
이전에는 Dynamic Programming에 대해서 설명을 했고, Dynamic Programming에서 가지는 문제를 샘플링을 통해서 해결하는 Monte-Carlo 방식에 대해서 공부하고자 한다.

기존에 배운 Dynamic Programming은 MDP를 알고 있는 경우에 Bellman 방적식으로 풀어내서 GPI (Generalized Policy Iteration)을 따르는 방식으로 최적화 정책을 찾아냈습니다.
이제는 환경에 대한 정보를 알수 없는 즉 MDP를 알 수 없는 상황에서 환경과 직접적으로 상호작용하면서 경험을 통해서 학습하는 방식인 Model-free 방식에 대해서 말하고자 합니다.
Model-free에서 Prediction 과 Control은 다음과 같습니다.
Prediction은 가치(value)를 estimate(추정)하는 것을 말하는데, model-free에서 prediction은 MDP를 모르는 상태(즉 환경에 대한 사전 지식이 없는 상태)에서 환경과 상호 작용하여 가치 함수(value function)를 estimate(추정)해가는 방식을 말합니다.
Control은 Prediction에서 찾은 value function을 최적화하여 최적의 policy 를 찾는 것을 말합니다.
그리고 이러한 Model-free 방식에는 Monte-Carlo Learning과 Temporal-Difference가 있다고 합니다.

MC의 특징은 다음과 같습니다.
- MC는 Model-free 방식으로 MDP에 대한 transition 와 보상을 모르는 상태에서 시작합니다.
- MC(Monte-Carlo)는 샘플링된 에피소드로부터 학습하는 방법입니다.
- 상태 가치 $v_{\pi}(s)$는 정책 $\pi$에서 샘플링 된 에피소드로부터 평균 보상으로써 경험하여 학습합니다.
- 항상 에피소드가 종료가 되야 가치를 업데이트할 수 있습니다.(에피소드가 완료된 후에 업데이트하기 때문에 수렴 속도가 느립니다.)
- 그렇기 때문에 bootstrapping이 아닙니다.
- episodic 문제에서만 사용할 수 있습니다.
MC(Monte-Carlo)는 샘플링된 에피소드로부터 학습하는 방법입니다.

Monte-Carlo Learning의 목표와 보상 가치함수

에피소드를 진행하게 되면서 지나가게 되는 경로를 Trajectory라고 합니다. 즉 $s_1$에서 $a_1$을 취하면 $r_2$를 얻게 되고, 이런 식이 에피소드가 끝날 때까지 연속되게 얻은 것을 말합니다.
최종 G를 얻기 위해서 가치 함수(value function)을 정의하게 되는데, 기대된 이득(기대된 이득)을 말합니다.
Expected Return(기대된 이득)은 discounted된 모든 보상의 합을 의미합니다.

Expected Return 대신에 Monte Carlo 방법에서 정책을 따르는 것을 기반으로 한 샘플링된 것을 의미합니다.
MDP에서 미래에 받을 reward를 현재 가치로 discounted 하여 더한 값을 return이라 정의하고 value func은 state s에서 returnd의 기댓값이 정의했지만, model-free 방법에서는 MDP를 모르는 상태이고 그 중 하나의 방법론인 MC에서 Prediction은 하나의 에피소드를 마치고 얻은 return(이득)들의 평균값으로 value function을 근사하고 이를 반복해 true value function을 찾자는 것입니다.

위의 그림에서 임의의 policy에 대해 첫번쨰 state부터 teriminal state까지를 하나의 에피소드를 나타낸 그림이고 state를 이동할 때마다 얻은 reward들을 통해 각 state별 return 인 $G(s)$를 구할 수 있습니다.
이전 DP에서는 true value function을 구하기 위해서 여러 번의 iteration을 통해 value function을 업데이트했다면,
MC에서는 여러 episode를 진행하여 해당 state를 지나가는 episode에 return을 모두 구해서 산술 평균을 합니다. 이러한 return 값들이 episode 반복을 통해 여러 값들이 모이면 true value function으로 근사할 수 있게 됩니다.

