728x90
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Test score")
plt.legend(loc="best")
plt.show()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)from sklearn.model_selection import PredefinedSplit
split_index = [-1 if x in X_train.index else 0 for x in X.index]
pds = PredefinedSplit(test_fold = split_index)pipe_mlp = make_pipeline(MLPClassifier(solver='adam',activation='tanh',
random_state=1))
plot_learning_curve(pipe_mlp,"Crash Learning", X, y,cv=pds)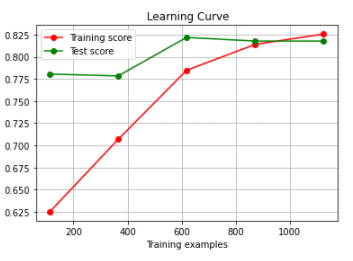
'분석 Python > Visualization' 카테고리의 다른 글
| python) histogram 알아보기 (0) | 2021.05.01 |
|---|---|
| python) treemap 알아보기 (0) | 2021.04.29 |
| [Visualization] keras 결과물(history) 시각화하는 함수 (0) | 2020.11.21 |
| [Visualization] x 축에 있는 margin 제거하기 (2/2) (0) | 2020.11.19 |
| [Visualization] x 축에 중복된 이름 잘 시각화하기 (xticks) (1/2) (1) | 2020.11.19 |