2023. 11. 11. 12:04ㆍ관심있는 주제/LLM

우선 Milvus를 알아보기 전에 Vector Database에 대해서 간단히 알아보고자 한다.
Vector Database
"벡터 데이터베이스"는 머신 러닝 모델에서 나온 임베딩 기술의 능력을 활용하여 대규모의 비구조화 데이터 집합을 저장, 인덱싱, 검색하기 위한 관리형이면서 간단한 솔루션입니다.
이것은 대용량 및 복잡한 데이터 집합에서 정보를 효율적으로 구성하고 검색할 수 있게 해주며, 데이터 포인트를 고차원 공간의 벡터로 표현하여 유사성 검색 및 다양한 데이터 기반 작업을 수행하기가 더 쉬워집니다. 벡터 데이터베이스는 특히 자연어 처리, 이미지 인식, 추천 시스템 등과 같은 응용 분야에서 유용하며 데이터 패턴을 이해하고 비교하는 것이 중요한 경우에 활용됩니다.
여기서 또 이해를 하기 위해선 임베딩이란 것을 알아야 합니다.
Vector Embedding 이란?
벡터 임베딩(Vector Embedding)"은 텍스트, 이미지, 오디오 또는 다른 유형의 데이터를 컴퓨터가 이해하고 처리하기 쉬운 형태로 변환하는 기술입니다. 이것은 데이터를 고차원 벡터로 표현하는 것을 의미하며, 각 차원은 데이터의 다양한 특징이나 속성을 나타냅니다.
예를 들어, 자연어 처리 분야에서 텍스트 데이터를 벡터 임베딩으로 변환하면 각 단어 또는 문장은 고차원 벡터로 표현됩니다. 이 벡터에는 단어의 의미, 문법적 특성, 상호 관계 등이 포함될 수 있습니다. 이렇게 벡터 임베딩된 데이터는 기계 학습 및 딥 러닝 모델에서 사용되어 텍스트 분류, 번역, 감정 분석, 추천 시스템 및 다양한 자연어 처리 작업에 활용됩니다.
벡터 임베딩은 데이터의 의미와 구조를 보존하고 다른 데이터 포인트 간의 유사성을 측정하기 위한 강력한 도구로 사용됩니다. 이러한 임베딩은 데이터를 고차원 공간에서 처리하고 분석하는 데 도움이 되며, 다양한 AI 및 머신 러닝 응용 프로그램에서 핵심 구성 요소 중 하나입니다.
흐름도
1. 먼저, 임베딩 모델을 사용하여 색인하려는 콘텐츠에 대한 벡터 임베딩을 생성합니다.
2. 벡터 임베딩은 원본 콘텐츠의 어떤 참조와 함께 벡터 데이터베이스에 삽입됩니다. 이 참조는 해당 임베딩이 생성된 원본 콘텐츠를 가리킵니다.
3. 응용 프로그램이 쿼리를 실행하면, 동일한 임베딩 모델을 사용하여 쿼리에 대한 임베딩을 생성하고, 이러한 임베딩을 사용하여 유사한 벡터 임베딩을 추출합니다. 앞서 언급한 대로 이러한 유사한 임베딩은 원래 생성된 원본 콘텐츠와 관련이 있습니다.
더 깊은 내용들이 많아 보이지만, 이 정도로 소개하고자 하고 추후에 좀 더 알아보고자 합니다.
흐름도 예시
주요 속성
CRUD 외에도 아래와 같은 주요 속성들이 있습니다.
- Support for high-efficiency vector operators
- 고차원 벡터 연산을 지원해야 합니다. 이는 의미 유사성 매칭 및 의미 산술과 같은 다양한 연산 유형을 지원하는 것을 의미하며, 벡터 간 유사성 계산에 대한 다양한 유사성 메트릭을 지원해야 합니다. 일반적인 메트릭으로는 유클리드 거리, 코사인 거리 및 내적 거리 등이 있습니다.
- Support for vector indexing
- 고차원 벡터 색인은 전통적인 데이터베이스의 B-트리나 LSM-트리 기반 색인과 비교하여 훨씬 많은 컴퓨팅 리소스를 소비합니다. 이러한 이유로 클러스터링 및 그래프 색인 알고리즘을 사용하고 하드웨어 벡터 계산 가속 능력을 최대한 활용할 수 있도록 행렬 및 벡터 연산에 우선순위를 부여하는 것이 권장됩니다.
