https://towardsdatascience.com/designing-your-neural-networks-a5e4617027ed
Designing Your Neural Networks
A Step by Step Walkthrough
towardsdatascience.com
What’s a good learning rate?
How many hidden layers should your network have?
Is dropout actually useful?
Why are your gradients vanishing?
모델링을 하다 보면 이런 질문들이 나올 수 있다.
이 포스트에서는 네트워크 아키텍처를 만들 때의 팁들을 제시한다.
이것을 포스팅하는 이유는 중간에 activation에 따라서 어떠한 것이 좋다고 설명을 하고 있는 부분이 끌려서 시작하게 됐다.
https://www.kaggle.com/lavanyashukla01/training-a-neural-network-start-here
Training a Neural Network? Start here!
Using data from no data sources
www.kaggle.com
이 캐글 자료도 보면 도움이 될 것 같다.

Input neurons
보통 인풋 뉴런은 예측을 하기 위해 필요한 피처의 개수로 설정한다.
인풋 벡터는 한 피쳐당 한 개의 인풋이 필요하다.
만약 mninst 28x28을 FCN으로 하게 되면 1줄로 돼야 하기 때문에 784가 필요할 것이다.
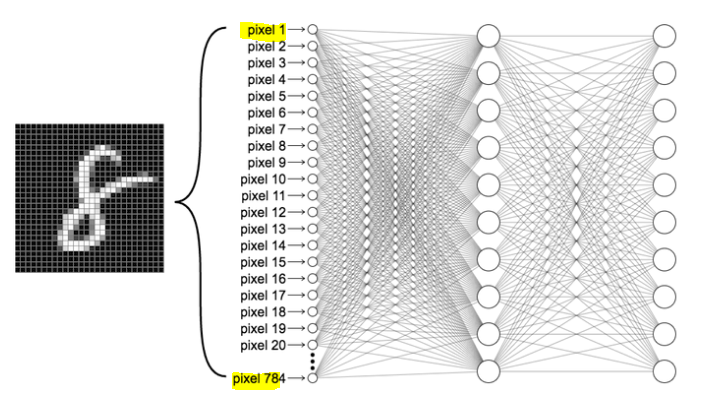
Output neurons
원하는 예측을 하기 위한 것이기 때문에 마지막은 예측의 경우의 수라고 할 수 있다.
Regression : 회귀분석처럼 1개
Classification : binary(스팸 o 스팸 x) / multi class
Hidden Layers and Neurons per Hidden Layers
hidden layer의 수는 문제를 해결하는데 가장 중요하다고 할 수 있다.
너무 크게도 안되고,, 너무 작게도 안되고,,, 적당하게...
대부분의 문제는 1~5 hidden laye r면 충분하다고 한다.
이미지 또는 음성 데이터를 사용할 때 네트워크에 수백 개의 계층이 있어야 하며, 이 계층이 모두 완전히 연결되지는 않아야 한다.
그래서 보통 이런 데이터를 처리할 때 이미 학습된 YOLO ResNet VGG 같은 모델을 쓰고 인풋이나 아웃풋을 조정해서 쓸 것이다. 왜냐하면 그 중간에 hidden layer는 잘 학습된 것이기 때문에 조금만 학습시켜도 충분히 원하는 결과에 더 빨리 얻을 수 있을 것이다.
일반적으로 모든 히든 레이어에 같은 수를 해도 충분하다
몇몇 데이터에서는 처음에는 크게 주고 점점 갈수록 작게 하는 방식으로
첫 번째 히든 레이어의 lower level features를 잘 학습시키고 점점 줄어가게 모델링해서 그 뒤에서는 higher order feature를 학습시킬 수 있다.