N (s)는 total episode동안 state s를 방문한 횟수, G i(s)는 episode i에서 state s의 return값입니다.
MC 방법론을 적용한 예시
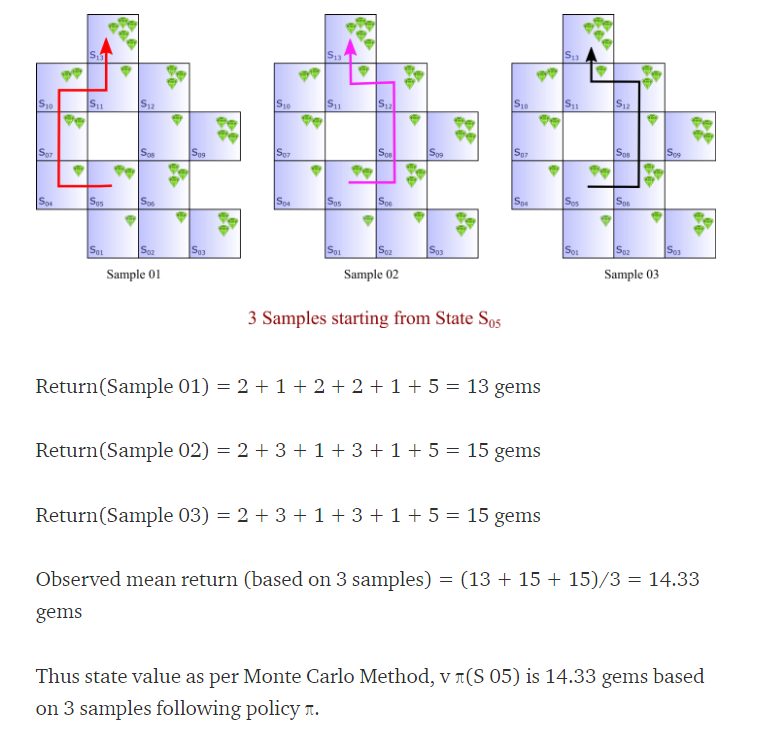
상태 가치(state value)를 얻기 위해서 agent는 어떤 state로부터 시작하여 각 에피소드 후에 얻어진 모든 보석을 합합니다. 그리고 그것을 각 에피소드에 대한 결과를 평균을 한 것이 Monte-Carlo의 상태 가치가 됩니다.
이제 이것이 averaging complete returns를 의미한다고 할 수 있습니다. 즉 value function을 얻을 때 agent는 sampling 한 state를 골라가며 terminal state까지 갑니다. 이때 받은 reward들을 저장해두었다가 시간 순서대로 discounting 하면 그것이 value function이 됩니다. DP에서는 Bellman equation으로 구했다면, MC에서는 reward의 합에 평균으로 value function을 근사한 것입니다.

위의 식을 하나의 state에 대해서만 생각한다고 했을 때 가장 최근에 얻은 보상 $G_n$만 분리해서 쓰면 다음과 같이 쓸 수 있습니다.

이 식을 좀 더 확장하면 다음과 같이 될 것입니다.
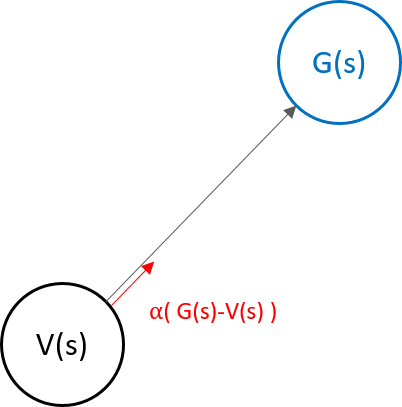
뒤에 식을 잘 조절하면 $V_n$으로 표현할 수 있게 되고 이전 상태 가치에서 다음 상태 가치로 업데이트하는 것을 나타낼 수 있습니다.

이 식을 보자면, return 값을 모두 모아서 평균을 하는 것이 아니라 얻을 때마다 update 하는 구조인 것을 알 수 있고, 아래와 같이 incremental mean 식으로 나타낼 수 있습니다.


