What is Attention Mechanism & Why is RFA better than Softmax?
이 글에서는 Attention Mechanism은 무엇이며, softmax보다 저자가 주장한 RFA가 더 나은지 알아보는 글입니다.
RANDOM FEATURE ATTENTION paper
openreview.net/pdf?id=QtTKTdVrFBB
구글은 최근 새로운 방법을 출시했습니다.(Random Feature Attention)
RFA란 기존보다 유사하거나 더 나은 성능을 달성하기 위해 transformer의 softmax주의 메커니즘을 시간 및 공간 복잡성의 상당한 개선한 것입니다.
이 블로그 글에서는, transformer의 배경을 알아보고, attention mechanism이 무엇인지, 왜 RFA가 softmax주의 메커니즘에 대한 더 나은 대안인지 살펴볼 것입니다. RFA의 몇 가지 요약으로 블로그를 마무리하겠습니다.
Background
트랜스포머는 현재 시퀀스-투-시퀀스 머신 러닝 모델의 가장 좋은 유형입니다.
데이터 시퀀스에서 학습하는 데 특화되어 있다는 사실은 자연어 처리, 기계 번역, 시계열 모델링 및 신호 처리에 특히 유용합니다. 트랜스포머 성공의 초석은 attention mechanism입니다. 이러한 메커니즘은 입력 시퀀스를 조사하고 가장 중요한 요소를 식별합니다. 이러한 요소는 시퀀스를 인코딩할 때 더 많은 가중치를 갖게 됩니다.

What is Attention Mechanism in plain English?
후속 이메일을 작성하기 위해 회의에서 메모를 작성하는 것처럼 생각하십시오.
메모를 할 때 모든 것을 적을 수 있을 것 같지 않습니다. 단어를 약어나 그림으로 대체해야 할 수도 있습니다.
의미 손실을 최소화하면서 추론할 수 있는 단어를 건너뛰어야 할 수도 있습니다.
이 프로세스는 한 시간 동안의 회의를 한 페이지의 메모로만 나눕니다.
본질적으로, attention mechanism은 중요한 임베딩 (단어의 약어 또는 아이콘 표현)에 더 많은 주의를 기울여 시퀀스를 인코딩하려고 시도하는 동일한 작업을 수행합니다.
What is Softmax Attention Mechanism?
“What actually is Attention Mechanism”.라는 문장이 있자고 합시다.
attention mechansim의 목표는 시퀀스의 다른 부분이 서로 연결되어 동시에 주의를 기울여야 하는 방법에 대한 상대성 행렬을 계산하는 것입니다.
예를 들어 attention과 mechanism은 함께 연결되어야 하며 둘 다 "실제로"또는 "있다"와 크게 연결되어서는 안 됩니다.
이 메커니즘은 입력 문장의 숫자 형식, 즉 단어 임베딩(word embedding) 행렬을 수집하는 것으로 시작됩니다.
Word embedding is a vector representation of a word that catpures different attributes of that word. An oversimplied example of these attributes can be sentiment, part-of-speech, and number of characters.
그런 다음 쿼리 행렬 Q, 키 행렬 K 및 값 행렬 V를 각각 W_q, W_k 및 W_v를 사용하는 단어 임베딩 행렬의 내적 값으로 계산할 수 있습니다. 주의가 필요한 모든 문서에 설명된 대로 초기 주의 매트릭스는 다음과 같이 계산할 수 있습니다.

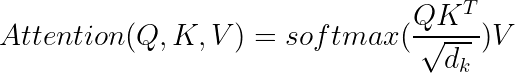
이 matrix의 연산을 이해하기 위해서는 아래의 flow를 이해하면 좋다.

