[ Python ] Pandas idxmin , idxmax, pd.cut 함수 알아보기
2019. 10. 29. 19:20ㆍ분석 Python/Pandas Tip
728x90
- 데이터셋 만들기
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
Iris = load_iris()
concat = np.concatenate( (Iris.data , np.array(Iris.target).reshape(-1,1)) , axis = 1)
data = pd.DataFrame(concat , columns = Iris.feature_names + ["Species"])
가끔 먼가 데이터에서 가장 작은 값? 큰 값을 찾고 싶을 때가 있다.
그럴 때 보통 코드는 다음과 같다.
idxmin() , idxmax()
## min
data[data['sepal length (cm)'] == data['sepal length (cm)'].min()]
## max
data[data['sepal length (cm)'] == data['sepal length (cm)'].max()]어디서 문득 찾아보니 다음과 같은 것이 있어서 공유 훨씬 간결하다!
## min
data.loc[data['sepal length (cm)'].idxmin(),:]
## max
data.loc[data['sepal length (cm)'].idxmax(),:]
pd.cut
카테고리로 범주화해주고 싶을 때 사용한다.
양쪽 사이드를 포함할지 여부는 다음과 argument가 한다
include_lowest / right
- 오른쪽만 포함시키고 싶은 경우
pd.cut(pd.Series(range(101)),
[0, 24, 49, 74, 100] ,
include_lowest= False ,
right=True
)
- 왼쪽만 포함시키고 싶은 경우
pd.cut(pd.Series(range(101)),
[0, 24, 49, 74, 100] ,
right= False ,
include_lowest= True)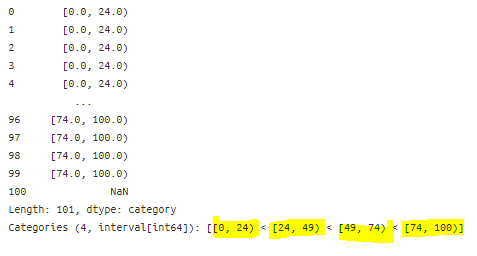
- 그냥 5개 구간으로 나누고 싶은 경우
pd.cut(data['sepal length (cm)'], 5 ,)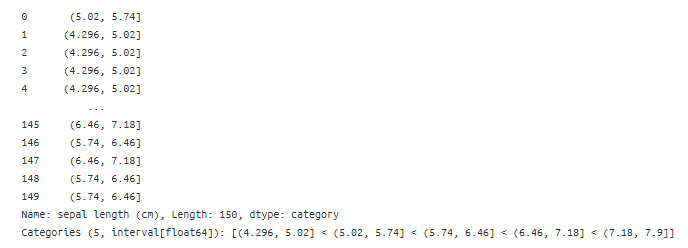
- 특별히 라벨을 부여하고 싶은 경우
pd.cut(data['sepal length (cm)'],
bins = 5,
include_lowest= True ,
labels = ["Group {}".format(i) for i in np.arange(1,6)])
- 라벨을 그냥 안 주고 나누고 싶은 경우
pd.cut(data['sepal length (cm)'], 5 , labels=False)
728x90
'분석 Python > Pandas Tip' 카테고리의 다른 글
| pandas describe에 결측데이터 개수 포함해서 표현해보기 (0) | 2020.04.08 |
|---|---|
| [ Python ] pandas 읽고 쓰기 비교 (to_csv , to_pickle , to_feather) (1) | 2019.12.21 |
| [ Python ] modin 으로 pandas 더 빠르게 사용하기 (0) | 2019.09.28 |
| [ Python ] Pandas Lambda, apply를 활용하여 복잡한 로직 적용하기 (2) | 2019.07.13 |
| [TIP / Pandas] Pandas를 보다 올바르게 사용하는 방법 (2) | 2019.05.23 |