2019. 12. 21. 16:55ㆍ분석 Python/Pandas Tip

도움이 되셨다면, 광고 한번만 눌러주세요. 블로그 관리에 큰 힘이 됩니다.
파이썬에서 분석을 하실 때 아무래도 가장 편하게 생각할 수 있는 것은 판다스를 활용하는 방법일 것이다.
그리고 저와 같은 개발쪽 초보자들은 가장 편한 to_csv , read_csv로 데이터를 저장하고 읽을 것이다.
csv로 저장하면 다른 곳에서도 쓸 수 있어 편하지만, 데이터 자체를 저장하는 것에는 별로 좋지 않아 보인다.
왜냐하면 판다스로 읽고 쓰는 것이 빅데이터에서는 많은 시간을 소요하기 때문이다.
그래서 본 글에서는 csv , pickle, feather 총 3가지를 비교해보고자 한다. 여러 가지 방식(hdf , parquet)이 있지만,
이번 글에서는 다른 방식도 있다는 것을 말하고 싶기 때문에 궁금하시면 찾아서 하시면 될 것 같다!


아래 Youtube도 잘 보시면 판다스로 큰 데이터로 분석할 때 도움이 될 것 같다.
판다스의 여러가지 이슈에 대한 소개도 해줘서 참고하면 좋겠다
https://www.youtube.com/watch?v=0Vm9Yi_ig58&t=1155s
일단 임의의 데이터를 만들어보자.
본 글에서는 결측도 있는 것을 저장할 때 잘 남겨지는지도 체크하고
object 이 아닌 category 타입으로 저장이 효과도 얼마나 있는지 확인하고자 한다.
데이터 만들기
import pandas as pd
import numpy as np
from copy import deepcopy
object1 = pd.Series(np.random.choice(list("ABCDE") ,
1000000 , p = [0.4,0.35,0.1,0.1,0.05] ))
object2 = pd.Series(np.random.choice(["aa","bb","cc","dd","ee"] ,
1000000 , p = [0.4,0.35,0.1,0.1,0.05] ))
object3 = pd.Series(np.random.choice(["F","G","H","I","J"] ,
1000000 , p = [0.4,0.35,0.1,0.1,0.05] ))
## 추가
numobject4 = pd.Series(np.random.choice(["1","2","3","anan","4"] ,
1000000 , p = [0.4,0.35,0.1,0.1,0.05] ))
numobject5 = pd.Series(np.random.choice(["10","12","13","##","###"] ,
1000000 , p = [0.4,0.35,0.1,0.1,0.05] ))
obj = pd.concat([object1 , object2 , object3 , numobject4 , numobject5], axis = 1)
num = pd.DataFrame(np.random.normal(loc=0, scale=1 ,size=(1000000, 5)))
data = pd.concat([obj , num], axis = 1)
column = ["obj1" , "obj2" , "obj3" ] + [ "objnum1" , "objnum2" , "num1" , "num2" , "num3", "num4", "num5"]
data.columns = column
data.dtypes