- Consistent user experience across different deployment environments
- 벡터 데이터베이스는 일반적으로 다양한 환경에서 개발 및 배포됩니다. 데이터 과학자와 알고리즘 엔지니어들은 초기 단계에서 주로 노트북과 워크스테이션에서 작업하며 검증 효율성과 반복 속도에 더 중점을 둡니다. 검증이 완료되면 전체 규모의 데이터베이스를 개인 클러스터 또는 클라우드에 배포할 수 있습니다. 따라서 우수한 벡터 데이터베이스 시스템은 다양한 배포 환경에서 일관된 성능과 사용자 경험을 제공해야 합니다.
- Support for hybrid search
- 벡터 데이터베이스가 보급되면서 새로운 응용 프로그램들이 등장하고 있습니다. 이 중에서 가장 빈번하게 언급되는 요구 사항 중 하나는 벡터 및 다른 유형의 데이터에 대한 혼합 검색입니다. 예를 들어 스칼라 필터링 후 근사 최근 이웃 검색(ANNS), 풀 텍스트 검색 및 벡터 검색에서의 다중 채널 검색, 시공간 데이터와 벡터 데이터의 혼합 검색 등이 있습니다. 이러한 도전 과제들은 벡터 검색 엔진을 효과적으로 KV(Key-Value) 및 텍스트 및 기타 검색 엔진과 통합하기 위한 탄력적인 확장성 및 쿼리 최적화를 요구합니다.
- Cloud-native architecture
- 벡터 데이터의 급증하는 양을 다루기 위해 클라우드 환경에서의 확장성과 성능을 제공합니다.
Milvus (2.0)
아키텍처
Milvus 2.0는 물리적 테이블을 유지하지 않으며 대신 로그 지속성과 로그 스냅샷을 통해 데이터 신뢰성을 보장합니다.
로그 브로커(시스템의 핵심)은 로그를 저장하고 로그 게시-구독 (pub-sub) 메커니즘을 통해 구성 요소와 서비스를 분리합니다.
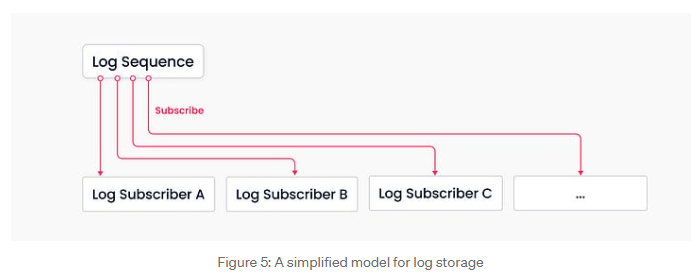
Figure 5에서 볼 수 있듯이, 로그 브로커는 "로그 시퀀스"와 "로그 구독자"로 구성됩니다.
로그 시퀀스는 컬렉션의 상태를 변경하는 모든 작업을 기록하며 (관계형 데이터베이스의 테이블과 동등함), 로그 구독자는 로그 시퀀스를 구독하여 로컬 데이터를 업데이트하고 읽기 전용 복사본 형태의 서비스를 제공합니다.
이 pub-sub 메커니즘은 변경 데이터 캡처(CDC) 및 글로벌 분산 배포에 대한 시스템 확장성을 제공합니다.
Indexes supported in Milvus
추후에 더 자세히 살펴보고자 한다....
| Supported index | Classification | Scenario |
| FLAT | N/A | Relatively small dataset |
| Requires a 100% recall rate | ||
| IVF_FLAT | Quantization-based index | High-speed query |
| Requires a recall rate as high as possible | ||
| GPU_IVF_FLAT | Quantization-based index | High-speed query |
| Requires a recall rate as high as possible | ||
| IVF_SQ8 | Quantization-based index | High-speed query |
| Limited memory resources | ||
| Accepts minor compromise in recall rate | ||
| IVF_PQ | Quantization-based index | Very high-speed query |
| Limited memory resources | ||
| Accepts substantial compromise in recall rate | ||
| GPU_IVF_PQ | Quantization-based index | Very high-speed query |
| Limited memory resources | ||
| Accepts substantial compromise in recall rate | ||
| HNSW | Graph-based index | Very high-speed query |
| Requires a recall rate as high as possible | ||
| Large memory resources | ||
| SCANN | Quantization-based index | Very high-speed query |
| Requires a recall rate as high as possible | ||
| Large memory resources |
Similarity Metrics
- Floating point embeddings
Euclidean distance (L2)
Inner product (IP)
Cosine similarity (COSINE)
- Binary embeddings
Jaccard
Hamming
사용 예시 (추천 Milvus 만들기)
milvus 연결하기 및 스키마 구성하기
from pymilvus import *
milvus_uri="XXXXXXX"
token="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
connections.connect("default",
uri=milvus_uri,
token=token)
print("Connected!")