이 attention은 소프트 맥스 활성화 함수를 사용하여 Q와 K의 스케일링된 내적을 어텐션의 상대적 측정값 A로 변환하기 때문에 soft max attention이라고도 합니다.
(또는 100 %). 그런 다음 소프트 맥스 결과는 V와 결합되어 어텐션 기반 시맨틱 결과를 제공합니다.
But what are query, key, and value?
query, key, value이 직관적으로 간단하게 이해하는 방법은 문장을 이해하는 transformer의 능력을 다음 조건부 가능성을 최대화하는 것을 취급하는 것이다.
- Probability of y = “What” when the input sequence is [y, "actually", "is", "attention", "mechanism"]
- Probability of y = “actually” when the input sequence is ["what", y, "is", "attention", "mechanism"]
- Probability of y = “is” when the input sequence is ["what", "actually", y, "attention", "mechanism"]
- Probability of y = “attention” when the input sequence is ["what", "actually", "is", y, "mechanism"]
- Probability of y = “actually” when the input sequence is ["what", "actually", "is", "attention", y]
그리고 가능성을 추론하는 방법은 입력 문장에서 다른 단어 (단어 임베딩)에 주의를 기울이는 것입니다.
훈련 과정에서 transformer는 세 가지 가중치 행렬을 구체화하여 임베딩을 기반으로 단어를 함께 연결하는 방법에 대해 학습합니다.
이 아키텍처의 좋은 점은 query, key, value의 다양한 셋을 만듦으로써, 복잡한 semantic 찾을 수 있다는 것입니다.
(multi-headed attention)
Why is the Softmax Attention Mechanism not good enough?
전형적인 transformer에서, Multi-Headed Attention은 복잡한 언어 패턴을 unpickle 하기 위해 배포됩니다.
softmax attention mechanism의 시간과 공간 복잡성은 O(MN)이 된다. sequence length의 quadratic rate로 증가하게 된다.
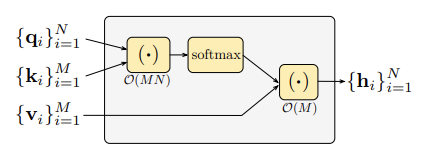
이것을 주장하기 위해서 google deepmind 팀은 Bochner 이론을 활용하고, Rahmi & Recht의 작업을 확장하여 임의의 특성 맵(독립적으로 내부 곱의 푸리에 특성)을 사용하여, 소프트맥스 함수의 지수 함수를 추정했습니다.
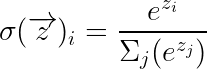


도출의 수학적 세부 사항을 너무 많이 살펴보지 않고 소프트 맥스 주의 메커니즘은 다음 구조로 근사화할 수 있습니다.

RFA로 softmax를 근사화함으로써, google deepmind는 time과 space 복잡성을 감소할 수 있게 된다 O(M+N)
| Softmax Attention Mechansim | RFA attention Mechanism |
| O(MN) | O(M+N) |

Google Deepmind’s 연구 결과
- RFA는 같은 인풋과 아웃풋 차원을 RFA에는 동일한 입력 및 출력 차원 요구 사항이 있으므로 RFA는 softmax주의 메커니즘을 대체하는 데 사용할 수 있습니다.
- quadratoc에서 linear로 복잡성을 떨어지면서, RFA는 인풋 TEXT가 더 길 때, 더 유의미한 성능을 낼 수 있습니다.
- RFA한에서 이론적 해석은 Gaussian Kernel 아래에서 다른 커널 함수들을 근사화하는 데 사용합니다. 구글 딥마인드 논문에서 arc-cosine kernel을 근사함으로써, 샅은 접근을 어떻게 했는지 설명하고 있습니다.
- softmax처럼, RFA 자체는 입력 문장 내 위치 거리를 고려하지 않습니다. Google Deepmind의 논문에서 그들은 반복적인 신경망의 영감을 RFA에 적용하여 단어의 중요성이 문장에서의 상대적 위치에 따라 기하급수적으로 감소하는 방법에 대해 논의했습니다.

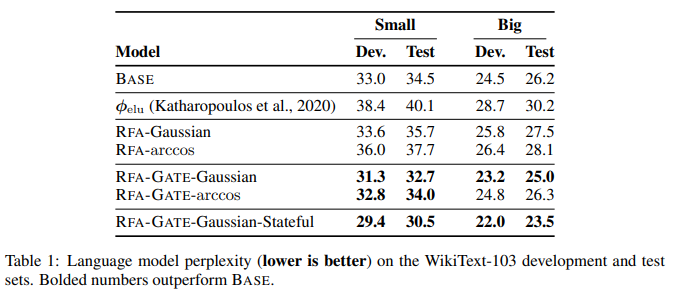

코드는 나중에 찾게 되고, 더 깊게 볼 때 참고하려고 한다.
Reference
1. blog.floydhub.com/attention-mechanism/
Attention Mechanism
What is Attention, and why is it used in state-of-the-art models? This article discusses the types of Attention and walks you through their implementations.
blog.floydhub.com
What exactly are keys, queries, and values in attention mechanisms?
How should one understand the keys, queries, and values that are often mentioned in attention mechanisms? I've tried searching online, but all the resources I find only speak of them as if the reader
stats.stackexchange.com
3. deepmind.com/research/publications/Random-Feature-Attention
'관심있는 주제 > 뉴럴넷 질문' 카테고리의 다른 글
| MLP-mixer 이해하기 (0) | 2021.05.08 |
|---|---|
| Cold-Start Challenge in Machine Learning Models (0) | 2021.03.12 |
| Aleatory Overfitting vs. Epistemic Overfitting (3) | 2020.12.24 |
| [TIP] CNN) BatchNormalization, Dropout, Pooling 적용 순서 (0) | 2020.10.31 |
| Causual Inference 관련 자료 모으기 (1) | 2020.10.26 |