일단 빠르게 분석을 해야 되면, 일반 전처리는 다해보고 모델링해서 돌려본다.
근데 먼가 결과가 신통방통하지 못하다.
이땐 머 hyperparamter를 최적화해도 결과는 영 그럴 것이다.
그러면 여기서부터 고민을 하게 된다.
일단 그림을 변수별로도 열심히 그려봐서 딱 구분되는 것이 있는지 살펴보거나, Correlation을 구해본다.
사실 여기서 머 추가적으로 분포를 본다고 해도 이미 모델링해서 잘 나오지 않았다면, 웬만하면 찾기 어려울 것이다.
그렇다면 여기서 더 성능을 높이기 위해 유의미한 새로운 파생변수를 어떻게 만들어야 할까??
일단 데이터가 자기 도메인이 아니게 되면 막막하다.
일단 자기가 주로 하던 분야가 아니니 생각의 깊이도 당연히 얕을 수밖에 없다.
현업에게 요청할 수도 있지만, 계속 붙잡고 있을 수도 없는 노릇이니..
그래서 다음과 같이 앤드류 교수님이 말했다고 한다.

앤드류 교수님은 다음과 같이 feature engineering은 어렵고 시간도 굉장히 많이 걸리고 전문가적인 지식까지 필요해서 참으로 어려운 작업이라고 한다.
그래서 이 포스터에서는 CNN을 사용해서 Structured data에 적용한다고 한다!
최근에 UMAP이라는 것도 알아서 써볼만 한 것 같지만, 여전히 Neural Network 기반으로 하는 것이 매력적이기 때문에
알아보다가 찾은 것이다
이 CNN으로 하겠다는 것이 참 신기했고 글을 읽어보니 그럴듯하다 생각했다.
왜냐하면 CNN도 그 Feature의 Locality를 잡아서 특징을 잘 잡아주는 것이고,
테이블 데이터 간의 Locality를 잡아준다는 것은, 먼가 변수들끼리의 새로운 파생을 생성할 수 도 있다는 생각이 들었다!
Why Automated feature engineering:
기존에는 도메인과 비즈니스 지식을 바탕으로 수동으로 열심히 파생변수를 만들었다.
이런 것을 handcrafted feature engineering이라고 한다.
이러한 전문가적 지식은 절대 무시할 수 없지만, 이러한 것에도 단점이 있다고 한다.
1. Tedious
수동으로 하는 Feature Engineering은 굉장히 지루한 작업이다.
기존 변수에서 얼마나 많은 변수를 어떻게 생성해야 할지?
나도 기존에 해보려고 했는데, 머리를 쥐어짜도 잘 나오지 않는다. 특별히 유의미한 것도 만들기도 어렵다.
만약 우리가 date 데이터가 있다면 여기서 우리가 생각할 수 있는 것은
[ month , year , hour , day in the week] , 다른 분석가는 머 (weekend indicator, festive season indicator, X-mass month indicator, seasonality index, week no in a month and so on) 이런 것을 만들었다고 하자.
그러면 이렇게 만든 것이 다른 변수와 어떻게 상호작용이 있을까요??
그래서 이러한 수동적인 feature engineering은 시간적으로도 많이 들고, 상상력도 한계가 있다.
2. Influence of Human Bias:
특정 도메인 / 모델링 프로젝트에 종사하는 사람보다 더 자주 (특히 이전 분석가가 작성한 경우) 모델에 가치를 추가할지 여부와 상관없이 일부 기능에 대한 깊은 편향을 형성합니다.
결국 사람에 따라 Bias가 생길 수밖에 없다는 것이죠!
이런 것 때문에 통계는 거짓말이라는 말도 있는 것 같습니다 (데이터는 무죄, 조작한 사람 유죄)
Business Problem and CNN relevance
저자의 글에선 credit data에다가 적용을 시키는데
cross-sectional components(Gender , Education) 같은 것에는 적용 안 하고,
time-series변수들(balance , payment history)에 적용했다고 합니다.
으음 왜 이렇게 했을까요? 흐음 굳이 다 안 한 이유가 있을까요?라는 생각이 드네요.
시간적인 부분에만 한 게 CNN이라서 그런 건지.... 흐음
Representation of data in CNN format:
모두 아시다시피, 이미지 분야에 CNN이 접목되면서, 엄청난 성공을 보여준 걸 알 수 있습니다.
