개인적으로 분석을 하면서, 항상 궁금한 점이 있었다.
과연 전처리에 따른 성능 차이는 얼마나 날까?
개인적으로는 많이 날 것이라고 생각하면서도 기본적으로 Neural Network은 결국 내부에서 알아서 Representation이 된다고 생각하기 때문에 크게 나지 않는다는 2가지 생각이 공존했다.
그래서 개인적으로는 차이가 나는 것을 기대하면서, 더 나은 방법을 찾기 위해서 아주 간단한 실험을 진행했다.
물론 이 실험은 한 데이터셋에서만 실험을 하고, 많은 실험을 하지는 않았을 뿐만 아니라, 각 데이터 변수마다 동일한 처리 기법을 사용해서 정확하지 않을 수 있다.
일단 결론부터 말하자면, 전처리 기법들에 따른 모델 성능은 큰 차이가 나지 없었다.
필자는 동일한 후보들(10가지)를 한 5번 돌려본 것 같다.
그러나 모델간의 성능 차이는 나지 않았다.
모든 네트워크는 아래와 같은 그림으로 통일했다.
케라스로 실험해서, 모델 그림을 뽑을 수 있지만, 병렬로 돌리는 코드를 짜 놓은 상태라서, 중간에 표현하기가 어려웠다는 핑계로 아래와 같이 그림을 그려봤다.ㅎ

실험 후보군은 다음과 같다.

주로 sklearn을 활용했으면, minmax를 주로 했다.
이유는 표준화는 분명 좋은 방법이다. 하지만 기본적으로 표준화하는 작업으로 인해 만약 test data가 현재 학습하는 데이터와 다를 경우에 과적합을 더 시킬 것이라는 막연한 생각 때문이다.
아래 그림을 보면 원자료를 정규화한 것과 표준화한 것이 있다.
개인적으로 어차피 Neural Network가 내부에서 데이터에 대한 Representation을 표현해주니, 기존 분포를 크게 망치지 않는 선에서 전처리가 중요하다고 생각한다.(개인적인 생각)
그래서 정규화를 보면 기존 분포의 스케일을 동일하게 맞추는 작업만 해주고,
표준화는 데이터의 분포를 0주변으로 모은 다음 정규 분포화 해준다.
필자의 아주 개인적인 생각으로는, 저런 식의 분포 변화는 오히려 새로운 데이터가 들어올 때, 기존 분포와 다를 경우(물론 이 경우는 어떠한 전처리에도 문제를 발생시킬 것 같음) 일 때, 과적합을 더 크게 유도할 것이라 생각하고 실험을 진행했다. 그래서 대부분의 실험에서 정규화를 어떻게 해주냐에 따른 성능 차이가 나는지 궁금하여 많은 부분이 포함되고 있다.
https://medium.com/@rrfd/standardize-or-normalize-examples-in-python-e3f174b65dfc



데이터 전처리는 다음과 같이 진행하였다.

- 일단 Outlier를 제거했다.
- 수치형 변수 결측치를 평균으로 대체했다.
- 범주형 변수 결측치를 최빈값으로 대체했다.
- 연속형 변수 전처리 방법이 이번 글의 핵심이다 (10개로 실험)
- 범주형 변수를 Catboost 방법론을 적용해서 처리하였다.
실험 결과는 다음과 같다.