OLLECTION_NAME = 'film_vectors'
PARTITION_NAME = 'Movie'
# Here's our record schema
"""
"title": Film title,
"overview": description,
"release_date": film release date,
"genres": film generes,
"embedding": embedding
"""
id = FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=500, is_primary=True)
field = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=384)
schema = CollectionSchema(fields=[id, field], description="movie recommender: film vectors", enable_dynamic_field=True)
if utility.has_collection(COLLECTION_NAME): # drop the same collection created before
collection = Collection(COLLECTION_NAME)
collection.drop()
collection = Collection(name=COLLECTION_NAME, schema=schema)
print("Collection created.")
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
print("Collection indexed!")
SentensorTransformer로 인코딩하는 함수 짜기
from sentence_transformers import SentenceTransformer
import ast
def build_genres(data):
genres = data['genres']
genre_list = ""
entries= ast.literal_eval(genres)
genres = ""
for entry in entries:
genre_list = genre_list + entry["name"] + ", "
genres += genre_list
genres = "".join(genres.rsplit(",", 1))
return genres
transformer = SentenceTransformer('all-MiniLM-L6-v2')
def embed_movie(data):
embed = "{} Released on {}. Genres are {}.".format(data["overview"], data["release_date"], build_genres(data))
embeddings = transformer.encode(embed)
return embeddings
데이터 넣기
# Loop counter for batching and showing progress
j = 0
batch = []
for movie_dict in movies_dict:
try:
movie_dict["embedding"] = embed_movie(movie_dict)
batch.append(movie_dict)
j += 1
if j % 5 == 0:
print("Embedded {} records".format(j))
collection.insert(batch)
print("Batch insert completed")
batch=[]
except Exception as e:
print("Error inserting record {}".format(e))
pprint(batch)
break
collection.insert(movie_dict)
print("Final batch completed")
print("Finished with {} embeddings".format(j))
검색해보기
collection.load() # load collection memory before search
# Set search parameters
topK = 5
SEARCH_PARAM = {
"metric_type":"L2",
"params":{"nprobe": 20},
}
def embed_search(search_string):
search_embeddings = transformer.encode(search_string)
return search_embeddings
def search_for_movies(search_string):
user_vector = embed_search(search_string)
return collection.search([user_vector],"embedding",param=SEARCH_PARAM, limit=topK, expr=None, output_fields=['title', 'overview'])
from pprint import pprint
search_string = "A comedy from the 1990s set in a hospital. The main characters are in their 20s and are trying to stop a vampire."
results = search_for_movies(search_string)
for hits in iter(results):
for hit in hits:
print(hit.entity.get('title'))
print(hit.entity.get('overview'))
print("-------------------------------")
참고
https://milvus.io/docs/index.md#floating
In-memory Index
Index mechanism in Milvus v2.3.x.
milvus.io
https://www.pinecone.io/learn/vector-database/
What is a Vector Database & How Does it Work? Use Cases + Examples | Pinecone
Discover Vector Databases: How They Work, Examples, Use Cases, Pros & Cons, Selection and Implementation. They have combined capabilities of traditional databases and standalone vector indexes while specializing for vector embeddings.
www.pinecone.io
https://milvus.io/docs/metric.md#floating
Similarity Metrics
Milvus supports a variety of similarity metrics, including Euclidean distance, inner product, Jaccard, etc v2.3.x.
milvus.io
'관심있는 주제 > LLM' 카테고리의 다른 글
| LLM) Training 방법중 ORPO(Monolithic Preference Optimization without Reference Model) 알아보기 (0) | 2024.04.14 |
|---|---|
| LLM) Mixed-Precision 개념 및 학습 방법 알아보기 (0) | 2024.04.13 |
| LLM) PEFT 학습 방법론 알아보기 (1) | 2024.02.25 |
| LLM) BloombergGPT 논문 읽기 (1) | 2023.11.02 |
| LLM) Large Language Model 기본 개념 알아보기 (2) | 2023.10.28 |