728x90
MissForest로 결측치 대체를 하려고하는 것이 목적이다.
그래서 일단 임의의 데이터를 만들고 진행한다.
from missingpy import MissForest
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
tr1 = list("ABCD")
tr2 = ['pooh', 'rabbit', 'piglet', 'Christopher']
va1 = list("ABCDE")
va2 = ['pooh', 'rabbit', 'piglet', 'Christopher', "bird", "coco"]
tr1_ = np.random.choice(tr1, 1000 , p=[0.5, 0.1, 0.1, 0.3])
va1_ = np.random.choice(va1, 500 , p=[0.4, 0.1, 0.1, 0.3,0.1])
tr2_ = np.random.choice(tr2, 1000 , p=[0.5, 0.1, 0.1, 0.3])
va2_ = np.random.choice(va2, 500 , p=[0.5, 0.1, 0.09, 0.25,0.05,0.01])
tr_n = np.random.normal(size = (1000 , 10))
va_n = np.random.normal(size = (500 , 10))
col = [ "Cols{}".format(i) for i in np.arange(10)]
Tr = pd.DataFrame(tr_n, columns= col)
Va = pd.DataFrame(va_n , columns= col)
Tr["Col_Fac1"] = tr1_
Tr["Col_Fac2"] = tr2_
Va["Col_Fac1"] = va1_
Va["Col_Fac2"] = va2_
Tr.head()
이제 이러한 데이터에서 결측을 만들어보자.
가정은 MCAR로 임의로 만들었다. 위에서 만들수도 있지만, 그냥 여기서 MaskVector를 만들어서 진행했다.
No , ori = Tr.shape
p_miss = 0.2
p_miss_vec = p_miss * np.ones((No,1))
Missing = np.zeros((No,ori))
ori_Missing = np.zeros((No,ori))
for idx , st in enumerate(np.arange(ori)) :
A = np.random.uniform(0., 1., size = [No,])
A1 = np.expand_dims(A , axis = 1)
B_ = A > p_miss_vec[idx]
ori_Missing[:,idx] = 1.*B_
B = A1 > p_miss_vec
No , ori = Va.shape
p_miss = 0.2
p_miss_vec = p_miss * np.ones((No,1))
Missing = np.zeros((No,ori))
va_Missing = np.zeros((No,ori))
for idx , st in enumerate(np.arange(ori)) :
A = np.random.uniform(0., 1., size = [No,])
A1 = np.expand_dims(A , axis = 1)
B_ = A > p_miss_vec[idx]
va_Missing[:,idx] = 1.*B_
B = A1 > p_miss_vecMaskVector = 1-ori_Missing
VaMaskVector = 1-va_Missing
Tr[MaskVector == 1 ]= np.nan
Va[VaMaskVector==1] = np.nan
그 다음에 간단한 전처리 진행을 했다.
fac_var = ["Col_Fac1" , "Col_Fac2"]
change_nan = {}
for col in fac_var :
unis = list(set(Va[col].unique()).difference(set(Tr[col].unique())))
temp = {}
for uni in unis :
temp[uni] = np.nan
change_nan[col] = temp
Va2 = Va.replace(change_nan)그 다음에 label encoder를 적용하기 위해 결측치를 다른 값으로 대체하고 해당 encoder값을 저장했다.
le_info = {}
for col in fac_var :
Tr[col] = Tr[col].fillna("NaN")
Va2[col] = Va2[col].fillna("NaN")
le = LabelEncoder()
x = Tr[col].unique()
le_info[col] = le.fit(x)
le.fit(x)
Tr[col] = le.transform(Tr[col])
Va2[col] = le.transform(Va2[col])
le_info[col].classes_

결측을 NaN으로 만들었기 때문에 다시 MaskVector를 사용해서 결측으로 만들었다. 아니면 해당 encoding 값을 바꾸는 것도 다른 하나의 방법일 것이다.
Tr[MaskVector == 1 ]= np.nan
Va2[VaMaskVector==1] = np.nan
Va2.head()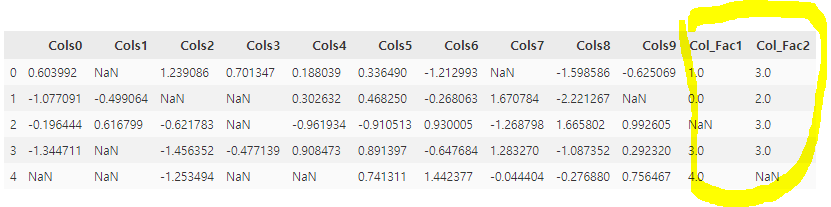
이제 데이터는 다 구성했으니, MissForest 결측치 대체 알고리즘을 돌려보자!
큰 특징은 cat_var로 범주형 변수의 index 정보를 줘야 한다!
UseCols = Tr.columns.tolist()
cat_var = [idx for idx , col in enumerate(UseCols) if col in fac_var]
MISSForest_algo = MissForest(verbose = 0, n_jobs = -1 , max_depth=5)
MISSForest_algo.fit(X =Tr , cat_vars= cat_var)
Tr_imputed = MISSForest_algo.transform(Tr)
Tr_imputed = pd.DataFrame(Tr_imputed, columns= UseCols
Tr_imputed[fac_var] = Tr_imputed[fac_var].astype(int)
Va_imputed = MISSForest_algo.transform(Va2)
Va_imputed = pd.DataFrame(Va_imputed, columns= UseCols)
Va_imputed[fac_var] = Va_imputed[fac_var].astype(int)
## 다시 변형
for col in fac_var :
Tr_imputed[col] = le_info[col].inverse_transform(Tr_imputed[col])
Va_imputed[col] = le_info[col].inverse_transform(Va_imputed[col])Tr_imputed.isna().sum()
도움이 되셨다면, 광고 한번만 눌러주세요. 블로그 운영에 큰 힘이 됩니다 ^^
'분석 Python > Data Preprocessing' 카테고리의 다른 글
| [변수 선택 및 생성]중요 변수 선택 및 파생 변수 만들기 (2) | 2020.01.08 |
|---|---|
| [ Python ] Scikit-Learn, 변수 전처리 Pipeline Transformer 만들어보기 (0) | 2019.12.28 |
| [변수 처리] 데이터에서 결측치 잘 만들어보기 (0) | 2019.09.17 |
| [변수 처리] Python에서 범주형 변수(Categorical) 다루기 (0) | 2019.09.13 |
| [ 변수 처리] 파이썬 결측치 대체 알고리즘 비교 예시 (4) | 2019.09.10 |