결측 만들기
No , ori = data.shape
p_miss = 0.2
p_miss_vec = p_miss * np.ones((No,1))
Missing = np.zeros((No,ori))
ori_Missing = np.zeros((No,ori))
for idx , st in enumerate(np.arange(ori)) :
A = np.random.uniform(0., 1., size = [No,])
A1 = np.expand_dims(A , axis = 1)
B_ = A > p_miss_vec[idx]
ori_Missing[:,idx] = 1.*B_
B = A1 > p_miss_vec
MaskVector = 1-ori_Missing
col =data.columns.tolist()
np_data = data.values
np_data[MaskVector == 1] = np.nan
missing_data = pd.DataFrame(np_data , columns = column)
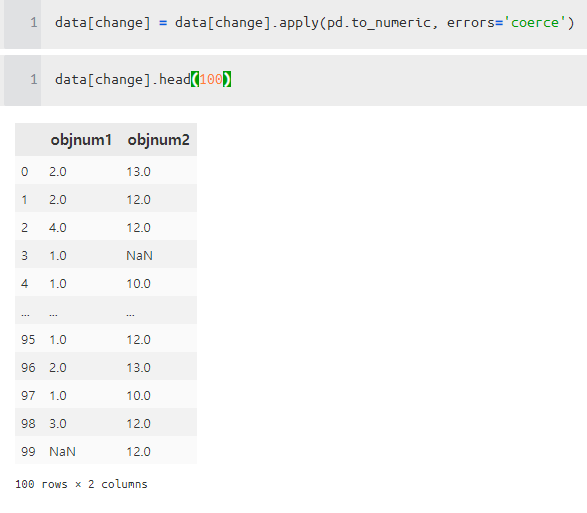
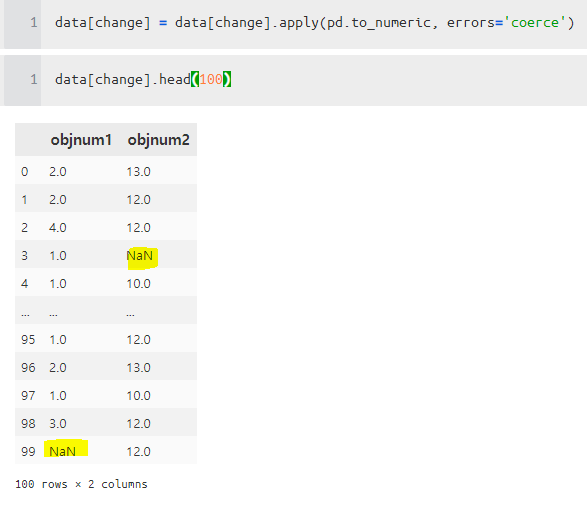
missing_data[numcol] = missing_data[numcol].astype(float)결측 데이터가 있는 데이터를 얻게 되었다.
그러면 이제 현재 object type 데이터를 category type으로 바꾸고 용량 차이가 얼마나 나는지 비교해보자.
cat_missing_data = deepcopy(missing_data)
cat_missing_data[objcol] = cat_missing_data[objcol].astype("category")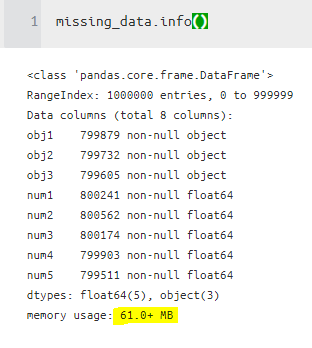


무려 20MB가 차이가 난다. 데이터가 크면 클수록 그 차이를 훨씬 많이 느낄 것 같다.
이제 그러면 저장해보자. 일단 category type으로 변경한 데이터를 저장하자.

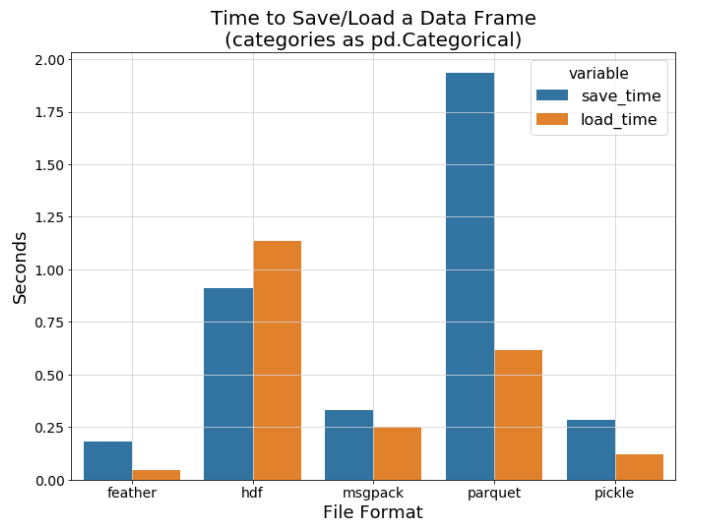
소요 시간을 확인해보니, csv가 가장 느리고 feather 가 가장 빨랐다

