제가 요즘 관심 있는 것은 생성 모델 중에 GAN이라는 알고리즘입니다.
저는 특히 Tabular Data를 GAN을 활용해, 생성하는 것에 관심이 있어서 해당 논문에 대해서 디테일하게 설명하지는 못하지만, 직관적으로 제가 이해한 만큼만 작성해보려고 합니다.
| Paper : https://arxiv.org/abs/1811.11264 | Code : https://github.com/DAI-Lab/TGAN |
이 논문을 제가 선택한 이유는 다음과 같습니다.
- Discre 변수와 Continuous 변수를 동시에 생성 가능하다고 합니다( medgan 논문은 안됩니다)
- 대부분의 discrete data를 생성하는 GAN 논문에서는 RL 방법이나 Round로 처리하는데, 해당 논문은 softmax를 이용하여서 처리합니다.
- 요즘 머리에서 self attention gan처럼 attention을 tabular data에도 접목시킬 수 있지 않을까?라고 고민을 자주 하고 있는데 해당 논문에선 self attention을 사용하지만 않지만 attention 방법으로 적용했다고 합니다.
- 일반적으로 fully connected로 Generator를 생성하는 것에 대해서 CNN,RNN을 어떻게 접목시킬 수 있을까 고민을 했는데, 해당 논문에선 Generator를 LSTM을 이용해서 생성을 합니다.
- 어떻게 평가할지에 대한 metric 관련 이야기도 있습니다.
- 그리고 코드가 공개되어있습니다(ㅎㅎㅎㅎ)
Introduction
-
여기서 이 저자가 쓴 이유는 Privacy가 들어간 데이터를 직접적으로 쓰지 않고 synthetic data를 사용해 그 데이터를 다른 곳에서도 사용할 수 있기 위해 사용한다고 하는 것 같습니다
- 저도 그런 의미에서 GAN을 Table Data에 사용하면 굳이 그 데이터가 있는 회사에 가서 보안 검사 없이 자유롭게 밖에서도 사용해 분석을 원활하게 할 수 있을 것 같다고 생각합니다.
Related work
- missing value impute
- using vae https://arxiv.org/pdf/1705.02737.pdf
- using GAN https://arxiv.org/pdf/1806.02920.pdf
- [다음 리뷰 대상 ]RGAN , RCGAN real-values time-series data generate https://arxiv.org/abs/1706.02633
- 제가 관심있는 논문에 이 아키텍처가 많이 착안이 되는 것 같습니다.
- medGAN , corrGAN : Discrete variable 생성
- tableGAN http://www.vldb.org/pvldb/vol11/p1071-park.pdf
- 여기선 CNN 사용했다고 합니다!! (읽어봐야겠네요)
- 여기서는 cross entropy를 최소화 함으로써 예측 정확도를 최적화합니다.
- 해당 논문에서는 marginal distribution에 초점을 맞추고 각 칼럼 별로 KL divergence를 최소화하는 것이라고 합니다.
3. GANs for tabular data
실제 테이블에는 여러가지 data type이 가능합니다 numerical , categorical , time , text 등등 관련된 것을 다 넣을 수 있을 것입니다. 이렇기 때문에 데이터의 분포는 어떤 것은 multinomial이고 어떤 것은 꼬리가 길고 다양한 모양이 나오겠죠? 해당 논문에서는 크게 numerical과 discrete(multinomial)로 나눕니다

그리고 이것들은 다 독립이라고 가정을 합니다! 이 논문에선 sequential data(time)같은 것은 고려 안 한다고 합니다.
(여기서 저것을 고려 안하는데, LSTM을 사용한다는 게 참 신기하다고 생각했습니다)

