 초기화될 것이고, 그러므로 모든 중간 결과(layer안에서)는 활성 함수의 선형 지역에서 작동할 것이다.
전체적인 네트워크는 마치 선형 시스템처럼 작동하여, 용량이 제한될 것이다.

에폭이 지남에 따라서, 가중치는 보통 크기가 커진다.
이제 중간 출력이 활성화 함수의 비선형 영역에서 작동하기 시작하고 네트워크 용량이 약간 증가하게 된다.
validation 셋이 성능이 나빠지기 시작할 때, 모델에서 학습하는 것을 즉각적으로 멈춰야한다.
초기 예제에서는 작은 데이터 셋에서 4차 함수에 early stopping을 적용하면 다음과 같이 될 것이다.

Solutions: Data augmentation
TO BE CONTINUE...
towardsdatascience.com/aleatory-overfitting-vs-epistemic-overfitting-d0f06a60b993
Aleatory Overfitting vs. Epistemic Overfitting
Approaching the two reasons why your model is not able to generalize well
towardsdatascience.com
'관심있는 주제 > 뉴럴넷 질문' 카테고리의 다른 글
| Cold-Start Challenge in Machine Learning Models (0) | 2021.03.12 |
|---|---|
| Google’s RFA: Approximating Softmax Attention Mechanism in Transformers 간단하게 알아보기 (0) | 2021.03.01 |
| [TIP] CNN) BatchNormalization, Dropout, Pooling 적용 순서 (0) | 2020.10.31 |
| Causual Inference 관련 자료 모으기 (1) | 2020.10.26 |
| [Review / NN] Cyclical Learning Rates for Training Neural Networks 논문 (0) | 2020.10.21 |