그래서 개인적으로 CNN 때문에 딥러닝이 떴다고 생각합니다.
그냥 Fully Connected는 영 아닌 것 같습니다. 그래서 요즘 계속 찾는 것도 Structured Data에 CNN을 접목시키는 것을 찾아보고 있습니다.
파라미터 개수를 어떻게든 줄여야 잘 될 것 같다는 생각이 항상 듭니다!
여기 글을 쓴 사람도 왜 CNN이 유명했는지 말하는 게 이유가 다음과 같습니다.
1. Reduced Parameter (parameter sharing)
모든 것을 연결할 필요 없이 kernel이라고 하는 receptive filed를 통해서 파라미터를 공유하면서, Local Connectivity 가지게 되는데요. 이것과 비교하면 기존 ANN은 파리 미터가 미친 듯이 많습니다.
2. Shift/Translation In-variance:
인풋이 이동할 때 아웃풋도 이동하고 , 가만히 있으면 변하지 않는다는 의미입니다.
그래서 이미지에서 여러 가지고 고양이가 다른 위치들이 있어도 고양이로 인식하는 거죠!
To specific our data we have time series horizons of events(balance, payments etc.) for an individual customer, which makes the data full of local patterns for her and hence these parameters can be shared across customers.
우리의 데이터를 구체적으로 나타 내기 위해 개별 고객을 위한 일련의 시간대 (균형, 지불 등)가 있으므로 데이터를 현지 패턴으로 가득 차게 만들고 이러한 매개 변수를 고객 간에 공유할 수 있습니다.
이러한 이유로 CNN에 접목시킬 수 있다고 한 것 같네요!
으음 개인적으로 잘 해석은 안되지만, 결국 개별 고객들은 다 같은 시간에 속하므로, 고객들 사이에 Parameter들은 공유가 가능하고 그러한 면에서는 CNN을 적용해도 된다? 이런 느낌인 것 같네요! 그래서 아까 시간 변수들만 한다고 했나 봅니다.
그래서 다시 CNN구조를 사용하기 위해 이미지처럼 네모난 구조로 만들어줍니다.

방식은 다음과 같습니다. 고객 개수 N명
m features(here balance/payment etc.)
t time horizons(here month1, month2 etc.)
p different trades(trades are different lines of credit, such as retail cards, mortgage etc.).
총 그래서 다음과 같은 형태로 나옵니다. N*m*t*p
Data preparation:
여기선 기존 데이터가 trade-retail card 2개로 이루어져있다고 한다.
먼가 더 도전적이고 더 관련성 있게 만들기 위해서 morgage라는 추가적인 더미 세트로 했다는데
(이유 없이 왜 하는지는...?) 아무튼 그렇게 해서 채널 2개를 만들었다!
상상해보자면 만약 실제로 다른 테이블 데이터도 같이 있다면, 연동하기 위해서라고 긍정적으로 생각해보자
Precisely for our data the dimension for each customer will be 3(no of features) * 6(time horizons) * 2(trades) and there will be 30000 frames of this dimension.



Feature extraction from CNN
이제 CNN으로 한다음 마지막에는 2개의 타깃에 대해서 Classification 하는 구조로 열심히 만든다.
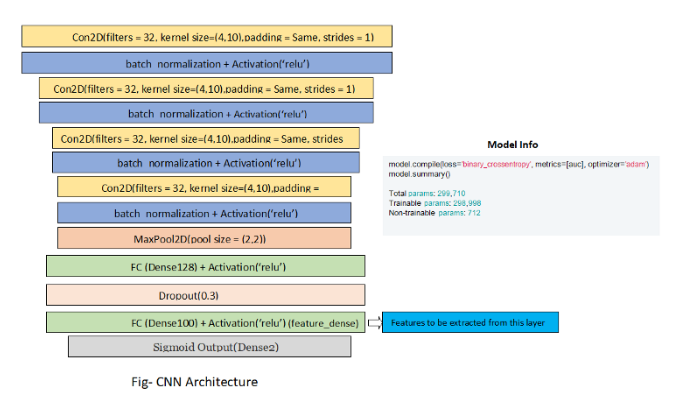
위에 이미지에서 파랑색깔을 새로운 feature로 쓰겠다고 한다.
왜 저기를 쓸까? 끝부분에 가장 많은 추상화가 돼서 그런가?