이 논문에서 목표는 M이라는 Generative model을 만드는데 2가지 목적을 만족하는 것을 만들겠다고 합니다.
- 합성 데이터는 test 데이터에 나온 정확도와 유사하게 나오면 된다는 것입니다.
- Mutual Information : 임의의 두 변수 (i,j) 사이 상호 정보량은 T 든 Synth에서 나오든 유사하게 나온다는 겁니다.
Mutual Information 란?
제가 알기론 일반적인 변수간의 상관성을 측정해줄 수 있습니다. corr의 상위 호환 버전 정도? 두 변수 간의 공유하는 정보량이 얼마나 있는지? 얼마나 의존적인지를 측정해줄 수 있는 것입니다. (InfoGan에 나와서 먼가 disentangle 하게 학습시킬 때 사용할 수 있는 개념이라 먼가 해석하거나 원하는 것을 만들고 싶을 때 다른 논문에서 저 개념을 사용해서 만들지 않을까 싶습니다!)
3.1 Reversible Data Tranformation
음... 암튼 보기에는 결국 Neural Network가 잘 학습 할 수 있는 구조로 바꾸겠다는 말 같습니다.
numerical -> (-1,1) 그리고 낮은 집합의 크기를 가지는 multinomial은 softmax로 바꿔서 할 수 있다고 합니다.
Mode-specific normalization for numerical variables
- numerical
- 때대로 table에서 수치형은 multinomial 분포라고 합니다.
- 그래서 mode의 수(봉우리수)를 추정하기 위해 Gaussian KDE 사용했다고 합니다.
- 그냥 (-1 ,1 )을 사용하게 되면 학습이 잘 안될 수 있다고 합니다.
- 왜냐하면 -1, 1에 mode가 있으면 grdient가 saturate가 된다고 합니다.
- 실제로 분포를 보면 꼬리가 긴~~분포가 많이 나오긴 합니다.
- 그래서 이것을 해결하기 위해 GMM을 써서 cluster 한다고 합니다.
- 하나의 변수(C)에 m개의 공변량과 평균 mode를 가진 multivariate Gaussin이라고 가정하는 것 같습니다.
- 그래서 그것을 사용해서 u를 구하는데, u는 앞에 나온 m에 대해서 normalized 된 확률 분포라고 합니다.
- 그리고v는 c_j라는 값에다가 normalize를 해주고 포화되지 않게 하기 위해 -0.99,0.99로 clip 해주는 것 같습니다.
- clip은 생각해보니 좋은 아이디어인 것 같으니 나중에 사용해야겠다!
- c를 표현하기 위해 u와 v를 사용한다고 합니다.
- 만약 m=5를 기준으로 해서 만들었다고 했고, 실제 변수는 unimodal인 경우 m=1인 것 과 같습니다.
- 그러면 학습 때 m 1개를 제외하고 나머지는 아주 낮은 확률이 돼서 unimodal처럼 보이게 학습이 된다는 이야기를 합니다.

Smoothing for categorical variables
- GAN은 구조 자체가 backpropagation으로 학습을 하는 것이다 보니 Discrete 변수는 항상 문제가 됩니다.
- 그래서 어떤 사람은 강화 학습 방법(SeqGAN) , 아니면 Gumbel Softmax https://arxiv.org/pdf/1611.04051.pdf
- 이 사람들이 주장하는 것은 natural language보다 이 카테고리 사이즈는 더 작기 때문에 softmax를 쓴다는 겁니다!
- 그런데 여기다가 이 사람들은 Onehot을 하고 0이나 오면 좀 그런가 본지 noise를 좀 넣어주고 normalize를 해줍니다. ㄷㄷㄷ 어떻게 된 0을 만들곤 싶지 않은 것 같다는 생각이 듭니다.

이렇게 전 처리하게 됐을 때 (continous) + (category :onehot 된 상태)로 처리를 해줄 수 있습니다.

그다음에 다시 원래대로 바꿔주기 위해 다음과 같이 진행합니다. 원래 제가 할 때는 scale을 전부 -1 ,1로 바꿔줬는데,
여기서는 좀 더 그럴듯하게 합니다...

3.2 Model and data generation
위에 있는 모델을 보면 Generator (LSTM) Discriminator (MLP)로 구성합니다.
- Generator
그래서 아까 위에 나온 것처럼 v를 생성하고 그다음 cluster vector u 그리고categorical를 생성합니다.
여기서 z는 모두 똑같은 데이터를 나타낼 것 같습니다. 그리고 위에 보면 이전 f'(t-1) 이전에 따라서 f(t-1)은 embedding vector가 나오게 됩니다.
그다음에 attention-based context vector a(t) 도 나오게 됩니다.

여기서 드는 생각은 LSTM은 순차적인 구조에서 사용하는데 attention을 쓰니 우리는 전체 문맥을 고려해서 학습시키니 상관없다? 이런 느낌인 건지...
- Discriminator
- mlp 구조로 해서 다 concat을 하는 것을 볼 수 있습니다!
- 여기서 신기한 것은 diversity입니다.
- 논문에서는 the mini-batch discrimination vector라고 합니다.
- 여기서는 이것을 통해서 minibatch로 학습시키면서 다른 나머지 샘플들과의 총거리를 계산해서 다양성을 보는 것 같습니다!
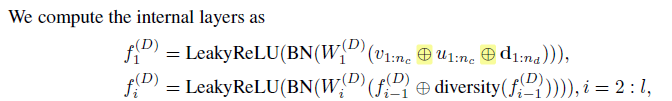
이런 식으로 구조를 짜면 미분 가능해지니 Adam을 사용했다고 합니다.
- 효과적으로 하기 위해 discrete variable 만 KL divergence를 하고 또 추가로 cluster에 대해서도 KL divergence를 하면 더 안정되게 잘되었다고 하는 것 같습니다.
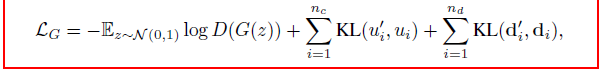

