최근에 on policy와 off policy learning의 차이점에 대한 의견을 나눌 때 잘 몰라서 가만히 있었다.
그래서 궁금해서 찾아보니 헷갈리는 사람이 또 있는 것 같았다.

그 사람은 Artificial intelligence 책에서 이렇게 설명하는데 차이점을 이해를 못하겠다고 한다.
"An off-policy learner learns the value of the optimal policy independently of the agent's actions. Q-learning is an off-policy learner. An on-policy learner learns the value of the policy being carried out by the agent including the exploration steps."
답변에서는 greedy action으로 on-policy / off-policy learning을 구별하는 것은 아니라고 하면서 다음과 같이 말합니다.
The reason that Q-learning is off-policy is that it updates its Q-values using the Q-value of the next state s′s′ and the greedy action a′a′. In other words, it estimates the return (total discounted future reward) for state-action pairs assuming a greedy policy were followed despite the fact that it's not following a greedy policy.
Q-Learning은 next state $S`$ 와 greedy action $A`$의 Q-value를 사용하기 때문에 off-policy라고 합니다.
다시 말해, greedy action을 따르지 않는다는 사실에도 불구하고 greedy action을 따른다고 가정할 때 state-action 쌍에 대한 보상 (총 할인된 미래 보상)을 추정합니다.
SARSA가 on-policy인 이유는 next state의 $S`$ 와 현재 policy action $A``$의 Q-value를 사용하여 업데이터 하기 때문이라 합니다. 현재 정책을 계속 따른다고 가정하면 state-action 쌍에 대한 수익을 추정합니다.



즉 현재 policy이 greedy policy 인 경우 구별이 사라집니다. 그러나 그러한 에이전트는 탐색하지 않기 때문에 좋지 않습니다.