그래서 100개의 변수를 생성해서 쓸껀데, 나중에 또 Network를 다시 설정할 필요 없이 중간 layer로 바로 맵핑하는 것을 알아야 한다고 한다.
암튼 그렇게 얻은 데이터로 간단하게 target값과 correlation을 구해서 실제 새로나온 변수가 유의미성이 있는지 확인해본다.
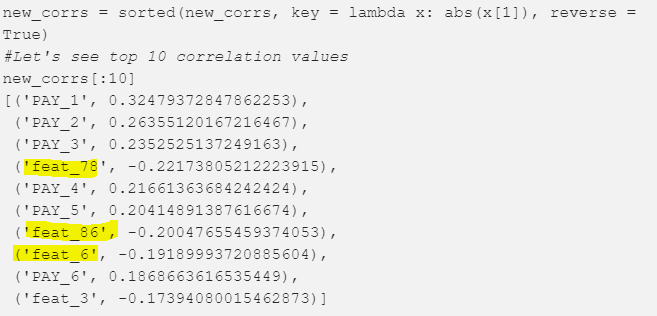
새로 나온 변수가 top10안에 든다! 먼가 기대가 될 것 같다!
Emphasizing CNN for feature extraction (평소에 궁금한 부분!)
왜 CNN을 오로지 feature extraction으로 사용하고 Classifier로는 사용하지 않을까에 2가지 이유가 있다고 한다!
- Local Pattern
- Structural data에는 cross sectional(static) 변수가 포함되어있다 (나이 종교...)
- 이 사람은 여기서 어떠한 Local Pattern을 찾지 못했다고 한다.
- 그래서 Classifier를 전체 데이터에다가 CNN을 사용하지 않았다고 한다.
- 만약 데이터에 Shift/Translation Invariance 성질이 있다면 CNN을 분류모델로 사용했을 것이다라고 한다.
- Infrastructural challenge
- GPU가 필요한데, 평소 다른 기관들이 그런걸 가질 리가 없어서?
- 으음?
- Latency in model run
- 실제로 이러한 구조도 만들려고하다보면 기존 머신러닝인 xgboost 같은 것보다 훨씬 시간이 오래 걸린다.
- 실제로 빠른 설루션을 많이 요구한다.
- 그래서 보통 CNN을 이용해서 feature를 잘 extraction 해서 머신러닝 모델을 사용해서 한다고 한다.
4. Regulatory challenge
은행, 보험, 같은 도메인에서 AI에 많은 관심을 가지고 있지만, 시행하기 전에 여러 가지 규제를 통과해야 한다고 한다.
의미 있는 특징 공간을 만드는 것의 중요성은 과장될 수 없으며 자동화된 피쳐 엔지니어링 기술은 피쳐 생성 문제로 원시 데이터 세트에서 수백 또는 수천 개의 새로운 기능을 완벽하게 구축하는 데 도움이 되는 것을 목표로 합니다.
그러나 이것이 데이터 사이언티스트를 대체하지는 못할 것이라고 합니다.
오히려 그들은 머신러닝의 다른 부분에 더 신경을 쓸 수 있게 될 것입니다.(변수 선택, 새로운 방법론 탐색 등등)
이렇게 automated feature engineering에 대해서 알아봤는데,
개인적으로 CNN으로 하는 이 아이디어는 참 신통방통 그 자체라는 게 결론이고,
내 데이터 상황에 잘 맞는다면 Structured data에도 적용 가능하다는 게 참 인상적이었습니다.
참고
https://github.com/nitsourish/CNN-automated-Feature-Extraction
nitsourish/CNN-automated-Feature-Extraction
This repository consists code for the feature creation from structured data using CNN technique, along with input data and output data - nitsourish/CNN-automated-Feature-Extraction
github.com
towardsdatascience.com
'관심있는 주제 > 뉴럴넷 질문' 카테고리의 다른 글
| Designing Your Neural Networks 리뷰 (0) | 2019.09.26 |
|---|---|
| AutoEncoder를 사용하여 희귀케이스 잡기 (0) | 2019.06.01 |
| hidden layer 수와 Node를 몇개나 해야 할 지에 대한 글 (0) | 2019.05.23 |
| Neural Network를 학습하기 전에 Normalize를 왜 해줘야 할까? (1) | 2019.05.17 |
| NN에서 Categorical Variables에 대해서는 어떻게 해야할까? (0) | 2019.05.06 |