TABNET: ATTENTIVE INTERPRETABLE TABULAR LEARNING -1
| https://github.com/google-research/google-research/tree/master/tabnet | https://arxiv.org/abs/1908.07442# |
3. TABNET MODEL
3.1 PRINCIPLES
(Fig. 2) 전통적인 뉴럴 네트워크 building bolcks들을 사용하여 decision tree-like output manifold의 시행을 초기에 고려했다. 개별 형상 선택은 초평면 형태의 의사결정 경계를 구하는 핵심 아이디어로, 구성 계수가 의사결정 경계에서 각 형상의 비율을 결정하는 형상의 선형 조합에 대해 일반화할 수 있다. 저자는 tree-like function의 타입을 일반화할 수 있는 것을 목표로 하였다.

Figure 2. 전통적인 뉴럴 네트워크 블록들과 two-dimensional manifold를 사용하여 decision tree-like 분류의 설명
(x1와 x2는 인풋 차원 , 그리고 a와 d는 상수) 인풋들에게 multiplicatvie sparse mask를 배치함으로써, 관련된 특징들은 선택된다. 이 선택된 특징들은 선형적으로 변형되고 그 후에 bias를 추가한다.(boundaries를 표현하기 위해)
Relu함수는 영역 들을 제로화함으로써 영역 선택을 할 수 있다. 다중 영역들에 통합은 합 연산을 기반으로 한다.
C1, C2가 크면 클수록 decision boundary는 softmax 덕분에 더 sharper 해질 수 있다.
- Utilizing sparse instance-wise feature selection, learned based on the training dataset.
- Constructing a sequential multi-step architecture, where each decision step can contribute to a portion of the decision that is based on the selected features.
- Improving the model capacity by non-linear processing of the selected features.
- Ensembling via higher feature dimension and more decision steps.
3.2 OVERALL ARCHITECTURE
Fig 3은 TabNet의 아키텍처이다. Tabular data inputs은 수치형 변수와 범주형 변수들로 구성되어 있다.
저자는 raw numerical features를 사용했다. 그리고 학습된 embedding 된 category features의 mapping을 고려한다.
저자는 변수의 어떠한 통합적인 정규화도 고려하지 않았다. 그러나 단지 batch normalization을 적용했다.
저자는 각 decision step에서 같은 D 차원 변수들 f ∈ B×D을 통과한다. B(batch size)
TabNet은 N steps 결정 단계에서 순차적인 multi-step processing을 기반으로 한다.
(i) 단계는 (i-1)단계에서 처리된 정보를 입력하여 사용할 형상을 결정하고 전체 의사결정에 통합할 가공 형상 표현을 출력한다.
순차적 형태의 하향식 주의 아이디어는 고차원 입력에서 관련 정보의 작은 부분 집합을 검색하는 동안 시각적 질문 답변이나 강화 학습과 같은 시각적 및 언어 데이터를 처리하는 애플리케이션에서 영감을 얻는다.
전반적으로 성능은 대부분의 하이퍼파라미터에게 너무 민감하지 않으며, 중요한 하이퍼 파라미터의 선택에 대한 지침도 부록에 제시되어 있다.
Feature selection
저자는 두드러진 특징들의 soft selection을 위해서 학습 가능한 sparse mask를 배치한다. (M [i] ∈ B×D)
대부분 두드러진 특질의 sparse selection을 통하여, 학습 능력은 무관한 특징에 낭비되지 않는다. 그러므로 모델은 효율적인 파라미터가 된다. 이 마스킹은 multiplicative form이다. (M [i] · f)
저자는 a[i-1] 처리된 단계로부터 전 처리된 변수들을 사용한 마스크를 얻기 위한 대안적인 transformer를 사용한다.

Sparsemax normalization는 대부분의 실제 데이터 세트에 대한 희소 형상 선택 목표와 일치하는 유클리드 투영을 확률론적 단순성에 매핑함으로써 간극을 촉진한다.
(식 1)은 normalization 성질을 가진다. h_i는 학습할 수 있는 함수이다. Fig 3는 batch normalization을 따르는 fully-connected layer을 사용한다. P [i]는 prior scale term이다.