추가 내용)
On-policy vs Off-Policy
These are more specific to control systems and RL. Despite the similarities in name between these concepts and online/offline, they refer to a different part of the problem.
-
On-policy algorithms work with a single policy, often symbolised as π, and require any observations (state, action, reward, next state) to have been generated using that policy.
-
Off-policy algorithms work with two policies (sometimes effectively more, though never more than two per step). These are a policy being learned, called the target policy (usually shown as ππ), and the policy being followed that generates the observations, called the behaviour policy (called various things in the literature - μμ, ββ, Sutton and Barto call it bb in the latest edition).
- A very common scenario for off-policy learning is to learn about best guess at optimal policy from an exploring policy, but that is not the definition of off-policy.
- The primary difference between observations generated by bb and the target policy ππ is which actions are selected on each time step. There is also a secondary difference which can be important: The population distribution of both states and actions in the observations can be different between bb and ππ - this can have an impact for function approximation, as cost functions (for e.g. NNs) are usually optimised over a population of data.
In both cases, there is no requirement for the observations to be processed strictly online or offline.
In contrast to the relationship between online and offline learning, off-policy is always a strict generalisation of on-policy. You can make any off-policy algorithm into an equivalent on-policy one by setting π=bπ=b. There is a sense in which you can do this by degrees, by making bb closer to ππ (for instance, reducing ϵϵ in an ϵϵ-greedy behaviour policy for bb where ππ is the fully greedy policy). This can be desirable, as off-policy agents do still need to observe states and actions that occur under the target policy - if that happens rarely because of differences between bb and ππ, then learning about the target policy will happen slowly.
- Target Policy pi(a|s): It is the policy that an agent is trying to learn i.e agent is learning value function for this policy.
- Behavior Policy b(a|s): It is the policy that is being used by an agent for action select i.e agent follows this policy to interact with the environment.
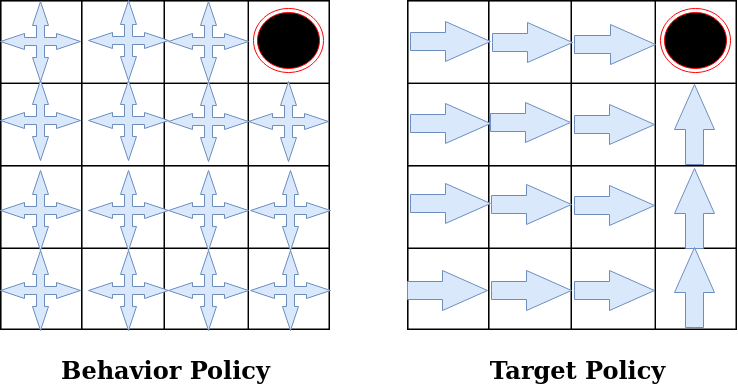
On-Policy learning :
On-Policy learning algorithms are the algorithms that evaluate and improve the same policy which is being used to select actions. That means we will try to evaluate and improve the same policy that the agent is already using for action selection. In short , [Target Policy == Behavior Policy]. Some examples of On-Policy algorithms are Policy Iteration, Value Iteration, Monte Carlo for On-Policy, Sarsa, etc.
Off-Policy Learning:
Off-Policy learning algorithms evaluate and improve a policy that is different from Policy that is used for action selection. In short, [Target Policy != Behavior Policy]. Some examples of Off-Policy learning algorithms are Q learning, expected sarsa(can act in both ways), etc.
Note: Behavior policy must cover the target policy i.e pi(a|s) > 0 where b(a|s) > 0.
## on policy의 경우 action에 대해서 argmax 값을 취한다.
def run_episode(env, Q, epsilon, n_action):
"""
Run a episode and performs epsilon-greedy policy
@param env: OpenAI Gym environment
@param Q: Q-function
@param epsilon: the trade-off between exploration and exploitation
@param n_action: action space
@return: resulting states, actions and rewards for the entire episode
"""
state = env.reset()
rewards = []
actions = []
states = []
is_done = False
while not is_done:
probs = torch.ones(n_action) * epsilon / n_action
best_action = torch.argmax(Q[state]).item()
probs[best_action] += 1.0 - epsilon
action = torch.multinomial(probs, 1).item()
actions.append(action)
states.append(state)
state, reward, is_done, info = env.step(action)
rewards.append(reward)
if is_done:
break
return states, actions, rewards## 여기서 greedy imporvement 방법인 $\epsilon$-greedy 방법을 도입하면 다음과 같이 된다.
def run_episode(env, Q, epsilon, n_action):
"""
Run a episode and performs epsilon-greedy policy
@param env: OpenAI Gym environment
@param Q: Q-function
@param epsilon: the trade-off between exploration and exploitation
@param n_action: action space
@return: resulting states, actions and rewards for the entire episode
"""
state = env.reset()
rewards = []
actions = []
states = []
is_done = False
while not is_done:
probs = torch.ones(n_action) * epsilon / n_action
best_action = torch.argmax(Q[state]).item()
probs[best_action] += 1.0 - epsilon
action = torch.multinomial(probs, 1).item()
actions.append(action)
states.append(state)
state, reward, is_done, info = env.step(action)
rewards.append(reward)
if is_done:
break
return states, actions, rewards하지만 이러한 방법에는 한계가 있다고 해서 나온 것이 Off-policy이고 여기에는 다음과 같은 장점이 았다고 함.
Silver교수님 강의자료에 따르면, Off-policy 방법은 다음과 같은 4가지의 장점
ㆍLearn from observing humans or other agents
ㆍRe-use experience generated from old policies π1, π2, ..., πt-1
ㆍLearn about Optimal Policy while following exploratory policy
ㆍLearn about multiple policies while following one policy
중요한 것은 3번째인데, exploration을 계속하면서도 optimal 한 policy를 학습할 수 있다는 것
## off policy의 경우 뽑힌 확률에 대해서 action에 대해서 랜덤하게 선택해서 뽑는다.
def run_episode(env, behavior_policy):
"""
Run a episode given a behavior policy
@param env: OpenAI Gym environment
@param behavior_policy: behavior policy
@return: resulting states, actions and rewards for the entire episode
"""
state = env.reset()
rewards = []
actions = []
states = []
is_done = False
while not is_done:
probs = behavior_policy(state)
action = torch.multinomial(probs, 1).item()
actions.append(action)
states.append(state)
state, reward, is_done, info = env.step(action)
rewards.append(reward)
if is_done:
break
return states, actions, rewards
www.youtube.com/watch?v=hlhzvQnXdAA&feature=youtu.be
What is the difference between off-policy and on-policy learning?
Artificial intelligence website defines off-policy and on-policy learning as follows: "An off-policy learner learns the value of the optimal policy independently of the agent's actions. Q-learn...
stats.stackexchange.com
https://newsight.tistory.com/250
On-policy와 Off-policy, Policy Gradient, Importance Sampling
# On-policy : 학습하는 policy와 행동하는 policy가 반드시 같아야만 학습이 가능한 강화학습 알고리즘. ex) Sarsa on-policy의 경우 1번이라도 학습을 해서 policy improvement를 시킨 순간, 그 policy가 했던..
newsight.tistory.com
https://analyticsindiamag.com/reinforcement-learning-policy/
On-Policy VS Off-Policy Reinforcement Learning: The Differences
It estimates the reward for future actions and appends a value to the new state without actually following any greedy policy.
analyticsindiamag.com
towardsdatascience.com/on-policy-v-s-off-policy-learning-75089916bc2f
On-Policy v/s Off-Policy Learning
Understanding Important Sampling for Off-Policy Learning
towardsdatascience.com
'관심있는 주제 > RL' 카테고리의 다른 글
| 강화학습 기초 자료 모음집 (0) | 2020.07.18 |
|---|---|
| Sarsa, Q-Learning , Expected Sarsa, Double Q-Learning 코드 비교하기 (2) | 2020.07.18 |
| 강화학습 Action-Selection Strategies for Exploration (0) | 2020.06.27 |
| Chapter 5 Monte-Carlo Learning 공부 (0) | 2020.05.16 |
| chapter 4 Dynamic Programming Example 도박사 문제 (0) | 2020.05.05 |