multiprocessing으로 pandas replace 하면 더 빠를까?
2019. 5. 8. 01:11ㆍ분석 Python/Pandas Tip
728x90
피드백을 좋아합니다!
머신러닝을 할 때 category 형식은 숫자 형식으로 바꿔줘야 한다.
이럴 때 가장 쉬운 방법은 cat.codes를 사용하면 빠르게 바꿀 수 있다.
category["nameDest"].cat.codes하지만 가끔 이렇게 바꾼 코드를 다시 바꿔서 사용해야 할 때가 있다.

저런 식으로 5개짜리 category랑 2722362 같이 엄청나게 많은 숫자가 나오는 것을 알 수 있다.
실제로 여러가지 multiprocessing으로도 테스트를 해보고 그냥 해본 것도 해보니
결론적으로 그냥 한 개씩 하는 것이 내가 했을 때는 빨랐다... 왜 그럴까?.... ㅠㅠㅠ
암튼 다음과 같이 결과물을 공유하려 한다.
버전 1 partition을 나눠서 했을 경우
column 별로 multiprocessing으로 할 경우 (가장 느림)
def value_to_coding(self , column ):
self.data[column] = self.data[column].map(self.dictionary.get(column))
return self.data[column]
def parallelize_dataframe(self):
col = self.data.columns.tolist()
pool = Pool(self.num_cores)
Output = pool.map(self.value_to_coding , col)
pool.close()
pool.join()
return Output
def run(self) :
print("Partion : {} , Cores : {}".format(self.num_partitions , self.num_cores ))
start = time.time()
df = self.parallelize_dataframe()
print("소요시간(초) : " , time.time() - start )
return pd.concat(df, axis = 1)
category = df[df.select_dtypes("category").columns]
Replace_f = multiprocessing_replace_value(num_partitions = 10 ,
num_cores = 10 ,
dictionary = value_to_code,
data = category ,
func = multiply_columns
)
change2 = Replace_f.run() 
버전 2
칼럼 별로 다 해서 함수로 만들었을 경우
def parallelize_dataframe_v2(self ) :
df_split = np.array_split(self.data , self.num_partitions)
pool = Pool(self.num_cores)
Output = pd.concat(pool.map(self.func , df_split))
pool.close()
pool.join()
return Output
## better
def run_v2(self) :
print("Partion : {} , Cores : {}".format(self.num_partitions , self.num_cores ))
start = time.time()
df = self.parallelize_dataframe_v2()
print("소요시간(초) : " , time.time() - start )
return df
def multiply_columns(data):
data['type'] = data['type'].map(value_to_code.get("type"))
data['nameDest'] = data['nameDest'].map(value_to_code.get("nameDest"))
return data
Replace_f = multiprocessing_replace_value(num_partitions = 10 ,
num_cores = 10 ,
dictionary = value_to_code,
data = category,
func = multiply_columns)
change2 = Replace_f.run_v2()
버전 3 단순하게 했을 경우
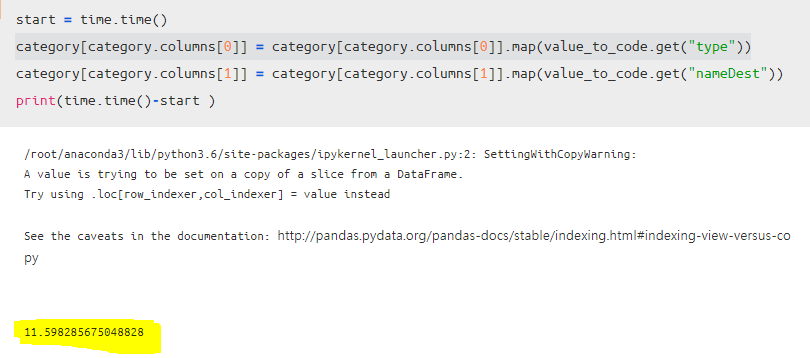
결론은 단순하게 한 것이 가장 빨랐다...
왜 이런 결과가 나오는 걸과 bottenleck 현상인가?...
multiprocessing으로 하면 항상 빨리 하려고 했는데 참 어려운 것 같다.
이상 실험 끝
혹시 이런 사항에 대해서 잘 아시는 분이 피드백을 주시면 정말 감사하겠습니다!
728x90
'분석 Python > Pandas Tip' 카테고리의 다른 글
| [ Python ] modin 으로 pandas 더 빠르게 사용하기 (0) | 2019.09.28 |
|---|---|
| [ Python ] Pandas Lambda, apply를 활용하여 복잡한 로직 적용하기 (2) | 2019.07.13 |
| [TIP / Pandas] Pandas를 보다 올바르게 사용하는 방법 (2) | 2019.05.23 |
| Multiprocessing pandas package 2개 소개 (0) | 2019.05.08 |
| Pandas에서 보는 옵션 설정하는 방법 (0) | 2019.05.01 |