https://github.com/sungreong/toon-output-parser
GitHub - sungreong/toon-output-parser
Contribute to sungreong/toon-output-parser development by creating an account on GitHub.
github.com

🚀 TOON: JSON의 '토큰 세금'을 해결할 차세대 데이터 포맷
최근 LLM(대규모 언어 모델) 기반 서비스를 운영하면서 가장 큰 고민 중 하나는 바로 토큰 비용입니다. 우리가 흔히 사용하는 JSON 형식은 구조가 명확하지만, LLM과 대화할 때는 불필요한 비용을 발생시키는 '비싼 포맷'이 되기도 하죠.
이러한 문제를 해결하기 위해 등장한 **TOON(Token-Oriented Object Notation)**의 탄생 배경과 핵심 가치를 정리해 드립니다.
1. 왜 JSON은 LLM에게 '비싼' 포맷일까? (토큰 세금 문제)

OpenAI나 Google 같은 LLM API는 텍스트의 길이에 따라 비용을 부과합니다. 하지만 JSON은 데이터를 감싸는 중괄호{}, 따옴표"", 쉼표, 같은 기호가 너무 많습니다.
특히 같은 형식의 데이터가 반복되는 리스트(배열)를 보낼 때, 매번 똑같은 '키(Key)' 이름을 반복해서 적어야 합니다. 개발자에게는 익숙하지만, API 비용 측면에서는 **불필요한 '토큰 세금'**을 내고 있는 셈입니다.
2. TOON의 해결책: 효율성을 극대화하는 세 가지 전략
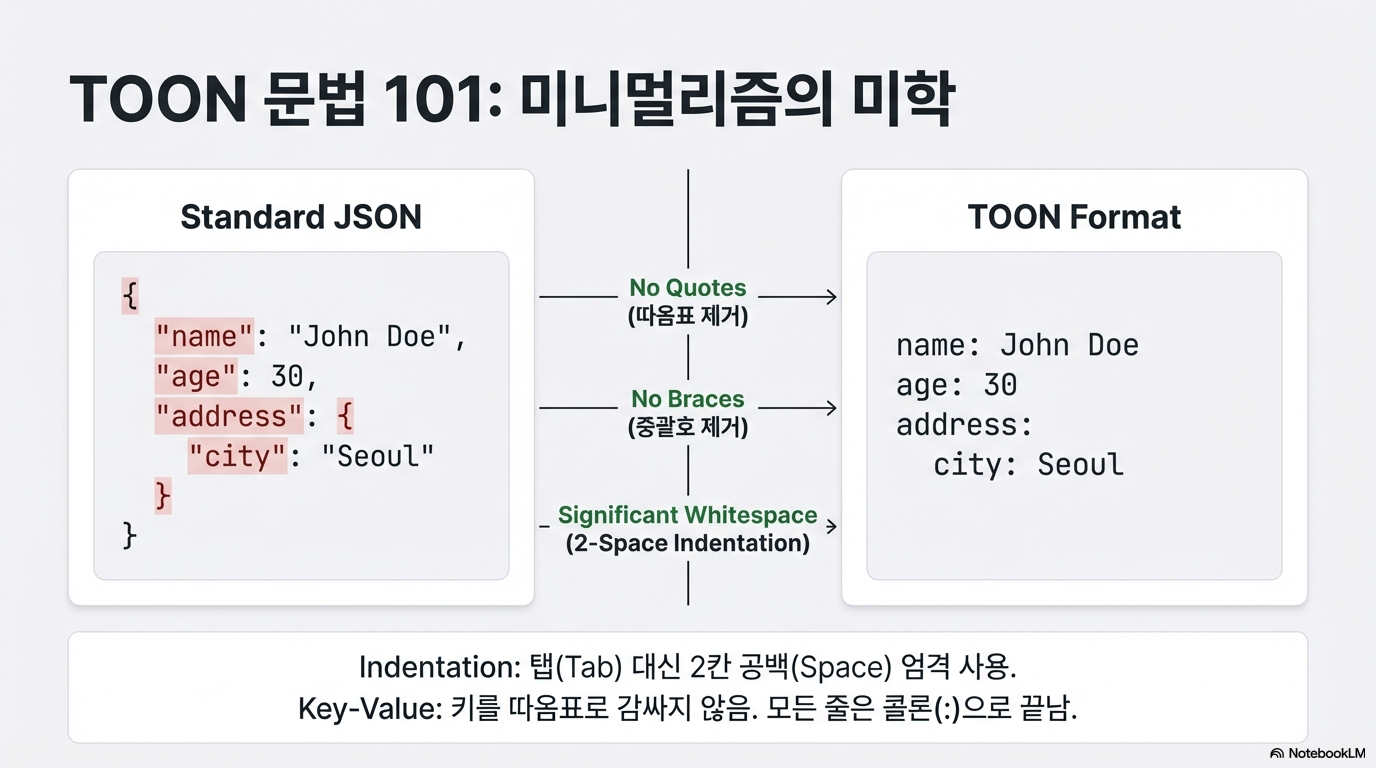
TOON은 JSON의 구조적 낭비를 제거하고 효율성을 극대화하기 위해 세 가지 영리한 방식을 도입했습니다.
- 들여쓰기(Indentation) 구조: YAML처럼 들여쓰기를 활용해 중첩 구조를 표현합니다. 수많은 중괄호가 사라집니다.
- 표 형식의 배열(Tabular Arrays): CSV 방식처럼, 반복되는 객체 배열에서 헤더(키)를 상단에 한 번만 선언하고 값만 나열합니다. 이 방식은 토큰 낭비를 획기적으로 줄여줍니다.
- 스마트 따옴표: 꼭 필요한 경우가 아니면 따옴표를 생략하여 불필요한 문자를 최소화했습니다.
결과: 특정 시나리오에서는 JSON 대비 **최대 97%**의 토큰을 절감할 수 있으며, 평균적으로도 **30~60%**의 비용 효율을 보여줍니다.
3. 비용은 줄이고, 정확도는 높이고!

