learning rate 같은 경우에 우리가 뉴럴 네트워크를 학습시킬 때 알고 싶어 하는 중요한 파라미터 중에 하나이다.
learning rate 를 어떻게 하냐에 따라서 weight 업데이트의 크기가 달라지기 때문이다.
그래서 실제로 관련된 논문을 찾게 되었고, 마침 코드도 있어서 공유한다.
Find optimal starting learning rate
아래 그럼 처럼 너무 작게도 크게도 안 좋은 것을 알 수 있다.
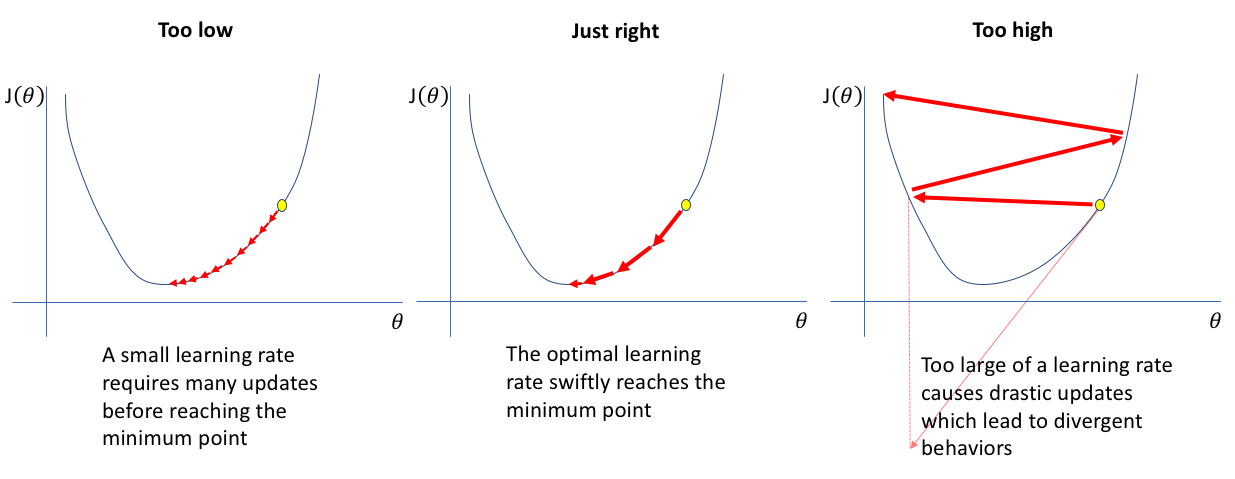
보편화된 최적 learning rate 라는 것은 없다고 할 수 있다.
그래서 보통은 손실 함수에서 유의미한 감소를 줄 수 있는 learning rate를 찾고자 한다.
이러한 learning rate를 찾기위한 체계적인 접근 방식은 학습률이 다른 손실 변화의 크기를 관찰하는 것입니다.
그래서 체계적인 증가 방식에서 linearly나 exponentially가 잇다.
2 가지고 방법이 있는데, linearly (suggested by Leslie Smith) or exponentially (suggested by Jeremy Howard)라고 한다.

미니 배치를 수행 한우, 각 증가되는 시점에서 기록을 한다.
실제로 손실이 변경되는 부분인 optimal learning rate range 사이에서 결정하자는 것이 저 논문이 말하고자 하는 것이다.
Learning rate annealing
훈련 과정에서 학습률이 변하지 않으면 수렴하기에는 너무 커서 손실 함수가 로컬 최솟값 주변에서 변동될 수 있습니다.

Cyclical Learning Rates

이론적 근거는 학습률을 높이면 현재 영역이 "스파이 키"인 경우 모델이 가중치 공간의 다른 부분으로 점프하도록 강제하기 때문입니다.

다시 말하자면, 현재 최소가 강건하지 않다면, 다른 로컬 최솟값을 찾게 되는 것을 강요할 것이다.

import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
try:
from torch_lr_finder import LRFinder
except ImportError:
# Run from source
import sys
sys.path.insert(0, '..')
from torch_lr_finder import LRFinder
mnist_pwd = "../data"
batch_size= 256
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
trainset = MNIST(mnist_pwd, train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=0)
testset = MNIST(mnist_pwd, train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=batch_size * 2, shuffle=False, num_workers=0)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = Net()
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.5)
lr_finder = LRFinder(model, optimizer, criterion, device="cuda")
lr_finder.range_test(trainloader, end_lr=10, num_iter=100, step_mode="exp")
lr_finder.plot()
lr_finder.range_test(trainloader, val_loader=testloader, end_lr=10, num_iter=100, step_mode="exp")
Cyclical Learning Rates for Training Neural Networks
It is known that the learning rate is the most important hyper-parameter to tune for training deep neural networks. This paper describes a new method for setting the learning rate, named cyclical learning rates, which practically eliminates the need to exp
arxiv.org
github.com/davidtvs/pytorch-lr-finder
davidtvs/pytorch-lr-finder
A learning rate range test implementation in PyTorch - davidtvs/pytorch-lr-finder
github.com
'관심있는 주제 > 뉴럴넷 질문' 카테고리의 다른 글
| [TIP] CNN) BatchNormalization, Dropout, Pooling 적용 순서 (0) | 2020.10.31 |
|---|---|
| Causual Inference 관련 자료 모으기 (1) | 2020.10.26 |
| [Review / NN] SuperTML / 정형데이터를 CNN에 적용하기(Transfer Learning) (0) | 2020.10.16 |
| Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data - 리뷰 (0) | 2020.03.21 |
| Graph Neural Networks 이란? (파파고 번역) (3) | 2020.02.16 |