위와 아래의 차이가 이런 식으로 보면 좀 더 차이가 나는 것을 알 수 있을 것입니다.

위에서 $\frac {1}{n}$은 step-size라고 하고 보통 $\alpha$로 합니다 그리고 $G(s)-V(s)$를 오차라고 합니다. 그래서 의미로 따지자면 value function이 G(s)라는 것을 타깃으로 하여 $\alpha $ x 오차만큼 update를 해서 다가가는 방식으로 학습한다는 것을 의미한다 할 수 있습니다.
(개인 생각)
(다음 가치 함수를 얻을 때 현재 얻은 보상을 중요하게 생각하여서 그만큼 반영하게 할 수 있게 한다는 느낌?...)
Backup diagram

이 상태 가치(state value)를 평가하는 방법은 크게 2가지가 있다고 합니다.
바로 First visit MC와 Every visit MC입니다.


(왼쪽 그림)
first visit mc는 에피소드에서 하나의 state를 여러 번 지나갈 수 있는데, 이때 해당 state를 첫번째 방문할 때만의 value만 사용한다는 것을 의미합니다. 에피소드가 여러번 진행을 하므로 각 에피소드에 대한 평균으로 가치(value)를 추정합니다. 에피소드가 충분히 많아지면, 즉 N이 커지면 평균값으로 추정한 value(가치)가 최적화된 실제 가치와 같게 되고, 이를 통해 policy 를 업데이트하면, 원하는 최적의 정책을 찾을 수 있게 된다는 방식입니다.
(오른쪽 그림)
every visit mc는 에피소드에서 하나의 state를 여러번 지나갈 수 있는데, 모든 value를 각각 사용하여 평균 내어 추정하는 방식입니다. 이것 말고는 first visit mc와 같은 뜻을 의미합니다.
First Visit Monte Carlo Method

13 + 5 + 15 = 33
위의 여러 군데를 빙글빙글 돌다가 terminal state $S_{13}$ 에 도달한 것인데, 그래서 첫 번째 방문한 것만 계산하는 것으로 할 때는 1번 방문한 것이 되니 3으로 나눠준다
Every Visit Monte Carlo Method

Every visit의 경우에는 같은 state를 여러 번 반복한 것도 다 하나의 episode라고 생각해서 2번을 더 추가해서 5로 나눠준 것이다.
Monte-Carlo Control
DP에서는 Policy Iteration 은 policy evaluation과 policy imporvement로 나눠지는데, 여기서 Policy evaluation에 MC를 이용하면 Monte-Carlo Policy Iteration이 됩니다.
ㆍPolicy Iteration = ( policy evaluation + policy improvement )
ㆍMonte-Carlo policy Iteration = ( MC policy evaluation + policy improvement )
기존에 DP의 Policy iteration 문제점들은 다음과 같다.
- Value function의 model based 방식(mdp를 아는 경우만 가능한)
- Local Optimum
- Inefficiently of policy evaluatation (최적을 찾을 때까지 반복하는)
이러한 1,2,3 문제를 해결한 것이 Monte-Carlo Control입니다.



위에서 말한 것 같이 model-free의 경우에는 action value function을 통해서 policy를 update 할 수 있습니다.

그러나 만약 정책이 determinstic 하게 되면, 많은 에피소드를 진행해도 에피소드가 안 끝날 수 있습니다. 그래서 이것을 해결하기 위해 Exploring start라는 방식을 통해서 여러 상황을 갈 수 있게 합니다.

하지만 이런 식으로 실제 상황과 맞지 않는 Exploring start를 쓰지 않기 위해서 고안된 방법이 on-policy와 off-policy가 있습니다.
on-policy는 결정했던 행동들을 가지고 정책 평가와 발전을 하지만
off-policy는 다른 방법에 의해 만들어진 데이터로 정책 평가와 발전을 합니다.
Exploring start는 on-policy 방법 중 하나의 예제라고 할 수 있습니다.
on-policy
policy가 soft 하다는 성질을 가지고 있다 모든 $\pi(a|s) > 0$을 만족하지만 deterministic 한 optimal policy에 가깝게 이동한다는 의미를 가진다.