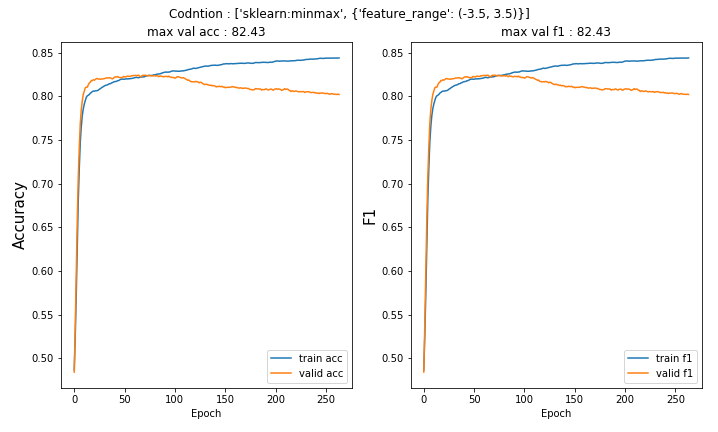


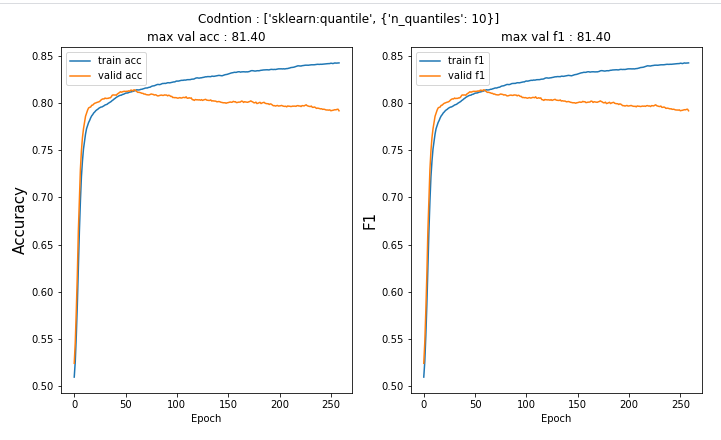

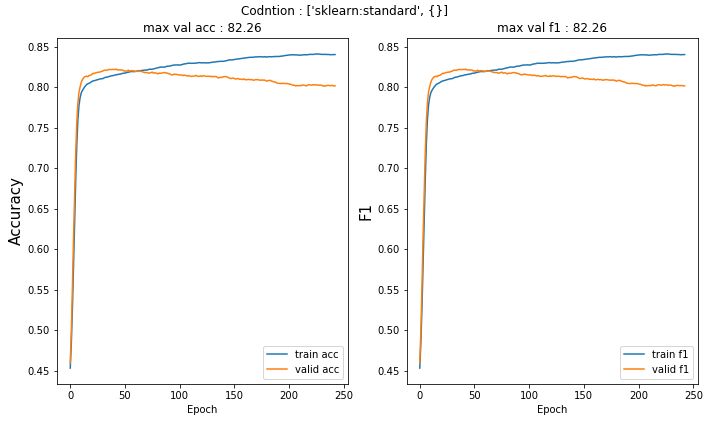

총 10가지의 실험 결과는 다음과 같다. 과적합될 시에 정지하기 위해서 earlystopping을 적용하였다.
실험 결과는 앞에서 말한 것처럼 거의 차이가 없다.
하지만, 이중에서 2개 정도 선택하라고 하면, 실험 결과에서는 Robust 표준호와 minmax(-5,5)가 가장 높은 성능을 내었다.
사실 이번 실험에서 기대한 바는 적어도 Neural Network에서 Standardization보다는 Normalization이 더 낫다는 것을 확인해보고 싶었다. 하지만 간단한 실험에서는 실제로 큰 차이가 없는 것 같다.
큰 차이가 없으니, 아무거나 막 써도 되는 건지~ 실험을 해서 여러 가지를 해보는 것이 좋을지~ 모르겠다~

'분석 Python > Data Preprocessing' 카테고리의 다른 글
| [변수 선택] Chi-Square 독립성 검정으로 범주형 변수 선택하기 (0) | 2020.03.28 |
|---|---|
| [변수 선택] Python에서 변수 전처리 및 변형 해주는 Xverse 패키지 소개 (1) | 2020.03.22 |
| [변수 선택] sklearn에 있는 mutual_info_classif , mutual_info_regression를 활용하여 변수 선택하기 (feature selection) (0) | 2020.03.09 |
| [변수 선택 및 생성]중요 변수 선택 및 파생 변수 만들기-2 (0) | 2020.01.09 |
| [변수 선택 및 생성]중요 변수 선택 및 파생 변수 만들기 (2) | 2020.01.08 |