- 보통, 각 층에 더 많은 뉴런을 추가하는 것보다 더 많은 층을 추가함으로써 더 많은 성능 향상을 얻게 될 것이다.
- 1-5개의 층과 1-100개의 뉴런으로 시작하고 오버핏을 시작할 때까지 천천히 더 많은 층과 뉴런을 추가하는 것을 추천한다. Weights and Biases 대시보드 내에서 손실과 정확성을 추적하여 어떤 히든 층 + 히든 뉴런 캄보가 최선의 손실을 유발하는지 확인할 수 있다. Weight와 Bias 추적해보기
- 더 적은 수의 레이어/뉴런을 선택할 때 명심해야 할 점은 이 수가 너무 적으면 당신의 네트워크는 당신의 데이터에 있는 기본 패턴을 배울 수 없기 때문에 쓸모가 없다는 것이다. 이에 대응하기 위한 접근법은 엄청난 수의 히든 층 + 히든 뉴런에서 시작하여 중퇴와 조기 중지를 사용하여 신경 네트워크의 크기를 줄이는 것이다. Weight Bias의 몇며의 조합을 추적해봐라
- Andrej Karpathy also recommends the overfit then regularize approach 일단은 train loss에 초점을 맞춰라 overfitting 시켜라 그리고 적절하게 regularize를 걸어줘라 그러면 모델은 더 좋아질 것이니!
overfit then regularize approach
A Recipe for Training Neural Networks
Some few weeks ago I posted a tweet on “the most common neural net mistakes”, listing a few common gotchas related to training neural nets. The tweet got quite a bit more engagement than I anticipated (including a webinar :)). Clearly, a lot of people have
karpathy.github.io
Loss function
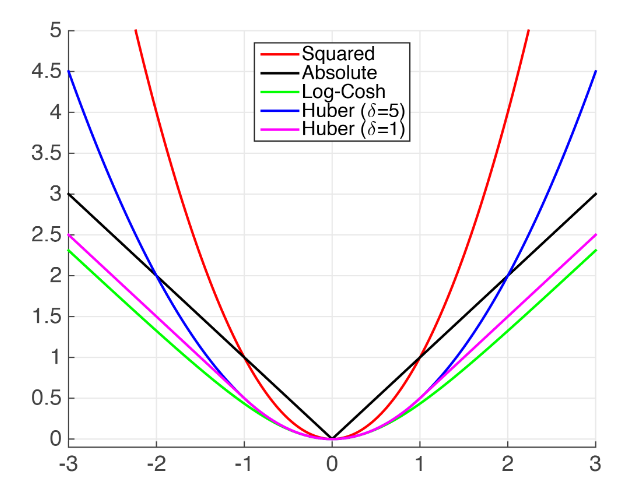
Regression : 만약에 Outlier가 없다면 MSE는 흔하게 사용하는 방식이다. 그러나 있다면 MAE 나 Huber Loss를 사용해라
Classification: Cross-entropy
Batch Size
- 큰 배치 크기는 GPU의 힘을 활용하여 시간당 더 많은 교육 인스턴스를 처리할 수 있기 때문에 훌륭할 수 있다. OpenAI는 큰 배치 사이즈가(이미지 분류 , 언어 모델링 강화 학습 agent) 같은 경우에 확장 및 병렬화에 잘 된다는 것을 발견했다.
- 작은 배치도 물론 잘되는 분야가 있다. 그러나 다음과 같은 논문에서는 대형 배치를 실행함으로써 병렬화가 증가하여 얻는 이점은 성능 일반화 증가와 더 작은 배치에 의해 달성되는 더 작은 메모리 풋프린트로 상쇄된다. 논문에서 말하기를 큰 배치 사이즈는 안정적인 수렴을 하게 하는 learning rate의 수용 가능한 범위를 줄일 수 있다. 그들은 배치 크기가 증가하면 안정적인 정합성을 제공하는 허용 가능한 학습 속도가 감소한다는 것을 보여준다.
- 만약 큰 스케일에서 크지 않다면, 배치 사이즈를 작은 것부터 시작해서 점점 크게 해서 Weight Bias를 잘 모니터링해라
Number of epochs
Epoch 은 크게 / Early Stopping은 사용하고
Scaling your features

무조건 네트워크의 인풋은 사용하기 전에 유사한 스케일로 조정해줘야 한다.
그렇게 해야 더 빠르게 수렴할 수 있다. 만약 스케일이 다르면 왼쪽 그럼처럼 될 것이다.
위의 그림에서 알 수 있듯이 normalized 한 것과 비교해보면 왼쪽 꺼의 최적화 알고리즘은 더 오랜 시간이 걸릴 것이다.
2. Learning Rate