TOON은 단순히 아끼기만 하는 도구가 아닙니다. LLM이 데이터를 더 정확하게 처리할 수 있도록 설계되었습니다.
- 배열 길이 명시: [N]과 같이 배열의 길이를 미리 알려주어 LLM이 데이터를 빠뜨리지 않게 돕습니다.
- 환각(Hallucination) 방지: 데이터 구조가 명확히 선언되어 있어 파싱 오류가 줄어들고, JSON보다 더 높은 출력 정확도를 유지합니다.
4. 개발자를 위한 '스마트 번역 계층'
TOON은 JSON을 완전히 대체하려는 것이 아닙니다. 코드 내부에서는 익숙하고 견고한 JSON/Pydantic 모델을 그대로 사용하되, LLM과 통신하는 순간에만 TOON이라는 압축 포맷으로 변환하는 '스마트 번역기' 역할을 합니다.
이를 통해 개발자는 코드의 안정성을 유지하면서도 운영 비용을 극적으로 낮추고 응답 속도를 높일 수 있습니다.
🚀 TOON Output Parser: LLM 비용을 최대 97% 줄이는 랭체인 파서

TOON Output Parser는 랭체인(LangChain) 생태계에서 데이터 구조의 안정성은 유지하면서, LLM API 비용은 혁신적으로 줄이기 위해 개발된 오픈소스 프로젝트입니다.
1. 개발 배경: 왜 'TOON'인가?
LLM 서비스를 운영할 때 우리는 늘 "엄격한 신뢰성(JSON)"과 "비용 효율성(Token)" 사이에서 고민합니다. JSON은 명확하지만, 불필요한 중괄호와 반복되는 키(Key) 이름 때문에 '토큰 세금'이 과하게 발생합니다.
TOON Output Parser는 이 사이의 가교(Bridge)가 되어줍니다. 개발자는 익숙한 Pydantic 모델로 코딩하고, LLM과는 압축된 TOON 포맷으로 대화하게 하여 성능과 비용이라는 두 마리 토끼를 모두 잡았습니다.
2. 핵심 기능 및 압도적 성능
- ⚡ 극적인 비용 절감: 일반적인 추출 작업에서 30~60%, 특정 시나리오에서는 **최대 97%**까지 토큰 사용량을 줄입니다.
- 🧠 적응형 가이드라인 (Adaptive Instructions): 데이터 모델의 복잡도를 파서가 스스로 분석합니다.
- Minimal Mode: 단순한 구조에서는 최소한의 설명만 제공해 입력 토큰을 아낍니다.
- Official Mode: 복잡한 구조에서는 상세 가이드를 제공해 정확도를 높입니다.
- JSON Fallback: 구조가 너무 깊어지면(Depth 6 이상) 자동으로 안전한 JSON 모드로 전환합니다.
- 📊 테이블 형식 배열 (Tabular Arrays): 상품 목록이나 뉴스 리스트처럼 반복되는 데이터 구조를 처리할 때, CSV처럼 헤더를 한 번만 선언합니다. 반복되는 키(Key) 값을 획기적으로 제거하는 핵심 기술입니다.
3. 작동 원리 (Workflow)
- Define (정의): 평소처럼 Pydantic으로 데이터 구조를 정의합니다.
- Translate (번역): 파서가 모델을 분석해 LLM용 '최소 지침'을 생성합니다. (입력 토큰 절약)
- Inference (추론): LLM이 기호가 생략된 압축 포맷(TOON)으로 응답합니다. (출력 토큰 절약)
- Restore (복원): 파서가 응답을 다시 Python 객체로 변환하고 유효성을 검증합니다.
4. 사용 시 참고사항 (Beta)
현재 이 프로젝트는 지속적으로 발전 중인 단계로, 아래 사항을 고려하면 더 효율적으로 사용할 수 있습니다.
- 네이밍 규칙: 필드 이름에 ., :, -(시작 위치) 사용은 지양해 주세요.
- 들여쓰기의 중요성: TOON은 2칸 들여쓰기로 구조를 파악하므로, LLM이 구조를 잘 지키도록 유도하는 것이 중요합니다.
- 적정 깊이: 데이터 계층이 6단계 이하일 때 최적의 성능을 발휘합니다.
코드
from toon_langchain_parser import ToonOutputParser
from pydantic import BaseModel, Field
class UserInfo(BaseModel):
name: str = Field(..., description="User's full name")
age: int = Field(..., description="User's age")
hobbies: list[str] = Field(default_factory=list, description="List of hobbies")
# ToonOutputParser automatically chooses the best mode (minimal, adaptive, or json)
parser = ToonOutputParser(model=UserInfo)
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# IMPORTANT: Include {format_instructions} in your prompt
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "Describe {input}\n\n{format_instructions}")
])
format_instructions = parser.get_format_instructions()
chain = prompt | llm | parser
result = chain.invoke({
"input": "John, 25 years old, likes soccer and coding.",
"format_instructions": format_instructions
})
print(result) # UserInfo(name='John', age=25, hobbies=['soccer', 'coding'])
현재 Toon Output Parser 한계점