이러한 방법도 policy imporvement 조건을 만족하기 때문에 사용할 수 있습니다.

off-policy




on-policy 방법은 최적의 정책 대신 탐험을 계속하도록 하는 최적에 가까운 정책을 구하는 것으로 타협했다고 할 수 있고, off-policy는 2개의 정책을 사용해 하나는 최적의 정책을 학습하고, 다른 하나는 직접 행동하는 정책을 두는 것입니다.
target policy : 최적의 정책을 학습
behavior policy : 직접 행동하는 정책
target policy가 아닌 데이터에 의해서 배우는 학습 방법을 off-policy learning이라고 합니다.
on-policy에서는 target policy와 behavior policy가 같은 것이라고 생각하면 될 것 같습니다.
off-policy learning 같은 경우 다른 정책의 데이터로 학습하기 때문에 분산이 더 크고 수렴 속도가 느리지만, off-policy가 더 강력한 방법론이며 실생활에 할 용 할 수 있는 경우의 수가 많습니다. 예를 들어, 사람이 행동해서 만든 데이터 같은 학습하지 않는 controller로도 학습을 할 수 있습니다.
여기서 보통 제어 문제에서 적용한다면 behavior policy는 stochastic 하고 target policy는 deterministic 한 policy일 것이다. 그래서 behavior policy가 target policy를 닮아가게 하기 위해서 importacne sampling 방법을 사용합니다(즉 어떤 분포로부터 얻은 표본이 주어진 경우 그 표본을 이용해서 다른 분포에서 기댓값을 추정하는 방법)
일단 상태 $S_t$가 주어지면 어떤 정책 $\pi$ 하에서 $S_t$ 이후에 발생하는 상태 해적 궤적(trajectory)은 다음과 같습니다.

여기서 $p$ 는 상태 전이 확률 함수입니다. 따라서 target policy와 behavior policy 상태-행동 궤적(trajectory)의 상대적인 확률은 다음과 같습니다.
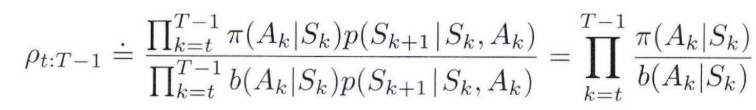
trajectory 확률은 상태 전이 확률에 달려서 보통은 모르지만, 분모와 분자에 같이 값이 있으므로 제거할 수 있습니다.
결국 importance sampling ratio는 MDP에는 영향을 받지 않고 2개의 policy의 궤적(trajectory)에만 영향을 받습니다.
behavior policy로 만들어진 return $G_t$ 만을 이용해서 target policy에서 expected return을 추정하는 것을 원하는 상황인 것을 다시 한번 상기합시다.
$E(G_t | S_t = s)=v_b(s)$를 갖기 때문에 이 기댓값의 평균을 낸다고 해도 $v_{\pi}$는 못 얻을 것입니다.
이제 여기서 importance sampling ratio를 이용해서 behavior policy에 있는 분포 값을 target policy 분포의 기댓값에 가깝게 하는 것입니다.
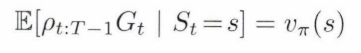

: 모든 시간 단계의 집합 (every visit mc) / 에피소드 내에서 상태 s를 최초로 마주치는 시간 단계의 집합(first visit mc)
단순히 평균을 내서 하는 기본 중요도 추출법과 가중치 중요도 추출법 2개로 나뉩니다.
기본 중요도 추출법 같은 경우 bias는 작으므로 $V_{\pi(s)}$ 수렴해간다고 볼 수 있지만, 에피소드가 길어질 경우 behavior policy가 V를 잘 반영 못할 수 있습니다. (High Variance 방식)
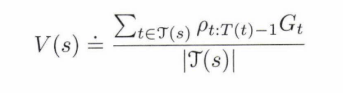