- Learning rate를 잘 선택하는 것은 중요! 네트워크의 다른 하이퍼 매개 변수를 조정할 때 학습 속도를 다시 줄이십시오.
- 최적의 Learning rate를 찾기 위해서는 아주 작은 10^-6에서 시작해서 10을 점점 곱해라. Weights and Bases 대시보드에서 모델 성능(학습 속도 로그 vs)을 측정하여 어느 비율이 문제에 적합한지 확인!
- 최고의 학습률은 대개 모델을 분화시키는 학습률의 절반이다. 코드에서 learn_rate에 대해 다양한 값을 설정하고 이것이 모델 성능에 어떤 영향을 미치는지 확인하여 학습 속도에 대한 직관을 발전시켜라
- Learning Rate finder 방법을 사용하는 것을 추천한다고 한다. 이 것은 대부분 Gradient Optimizer에서 잘 찾아준다. (Cyclical Learning Rates)
https://arxiv.org/abs/1506.01186
Cyclical Learning Rates for Training Neural Networks
It is known that the learning rate is the most important hyper-parameter to tune for training deep neural networks. This paper describes a new method for setting the learning rate, named cyclical learning rates, which practically eliminates the need to exp
arxiv.org
3. Momentum

- Gradient Descent는 Local Minima를 향해 작고 일관된 단계를 밟으며 경사가 작을 때는 수렴하는 데 많은 시간이 걸릴 수 있다. 반면에 momentum은 이전에 gradient를 고려해서 local minima를 벗어사고 수렴을 가속화할 수 있다.
- 일반적으로, 모멘텀은 1에 가깝길 원할 것이다. 0.9는 작은 데이터 셋에 좋다. 0.999는 큰 데이터에 좋다. nesterov=true를 설정하면 모멘텀이 현재 시점보다 몇 단계 앞서 비용 함수의 구배를 고려하게 되므로 약간 더 정확하고 빠르게 된다.
4. Vanishing + Exploding Gradients
- 사람처럼 모든 뉴럴 네트워크가 동일한 스피드로 학습을 하지는 않는다. 그래서 backprop algorithm은 output -> first layer로 error gradient를 전파할 때 gradient는 점점 첫 번째 layer로 갈수록 작아진다. 이것은 각 스텝에서 첫번째 weight 가 학습이 안된다는 의미이다.
- 이러한 문제를 vanishing gradient라고 한다. 반대는 exploding gradient
- 몇 가지 해결책이 있다.
Activation functions
Hidden Layer Activation
improves in this order (from lowest→highest performing):
logistic → tanh → ReLU → Leaky ReLU → ELU → SELU.
Relu는 가장 유명한 함수이다. 만약 네가 당기는 것이 없다면 relu는 좋은 시작이 된다.
그러나 relu는 elu 나 gelu보다 덜 효과적이다

머 항상 맞는 것은 아니긴 하겠지만 결국 핵심은 Weight Bias의 Dash Board를 해석할 수 있는 능력이 필요하다! 이 말만 거의 4번 나온 듯...
Output Layer Activation
Regression : No Activations 상황에 따라서 (-1,1) tanh (0,1) sigmoid (positive) softplus
Classification : Binary-> Sigmoid / Multi -> Softmax
Weight initialization method