TOON은 강력한 비용 절감 도구이지만, 모든 상황에서 완벽한 '은탄환'은 아닙니다. 현재 단계에서 사용자가 인지해야 할 주요 제약 사항과 비용 구조를 정리했습니다.
1. JSON 대비 제한적인 포맷 지원
JSON은 수십 년간 표준으로 자리 잡으며 매우 복잡하고 다양한 데이터 타입을 지원합니다. 반면 TOON은 '압축'과 '효율'에 집중하되 가독성을 유지해야 하므로, 아직은 지원하는 데이터 구조에 한계가 있습니다.
구조적 제약: 아주 깊은 계층(6단계 이상)이나 자기 참조(Recursive) 구조에서는 파싱 정확도를 위해 자동으로 JSON 모드로 전환됩니다.
유연성: JSON은 필드 이름에 특수문자를 비교적 자유롭게 쓰지만, TOON은 구조 해석을 위해 일부 특수문자(., :, -) 사용에 제한이 있습니다.
2. '학습 비용'의 역설 (Context Overhead)
TOON은 LLM이 기본적으로 알고 있는 포맷이 아닙니다. 따라서 LLM에게 "이제부터 TOON 방식으로 대답해"라고 가르치는 **가이드라인(Instruction)**을 프롬프트에 포함해야 하며, 여기서 '초기 비용'이 발생합니다.
초기 비용(Setup Cost): 아주 짧은 단답형 응답의 경우, TOON 형식을 설명하는 가이드라인 토큰이 실제 데이터 절약분보다 클 수 있습니다.
손익분기점: 데이터의 양이 많아질수록(예: 10개 이상의 아이템을 가진 리스트 추출), 가이드라인 비용은 고정되고 데이터 압축률은 극대화되어 전체적인 비용 이득이 커집니다.
🎁 마치며: 효율과 신뢰 사이의 새로운 균형점을 찾아서
이번 프로젝트를 통해 LLM API 비용의 고질적인 문제인 '토큰 세금'을 해결하고자 TOON Output Parser를 개발해 보았습니다.
단순히 데이터를 압축하는 것을 넘어, TOON(Token-Oriented Object Notation)이라는 새로운 구조를 통해 LLM과 더 경제적으로 소통할 수 있는 방법을 고민한 결과물입니다. 개발 과정에서 느낀 핵심적인 포인트는 다음과 같습니다.
- 성능의 확실한 체감: 복잡하지 않은 구조에서 JSON이 낭비하던 토큰을 TOON으로 전환했을 때, 비용 절감 효과는 기대 이상으로 확실했습니다.
- 인정해야 할 Trade-off: 모든 기술이 그렇듯 TOON 역시 비용이 발생합니다. LLM에게 새로운 문법을 학습시켜야 하는 '초기 컨텍스트 비용(Context Overhead)'은 분명히 존재하며, 이는 데이터의 양과 구조에 따라 전략적으로 선택해야 할 몫이라는 점을 배웠습니다.
TOON Output Parser는 이제 막 첫발을 떼었습니다. 아직 부족한 점도 많고, 더 개선해야 할 포맷 지원도 남아 있습니다.
이 도구가 여러분의 LLM 애플리케이션 운영 비용을 줄이는 데 실질적인 도움이 되기를 바랍니다. 더 나은 프로젝트로 발전할 수 있도록, GitHub에 방문하셔서 많은 피드백과 아이디어, 그리고 기여를 부탁드립니다!
👉 TOON Output Parser GitHub 저장소 방문하기
'관심있는 주제 > LLM' 카테고리의 다른 글
| 논문 리뷰-단일 시맨틱 검색의 한계-On the Theoretical Limitations ofEmbedding-Based Retrieval (2) | 2025.12.20 |
|---|---|
| OpenAI-Context Engineering 가이드(2025.09) 공부해보기 (1) | 2025.11.02 |
| LangChain 디버깅 가이드: 빠르게 훑고 깊게 파보는 3가지 방법 (0) | 2025.10.25 |
| MemOS: LLM 의 "Memory Operating System" 메모리 관련된 개념 이해하기 (4) | 2025.07.12 |
| MemOS: 대형 언어 모델을 위한 메모리 운영체제-논문 리뷰 및 정리 (5) | 2025.07.12 |