2018/10/07 먼가 이미지에서 내가 찾고 있는 것이 나온 것 같아서 한번 파보려고 한다.
페이지는 72... 필요한 것만 볼 예정이니, 한번 보는 것을 추천!
Abstract
synthetic data 생성의 목적은 real 한 데이터를 제공해주지 못하거나, 제한되게 제공할 경우에 사용한다.
민감한 데이터 일 경우 그것을 함부로 원본을 주기가 어려울 것이다.
전통적인 방법들은 중요한 통계적인 성질을 잘 복제하지 못한다. 성질들이라고 하면은
distribution, the patterns or the correlation between variables, are often omitted
게다가 기존 방법들은 최근에 핫한 딥러닝이나 머신러닝 방법을 사용하지 않고 있다.
그래서 기존은 GAN은 이미지와 TEXT에서 하지만, tabular data에도 잘 적용될 것이다.
Introduction
소프트웨어 개발, 데이터 분석 또는 기계 학습 등의 분야에서 신기술의 평가나 실증 실험에 실제 데이터를 이용하는 것이 일반적인 관행이다. 그러나 이러한 목적으로 실제 데이터를 사요 할 때 중요한 제한들이 있다.
이 제한은 데이터 확보의 어려움부터, 큰 데이터를 확보하기 어렵거나 데이터가 민감해서 Privacy Concern도 많이 화두가 되고 있다.
synthetic data 생성 메커니즘은 많은 상황에서 유용하다.
Researchers, Engineers , Software Developers는 원본 데이터 접근하지 않고, Privacy 나 Security 걱정 없이 사용할 수 있게 된다.
GAN이라는 알고리즘이 Synthetic 알고리즘에서 큰 출발점이 되었다.
앞으로 다음과 같은 것을 소개하려고 한다.
- The next chapter formally introduces the concept of Generative Adversarial Networks along with related work towards synthetic data generation that is relevant to this project.
- Then, chapter 3 explains how to generate synthetic data using GANs, along with the designed experiments to evaluate the solution.
- The analysis over the results, with a comparison between the built solution and a simpler baseline data generation approach, is provided in chapter 4.
- Finally, chapter 5 summarizes the conclusions, answers the research questions, and suggests a future line of work.
Background
The McGraw Hill Dictionary of Scientific and Technical Terms defines
synthetic data
"any production data applicable to a given situation that are not obtained by direct measurement"
직접 측정에 의해 획득되지 않은 주어진 상황에 적용되는 생산 데이터
synthetic data 생성은 최근 몇 년간 새로운 소프트웨어 기술의 시험과 검증에서 그것의 사용뿐만 아니라 기밀 데이터의 프라이버시 유지에 상당한 초점을 맞췄다.
많은 것들은 한계가 있지만, ML , Artifical Intelligence는 뛰어난 성능을 보이고 있다.
The traditional tasks that machine learning models perform are classification, regression, prediction, and clustering.
Deep Learning techniques are based on the concept of Artificial Neural Networks, which are networks of connected layers of nodes (neurons) inspired by the biological neural networks of animal brains.
Deep: they are composed of more than 2 layers: an input layer, an output layer, and at least one hidden layer that enable the network to learn complex nonlinear functions required to carry out the complicated tasks of Artificial Intelligence.
RNN
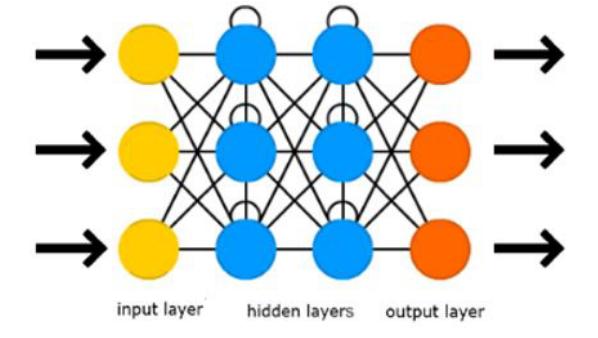
time에 대한 정보를 제공하기 위해 추가적 연결을 하는 방법이 RNN ( text 생성 , time series 예측)
Deep Generative Models
- Probability
- statistics theory
- 확률적 모델링으 two types
- generative model
- 실행하기에는 복잡하게 때문에 아직까진...
- discriminative model
- 2014 (Classify)
- generative model
DL과 ML 사이에서 이루어지는 한 가지 구별은 그들이 감독된 학습을 수행하느냐, 감독되지 않은 학습을 수행하느냐이다.