4. Evaluation Step
- 해당 논문에서는 변수들 간의 correlation을 얼마나 잘 잡아내는지에 초점을 맞췄다고 합니다.
- Machine learning efficacy
- 잘 학습시킨 다음에 둘 다 합친 데이터로 모델링을 하고 그 모델링 된 데이터를 Test로 평가해보겠다고 합니다.
- Does it preserve correlation?:
- pairwise mutual information을 계산해서 변수들 간에 correlation을 잡는 능력을 양적으로 평가한다고 합니다.
- numerical 변수는 20개로 쪼개서 한다고 합니다.
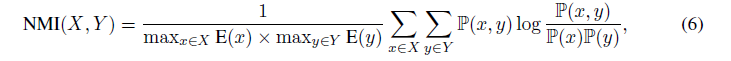
- Other data synthesizers
- 다른 방법으로 생성된 모델들과 비교해봤다고 합니다.


결과!
사용된 데이터
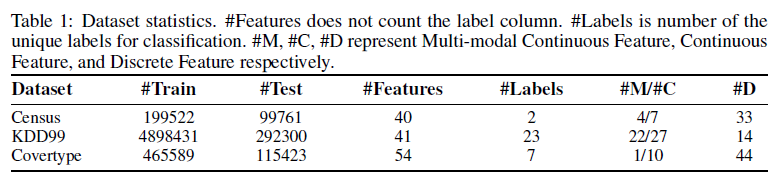
- 논문에서는 당연하게도 GAN이 잘됨을 보여서 Macro-F1이나 acc로 평가하는 것들은 패스합니다!
- real과 생성된 것에 대해서 NMI distance 니 낮으면 낮을수록 좋겠죠?
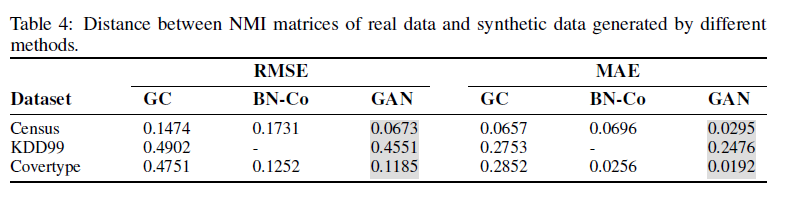

- Are correlations between variables preserved?
- Figure 3,4를 보면 다른 모델에 비해 TGAN이 더 나은 것을 확인할 수 있다고 합니다.
- How close is it to real data?
- Next, we attempt to answer the question: Is the data synthesizer simply remembering the data in the training set?".
- 단지 데이터를 기억하려고 노력하는 거냐라는 질문을 할 수 있습니다. 이것을 평가하기 위해 논문에서
- train data 10000개를 뽑고 test로부터 1000개 뽑습니다.
- 그리고 모델들로부터 1000개씩 뽑습니다. 그다음에
- 이 논문에서 사용하는 거리를 사용합니다.


그러면 다음과 같은 결과가 나오는데 이것을 통해서 거리를 재는 것을 통해서 생성된 것과 train은 다르다는 것을 볼 수 있습니다.
- 그래서 보시면 실제 각각 train 10000개에다가 test , a, b, tgan 이 있는데 이것을 넣어보니,
- 1,4번이 가장 유사하게 분포가 나오는 것을 확인할 수있고 가까움을 확인 할 수 있습니다!!
결론
- GAN 모형이 변수들 간에 correlation을 더 잘 학습한다고 합니다.
- 그리고 관계형 데이터 베이스는 이 모델에 적용하기 어렵다고 하고
- 다음에는 sequential data를 모델링하고 여러 개의 table이 있을 경우 어떻게 모델링할지에 대해 한다고 합니다.
- 개인적으로 빨리 나오기를 기대합니다ㅎㅎㅎㅎㅎ
이상으로 리뷰를 마치겠습니다.
실제로 제가 해보고 싶은 LSTM , Attention , 메트릭 방법 , scaling 방법과 같이 배울 것이 많았던 논문이고, 이제 코드를 열심히 봐야겠습니다