2022. 7. 9. 13:18ㆍ분석 Python/Data Preprocessing

이산화(Discretization)란
이산화에서는 전체 변수 값 범위에 걸쳐 있는 연속 간격 모음을 생성하여 연속 변수를 이산 기능으로 변환합니다. 이러한 불연속 값은 범주형 데이터로 처리됩니다.
이산화의 첼린지는 연속된 값이 정렬될 간격을 정의하는 임계값 또는 한계를 식별하는 것이다.
이를 위해 우리가 사용할 수 있는 다양한 이산화 방법이 있는데, 각각 장단점이 있다.
필요한 이유
의사 결정 트리(decision treeo) 및 Naive Bayes와 같은 여러 회귀 및 분류 모델은 이산 값에서 더 나은 성능을 보입니다.
아래 그림처럼 절단점을 찾기 위해서 여러번의 시행착오를 찾다가 학습시간이 ㄱ길어진다.
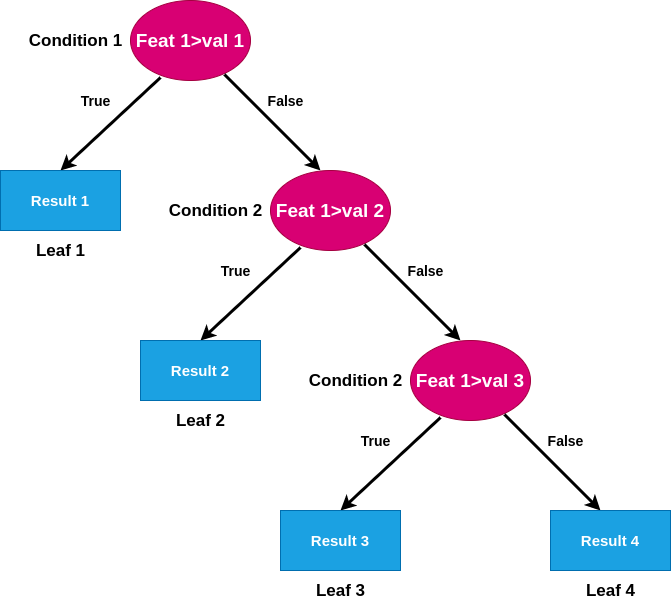
이산화(discretization)에는 추가 이점이 있습니다.
- 사람들은 이산 값을 더 쉽게 이해할 수 있습니다.
- 동일한 빈도의 bin에서 관측치를 정렬하면 치우친 값이 범위 전체에 더 고르게 분산됩니다.
- 이산화는 분포의 나머지 값과 함께 이상값을 더 낮거나 높은 간격에 배치하여 이상값의 영향을 최소화할 수도 있습니다.
- 전반적으로 연속 특징을 이산화하면 데이터가 더 단순해지고 학습 프로세스가 빨라지며 더 정확한 결과를 얻을 수 있습니다.
이산화는 그럼 항상 해야하는 가?
이산화는 예를 들어 서로 다른 클래스 또는 대상 값과 강하게 연결된 값을 동일한 빈으로 결합하여 정보 손실을 초래할 수 있습니다.(정보 손실)
따라서 이산화 알고리즘의 목표는 정보를 크게 잃지 않고 가능한 한 최소 간격을 결정하는 것입니다.
그런 다음 알고리즘의 작업은 해당 간격에 대한 cut 포인트를 결정하는 것입니다.
방법론
가장 일반적인 이산화 알고리듬은 equal-width 및 equal-frequency discretization입니다.
이들은 타겟를 고려하지 않고 간격 한계를 찾기 때문에 비지도 방식의 이산화 기법입니다.
간격 한계(interval limit)를 찾기 위해 k-평균을 사용하는 것은 또 다른 비지도 이산화 기법이다.
이러한 모든 방법에서 사용자는 연속 데이터를 정렬할 bin의 수를 미리 정의해야 합니다.
반면, 의사 결정 트리 기반 이산화 기법은 cut 포인트와 이상적인 분할 수를 자동으로 결정할 수 있다. 이 방법은 대상을 지침으로 사용하여 간격 한계를 찾기 때문에 지도방식의 이산화 방법입니다.
Equal-Frequency
등폭 이산화는 연속 값의 범위를 k개의 동일한 크기의 간격으로 나누는 것으로 구성된다. 변수 값이 0과 100 사이에서 변하면 빈은 0-20, 20-40, 40-60, 80-100이 될 수 있습니다.
오픈 소스 라이브러리 Feature-engine을 사용하여 Python에서 Equal-Frequency 이산화를 수행할 수 있습니다.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from feature_engine.discretisation import EqualWidthDiscretiser
X, y = fetch_california_housing(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
variables = ['MedInc', 'HouseAge', 'AveRooms']
disc = EqualWidthDiscretiser(bins=8, variables=variables, return_boundaries=True)
disc.fit(X_train)
train_t = disc.transform(X_train)
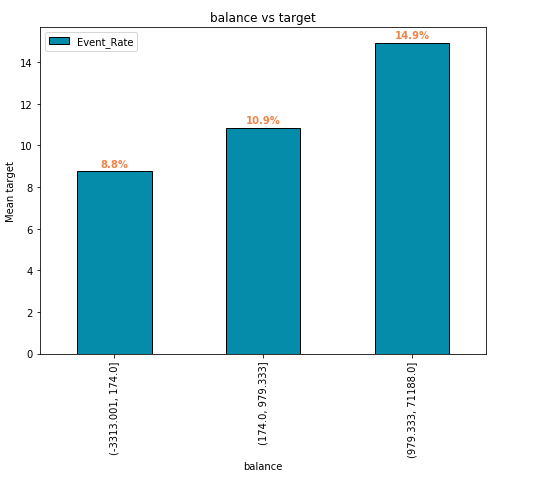
test_t = disc.transform(X_test)Equal-Frequency는 변수 분포를 크게 바꾸지 않는다. 이산화 후 변수가 치우쳐도 치우쳐 있습니다. 히스토그램을 사용하여 원래 변수 분포를 평가하고 막대 그림을 사용하여 이산화 후 변수를 평가할 수 있다.