대부분의 Discriminative model 은 학습을 위해 라벨링 된 데이터가 필요하다는 것을 의미하는 감독된 학습의 범주에 속하지만, 대부분의 Deep Generative Model은 감독되지 않은 것으로 분류되며, 이는 라벨링 된 데이터가 필요하지 않다는 것을 의미한다 [31].
이것은 자동화와 인공지능의 길목에서 Deep Generative Model을 매우 매력적으로 만드는 것이다.
2.4 Generative Adversarial Networks
2014 이안 굿펠로우가 만들었다!
G와 D가 있다. ( 이것을 보는 사람은 다들 알 테니 패스)

On one side, it does not offer the possibility to control what data to generate, nor the possibility to generate categorical data
Categorical 데이터를 생성하는 것이 가능하지 않다고 한다! 그리고 학습하기도 어렵다!
한 가지 가능한 방법은 Conditional GAN처럼 onehot으로 살짝 정보를 주는 방식이 될 수도 있다.
나중에는 WGAN이 있는데 이것은 학습의 안정성과 해석력을 제공한다.
그리고 추후에 어떤 연구자는 WGAN 접근 방식에서 Softmax를 하는 방법을 통해서 Categorical 변수를 생성할 수 있다고 한다.
(실제로 해봤는데, 약간 이상하게 class 전체를 안 하는 경향이 생겼다.)

아니면 유의미한 향상을 한 것이 데이터의 Latent space representation을 접근하는 Bidirectional GAN도 있다.
생성 모델의 잠재된 공간이 풍부한 의미 정보를 포착한다는 생각에 자극받은 연구.
따라서 이러한 의미적 잠재 표현에 접근하면 생성할 데이터를 제어하는 데 유용할 뿐만 아니라 의미학이 관련되는 직무의 형상 표현에도 유용할 수 있다.
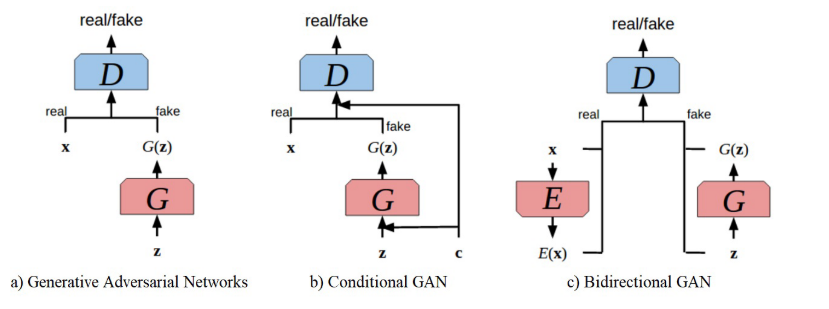
Privacy concern 관련 논문으로는 medGAN(categorcial 전문 gan)
text는 seqgan , maskgan
요약하자면, 이 절에서 제시된 연구의 맥락은 연속적이고 범주적이며 텍스트 데이터도 고려하는 GAN과 같은 심층 생성 기계 학습 모델을 기반으로 하는 통합 데이터 생성 도구를 개발하려는 아이디어는 확실히 더 많은 연구가 이루어져야 한다는 것을 시사한다.
아직 2018 10월이지만, table data 생성은 아직도 연구가 많이 필요하다고 한다!
일단 여기까지 하겠다.
일단은 하나 건졌다고 생각하는 것은 wgan에서 마지막 레이어에서 softmax를 통해서 생성을 하니 유용했다는 점!
이후에는 Chapter3 Generation of Synthetic Data with GANs(14pg)부터 시작하려고 한다.
일단 지금 코딩하기가 뭔가 싫으니, 논문이라도 많이 읽고 생각을 폭을 넓히자!
https://data-newbie.tistory.com/194?category=686943
data-newbie.tistory.com
https://data-newbie.tistory.com/195?category=686943
data-newbie.tistory.com
https://data-newbie.tistory.com/197?category=686943
data-newbie.tistory.com
https://data-newbie.tistory.com/199
Generation of Synthetic Data with Generative Adversarial Networks - 리뷰 4 [Chapter 5]
Chapter 5 Conclusions and future work 드디어 끝이다~~~ 이 프로젝트의 목표는 미래 제품이 최소의 사용자 상호작용을 필요로 하는 방식으로 통합 데이터 생성기의 개발을 돕는 동시에 실제 데이터 세트의 유사..
data-newbie.tistory.com
https://www.youtube.com/watch?v=CfsYOmCw0Go