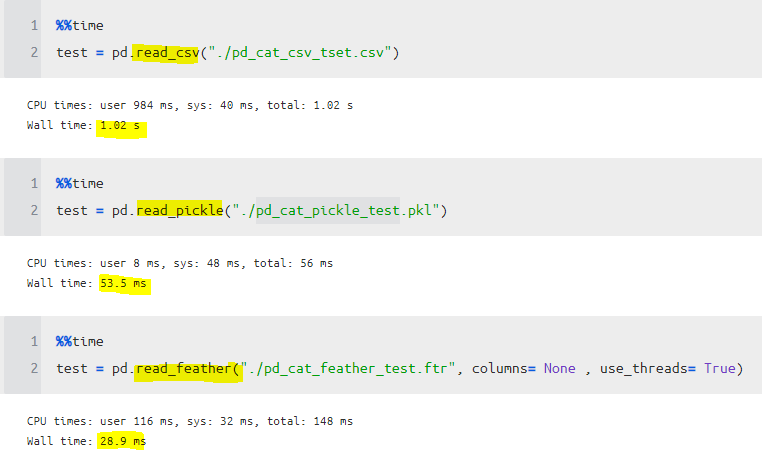
읽는 것도 read_feather 같은 경우 여러 스레드를 사용할 수 있는 옵션도 있어서 그런지 더 빠르게 읽을 수 있었다.

One Hot Check
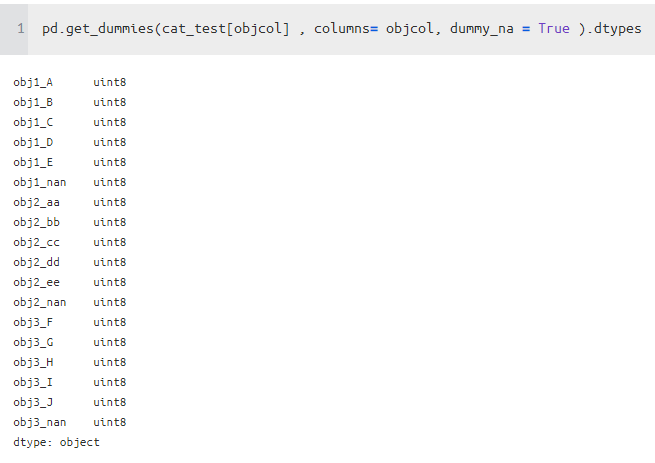
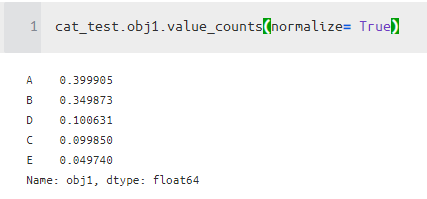

- 결론
저장할 때 object type을 category type로 바꿔서 사용하기
사용할 때도 웬만하면 category로 사용하는 것이 좋을 듯
저장하고 읽는 방식은 csv, pickle , feather 방식 중에서는 feather 가 가장 우수함 (hdf , parquet 도 우수하게 나올 것이라고 생각)
단일로 사용한다면 저런 것이고 사실 modin을 쓰는게 가장 좋긴 하다....
https://data-newbie.tistory.com/279?category=750452
[ Python ] modin 으로 pandas 더 빠르게 사용하기
https://modin.readthedocs.io/en/latest/installation.html 1. Installation — Modin 0.6.0 documentation 1. Installation There are a couple of ways to install Modin. Most users will want to instal..
data-newbie.tistory.com
'분석 Python > Pandas Tip' 카테고리의 다른 글
| [ Python ] 정형데이터 용량 줄이는 함수 소개 (연속형, 이산형, 문자형) (0) | 2020.04.12 |
|---|---|
| pandas describe에 결측데이터 개수 포함해서 표현해보기 (0) | 2020.04.08 |
| [ Python ] Pandas idxmin , idxmax, pd.cut 함수 알아보기 (0) | 2019.10.29 |
| [ Python ] modin 으로 pandas 더 빠르게 사용하기 (0) | 2019.09.28 |
| [ Python ] Pandas Lambda, apply를 활용하여 복잡한 로직 적용하기 (2) | 2019.07.13 |