Equal-Width
Equal-Width 이산화는 연속형 변수를 관측치 수가 동일한 구간으로 정렬합니다.
간격 너비는 분위수에 의해 결정된다. 등주파수 이산화(equal-frequency discarization)는 관측치를 서로 다른 빈에 균등하게 분산시키기 때문에 왜곡된 변수에 특히 유용합니다.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import KBinsDiscretizer
X, y = fetch_california_housing(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
disc = KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='quantile')
disc.fit(X_train[variables])
train_t = X_train.copy()
test_t = X_test.copy()
train_t[variables] = disc.transform(X_train[variables])
test_t[variables] = disc.transform(X_test[variables])

K-means
유사한 관측치를 그룹화하는 구간이나 빈을 만들려면 k-평균과 같은 군집화 알고리즘을 사용할 수 있습니다. k-평균 군집화를 사용하는 이산화에서 파티션은 k-평균 알고리즘에 의해 식별되는 군집이다.
k-평균을 사용한 이산화에는 k, 즉 군집 수 또는 빈 수라는 하나의 모수가 필요합니다. 우리는 scickit-learn으로 k-평균 이산화를 수행할 수 있다. 자세한 내용은 설명서를 참조하십시오.
Decision Trees
의사 결정 트리 방법은 학습 과정 동안 연속적인 속성을 이산화한다.
의사 결정 트리는 형상의 가능한 모든 값을 평가하고 엔트로피 또는 지니 불순물과 같은 성능 메트릭을 활용하여 클래스 분리를 최대화하는 컷 포인트를 선택한다.
그런 다음 특정 정지 기준에 도달할 때까지 첫 번째 데이터 분리의 각 노드와 후속 데이터 분할의 각 노드에 대해 프로세스를 반복합니다.
따라서 의사 결정 트리는 설계상 변수를 클래스 일관성이 좋은 간격으로 분할하는 절단점 집합을 찾을 수 있다.
의사 결정 트리를 사용한 이산화는 의사 결정 트리를 사용하여 각 연속 변수에 대한 최적의 파티션을 식별하는 것으로 구성된다.
Feature-engine은 의사 결정 트리로 이산화를 구현하는데, 여기서 연속 데이터는 유한 출력인 트리의 예측으로 대체된다. 각 트리는 과적합을 방지하기 위해 교차 검증으로 적합됩니다. 자세한 내용은 Feature-engine 설명서를 참조하십시오.
MonotonicBinning
Monotonic Binning은 scorecard 개발에서 넓게 사용되는 data preparation 기술입니다.
Monotonic Binning은 타깃과의 monotonic 관계를 가지는 bin을 생성함으로써, 수치형 변수를 범주형 변수로 전환
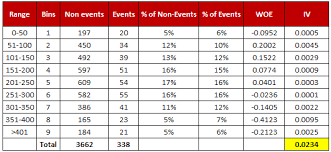
WOE(Weight of Evidence)
WOE는 증거가 가설을 지지하거나 약화시키는 정도를 나타내는 척도이다.
WUR은 바인딩 수준의 속성의 상대적 위험을 측정합니다. 값은 대상 변수의 값이 비사건인지 또는 사건인지에 따라 달라집니다. 속성의 WOW는 다음과 같이 정의됩니다.

참고
https://feature-engine.readthedocs.io/en/latest/api_doc/discretisation/index.html
'분석 Python > Data Preprocessing' 카테고리의 다른 글
| [Survey] Feature Engineering in AutoML 리뷰 (0) | 2020.11.07 |
|---|---|
| Target Encoding을 사용하여 범주형 변수 표현하기 (0) | 2020.09.01 |
| sklearn ColumnsTransformer 및 변수별로 전처리 적용하는 예시 (0) | 2020.05.02 |
| [변수 선택] Boruta 와 Lightgbm(rf)을 사용 (0) | 2020.04.24 |
| Data Preprocessing 잡생각 (0) | 2020.04.19 |