가중치 중요도 추출법 같은 경우 에피소드가 길어질 경우에도 V가 갑이 안 작아져서 behavior policy를 잘 반영할 수 있지만, 이러한 과정을 하다 보면 behavior policy에 의한 value function이 되어서 bias가 생기게 될 수 있다 (High Biased) 하지만 이 방식은 샘플링을 많이 하다 보면 점점 bias가 작아질 것을 기대할 수 있습니다.
이거는 기초적인 것 같고 그 뒤에 더 discounted 도 고려하고 다양한 importance sampling이 나옵니다.
필자는 여기서... 포기.. 아래 글을 참고하길 바란다. (아니면 단단한 강화 학습 책에도 나옵니다)
https://mclearninglab.tistory.com/151?category=853770
강화학습 Sutton [Ch5 Dynamic Programming] #8 *Discounting-aware Importance Sampling
지금까지 봐왔던 Off-policy는 importance-sampling weight를 discount return에 곱하는 식으로 했었다. 그런데 이것은 discounted rewards의 합이라는 내부 구조를 고려하지 않고 그저 return 하나로만 생각했다...
mclearninglab.tistory.com
Summary
-
sample episode라는 경험을 통해 최적의 가치와 정책을 학습하는 Monte Carlo를 다룸
-
DP보다 좋은 장점 3가지
- 환경의 dynamics의 모델 없이 환경과 상호작용(interaction)으로 최적의 행동을 학습한다.
- 모델을 구성하기 힘든 시뮬레이션이나 샘플 모델에도 사용할 수 있다.
- 흥미로운 상태 일부분들에만 집중해서도 사용할 수 있다.(8장에서 더 자세히 다룸)
-
또 다른 장점은 4장에서 소개된 generalized policy iteration(GPI) 방법을 따라서 사용할 수 있다. (Policy evaluation, Policy improvement) 다만 policy evaluation에서 모델 없이 한다는 점과 episode-by-episode 기반으로 한다는 점이 다르다.
-
충분히 exploration을 해야 return을 얻을 수 있기에 exploration을 위한 방법으로 모든 상태에서 랜덤 하게 시작하는 방법이 있었다.(exploring starts)
-
자신의 정책을 통해 얻은 데이터로 최적의 정책을 찾는 on-policy, 자신 외에 또 다른 정책(behavior policy)을 통해 얻은 데이터로 최적의 정책(target policy)을 찾는 off-policy
-
off-policy는 다른 정책을 사용하기에 importance sampling이 필요
- Ordinary importance sampling (unbiased, but large or infinite variance)
- Weighted importance sampling (biased, but finite variance, preferred)
- 간단하지만 아직 확실히 해결된 부분이 아니기에 연구가 진행중
-
다시 정리하자만 MC는 DP와 달리
- sample experience를 사용해 모델이 필요없다.
- bootstrap을 사용하지 않는다. 즉, estimate한 value로 estimate하지 않는다.
다음 챕터에서는 Monte Carlo처럼 experience로 학습하면서도 DP처럼 bootstrap를 하는 Temporal difference에 대해 다룬다.
넘나 어려움 ㄷㄷ

모두의연구소
www.modulabs.co.kr
https://mclearninglab.tistory.com/149?category=853770
강화학습 Sutton [Ch5 Dynamic Programming] #7 Off-policy Monte Carlo Control
Off-policy Monte Carlo Control control 문제에서 off-policy 방법에 대해 다룬다. on-policy는 control을 위해 사용했던 policy의 가치(value)를 추정(estimate)하지만, off-policy는 policy가 행동하는 behavio..
mclearninglab.tistory.com
'관심있는 주제 > RL' 카테고리의 다른 글
| On-Policy와 Off-Policy Learning의 차이 (0) | 2020.07.11 |
|---|---|
| 강화학습 Action-Selection Strategies for Exploration (0) | 2020.06.27 |
| chapter 4 Dynamic Programming Example 도박사 문제 (0) | 2020.05.05 |
| chapter 4 Dynamic Programming Example Car Rental (in-place) (0) | 2020.05.05 |
| chapter 4 Dynamic Programming Example Grid World (0) | 2020.05.05 |