BatchNorm
- BatchNorm은 단순히 각 계층의 입력에 대한 최적의 평균과 분산을 배운다. 그것은 입력 벡터를 제로 센터링하고 정상화시킨 다음 스케일링하고 이동시킴으로써 그렇게 한다. 이것을 하게 되면 dropout 도 필요 없고 L2도 필요 없다.
- BatchNorm을 사용하면 큰 Learning rate를 사용해도 된다. 더 빠르게 수렴한다. 그리고 대부분 vanishing gradient 문제를 감소함으로써 더 큰 성능을 만들 수 있다. 단 한 가지 단점은 각 계층에 필요한 추가 연산 때문에 훈련 시간을 약간 증가시킨다는 것이다.
- 짱짱맨?
Gradient Clipping
- exploding 하는 gradient를 감소하는 가장 좋은 방법은 특정 값을 넘으면 clip을 거는 것이다.
- clip value 보다는 clip norm을 추천
- clip norm은 gradient vector의 방향을 일정하게 해 주기 때문이다.
- Clipnorm은 l2 표준이 특정 임계값보다 큰 구배를 포함한다.
- 최적을 찾기 위해 여러 가지 다른 threshold를 시도해봐라
Early Stopping
도중에 학습이 안 하는 게 낫다
5. Dropout
- Dropout은 간단하게 좋은 성능을 줄 수 있는 훌륭한 regularization 방법이다
- 학습단계에서 Dropout은 각각의 Layer에서 임의의 로 node를 죽이는 것(끄는 것)이다.
- 이것은 네트워크를 Robust 하게 만든다. 왜냐하면 이렇게 하게 되면 특정 Layer에 특정 Node에 의존하지 않게 되기 때문이다. 그 지식은 네트워크 전체에 분포되어 있다.
- 약 2^n (여기서 n은 구조상 뉴런의 수) 약간 독특한 신경망이 훈련 과정 중에 생성되어 함께 결합되어 예측을 한다.
- 좋은 Dropout은 0.1 ~ 0.5 / 0.3 = RNN 0.5 = CNN / 더 큰 Layer를 사용해라
- Dropout Rate를 증가시키는 것은 Overfitting을 감소시킨다. 그리고 이 비율을 줄이는 것은 언더 피팅 전투에 도움이 된다.
- 결국 여러 가지 실험은 필요하다 초기에 네트워크의 Layer들의 Weight와 Biases를 보라
- 마지막 Layer에는 Dropout을 사용하지 마라
- Batch Norm과 Dropout을 결합해서 사용해라 https://arxiv.org/abs/1801.05134
- 이 저자는 AlphaDropout 사용 이것은 인풋의 평균과 편차를 보존하는 Selu랑 같이 쓸 때 잘된다
6. Optimizers

- 일반적인 조언은 만약 당신이 수렴의 질에 대해 깊이 관심을 갖고 시간이 본질에 속하지 않는다면 Stochastic Gradient Descent를 사용하라는 것이다.
- 수렴까지의 시간에 관심이 있고 최적의 수렴에 가까운 지점으로 충분하다면 아담, 나담, RMSProp, Adamax 최적기를 사용해 보십시오. 여러분의 Weight와 Biases 대시보드는 여러분에게 가장 적합한 최적기로 여러분을 안내해 줄 것이다!
- Adam/Nadam are usually good starting points, and tend to be quite forgiving to a bad learning late and other non-optimal hyperparameters.
- According to Andrej Karpathy, “a well-tuned SGD will almost always slightly outperform Adam” in the case of ConvNets.
- Nadam 사용 / Adam과 Nesterov tric을 같이 사용 -> Adam보다 더 빠르게 수렴
7. Learning Rate Scheduling

너무 크게 Learning rate를 하지 마라 너무 작게 하면 너무 오래 걸린다.
Babysitting learning rate는 까다롭다 왜냐하면 낮은 것과 높은 것 둘 다 이점이 있기 때문이다.
이럴 때 Learning rate scheduing을 사용하면 된다.
I show you how to use the ReduceLROnPlateau callback to reduce the learning rate by a constant factor whenever the performance drops for n epochs.
recommend also trying out 1 cycle scheduling.
Use a constant learning rate until you’ve trained all other hyper-parameters.
As with most things, I’d recommend running a few different experiments with different scheduling strategies and using your Weights and Biases dashboard to pick the one that leads to the best model.
8. A Few More Things
- Try EfficientNets to scale your network in an optimal way.
- Read this paper for an overview of some additional learning rate, batch sizes, momentum and weight decay techniques. https://arxiv.org/pdf/1803.09820.pdf
- And this one on Stochastic Weight Averaging (SWA). It shows that better generalization can be achieved by averaging multiple points along the SGD’s trajectory, with a cyclical or constant learning rate.
- Read Andrej Karpathy’s excellent guide on getting the most juice out of your neural networks.
> 핵심 : Weight , Biases를 잘 봐야 한다.
'관심있는 주제 > 뉴럴넷 질문' 카테고리의 다른 글
| TABNET: ATTENTIVE INTERPRETABLE TABULAR LEARNING -1 (0) | 2020.01.05 |
|---|---|
| What is Label Smoothing? - 리뷰 (Overconfidence) (0) | 2020.01.04 |
| AutoEncoder를 사용하여 희귀케이스 잡기 (0) | 2019.06.01 |
| [변수 생성]Structured Data에서 CNN을 활용한 새로운 변수 생성하기 (0) | 2019.05.27 |
| hidden layer 수와 Node를 몇개나 해야 할 지에 대한 글 (0) | 2019.05.23 |