https://modin.readthedocs.io/en/latest/installation.html
1. Installation — Modin 0.6.0 documentation
1. Installation There are a couple of ways to install Modin. Most users will want to install with pip, but some users may want to build from the master branch on the GitHub repo. 1.1. Installing with pip 1.1.1. Stable version Modin can be installed with pi
modin.readthedocs.io
후배가 한번 언급을 해서 궁금해서 modin package 테스트를 진행해봤다.
일단 modin 패키지를 보니 dask 패키지를 이용하는 방식과 ray를 이용하는 방식이 있는데,
예전에 dask 방식으로 쓸 때는 먼가 처리는 빨라보였으나 일반적으로 Pandas로 바꾸는데 너무나도 많은 시간이 걸렸는데, 이 modin을 dask로 하는 방식은 동일한 것 같다.
https://www.youtube.com/watch?v=0Vm9Yi_ig58&t=498s
일반적으로 pandas는 대용량 처리에는 크게 맞지 않다고 한다.
하지만 대부분의 사람들이 쓰다보니, 다른 좋은 개발자분들이 편의성을 위해 변종들이 많이 나오는 것 같다.
위의 유튜브는 Pycon에서 발표한 자료이다. Pandas를 사용함에 있어서 팁이 많은 것 같다 참고 참고
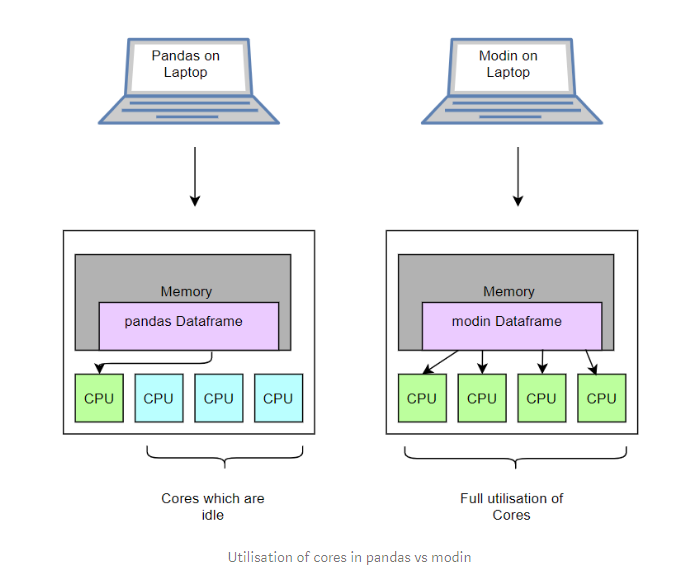
일반 판 다스 같은 경우에는 cpu를 1개만 쓰지만, modin 같은 경우에는 여러 개로 뿌려줘서 처리한다.

modin의 아키텍처는 다음과 같다고 한다. modin 같은 경우에는 row , column 둘 다 partition을 나눈다.
이렇게 하면 더 flexibility와 scalability를 늘려서 좋다고 하는 것 같다.
(사실 내가 만들 것은 아니기 때문에 크게 관심은 없지만 암튼 아주 대략적으로 저런 방식으로... 한다는 것만 알아두기)
3.5GB 데이터가 있을 때 얼마나 걸리는지 테스트를 진행
import numpy as np
import ray
ray.init(num_cpus=20)
import modin.pandas as pd
import pandas
import io
buf = io.StringIO()
data.info(buf=buf)
#info = buf.getvalue()
info = buf.getvalue().split('\n')[-2]
print(info)
## memory usage: 3.5+ GB



음 다음에는 groupby 나 머 여러 가지 전처리를 해보니, 먼가 Partition 개념이 들어가서인지, 한 개를 선택해서 처리할 때는 오히려 pandas 가 더 빨랐고, 여러 개를 한꺼번에 처리하는 것에 있어서는 modin이 더 빨랐다!
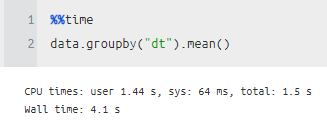


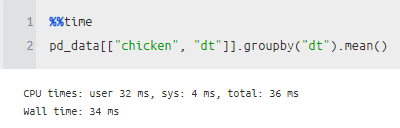
그리고 서로 type은 조금 다를지라도 연산이 되는 것을 확인했다.

암튼 비교는 이 정도로 하겠다.
하지만 우연히 발견한 단점은 갑자기 broken pipe라면서 modin으로 불러온 데이터가 안 읽히는 경우가 있었다.
결론 : 적당히 큰 데이터(~100GB 이하)에서는 Pandas보다는 Modin을 쓰자! 그리고 csv보다는 pickle?

'분석 Python > Pandas Tip' 카테고리의 다른 글
| [ Python ] pandas 읽고 쓰기 비교 (to_csv , to_pickle , to_feather) (1) | 2019.12.21 |
|---|---|
| [ Python ] Pandas idxmin , idxmax, pd.cut 함수 알아보기 (0) | 2019.10.29 |
| [ Python ] Pandas Lambda, apply를 활용하여 복잡한 로직 적용하기 (2) | 2019.07.13 |
| [TIP / Pandas] Pandas를 보다 올바르게 사용하는 방법 (2) | 2019.05.23 |
| Multiprocessing pandas package 2개 소개 (0) | 2019.05.08 |