Figure (3) (a) TabNet 아키텍처 각 결정 단계
(1) feature transformer
(2) attentive transformer
(3) feature masking로 구성한다.
Split block은 차후의 단계의 attentive transformer 사용하기 위해 그리고 overall output의 구성을 사용하기 위해서 전 처리된 representation을 2개로 나눈다. 각 결정 단계에서 그 변수 선택 mask는 함수 성에 대해서 통찰력을 제공한다.
그리고 마스크들은 궁극적으로 통합적인 변수 주요 속성을 얻기 위해서 통합된다.(Agg를 사용)
(b) feature transformer block 예)
4-layer network는 보여준다. 그들 중에서 2는 각 결정 단계들을 통해서 공유된다. 그들의 2는 결정 단계에 의존한다.
(c) attentive transformer block 예)
단일 계층 매핑은 현재 의사결정 단계 이전에 각 형상이 얼마나 사용되었는지를 집계하는 이전 척도 정보로 변조된다.
이 계수들의 정규화는 SPARSEMAX를 사용하여 배치한다.

γ 는 relaxation parameter이다. γ = 1일 때, 특성은 하나의 의사결정 단계에서만 사용하도록 강제되며 γ가 증가함에 따라 복수의 의사결정 단계에서 형상을 사용할 수 있는 더 많은 유연성이 제공된다.
선택된 특질들의 sparsity를 컨트롤하기 위해서 저자는 entropy form 안에서 sparsity 정규화를 제안한다.
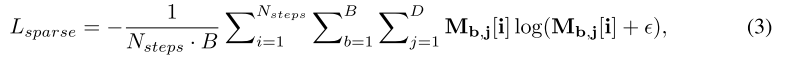
epsilon은 숫자의 안정성을 나타내는 작은 수이다. 저자는 전반적인 loss에 sparsity 정규화를 추가했다.
대부분의 입력 특성이 중복되는 일부 데이터 세트의 경우, 간격은 더 높은 정확도로 수렴하기 위해 유리한 유도 편향을 제공할 수 있다.
Feature processing
저자는 차후 단계를 위해 결과물과 정보들의 결정 단계를 분리하는 특징들을 얻기 위해서 feature transformer을 사용하여 선택된 변수들을 처리한다. (Fig 3)


In Fig. 3, we show the implementation of a block as concatenation of two shared layers and two decision step-dependent layers. Each fully connected layer is followed by batch normalization and gated linear unit (GLU) nonlinearity eventually connected to a normalized residual connection with normalization.
Normalization with root 0.5 helps to stabilize learning by ensuring that the variance throughout the network does not change dramatically, as discussed in (Gehring et al., 2017).
빠른 학습을 위해서 larget batch size를 사용한다.
larget batch size에서 성능을 향상하기 위해서 인풋 변수들에 적용된 것을 제외하고 모든 batch normalization 연산들 ghost batch normalization (Hoffer et al., 2017) form with a virtual batch size BV and momentum mB.로 시행된다.
저자는 이 인풋 변수들에서 low-variance averaging의 장점을 관측했다. 그러므로 ghost batch normalization을 피했다.
마지막 layer를 위해서 저자들은 d[i] 와 a [i] 처리된 represenation으로 분리한다.

Finally, we apply a linear mapping Wfinaldout, for the final decision. When discrete outputs are required, we additionally employ a softmax function during training (and argmax during inference).
드디어 실험...

이해를 정확히 한지는 모르겠지만,
일단 크게 핵심 아이디어는 Feature Transformer 와 attentive transformer을 사용한다.
Feature Transformer는 처음에는 인풋들에 대해서 일단 특정한 전처리 없이 들어가서 batch normailization을 사용해서 정규화를 시켜버리고 내부적으로 residual connection 같은 아이디어를 사용해서 decision step에서의 결정을 share 하고 앞의 결정이 뒷 단에도 영향을 더 주게 만들었다.
Attentive Transformer는 Prior Scale Information을 사용하여 얼마나 많이 각 변수들이 현재 결정에 사용되었는지를 알기 위해서 사용된다. 그 담에 Sparsemax를 사용하여 계수를 정규화한다.
이렇게 Attentive Transformer -> Feature Transformer를 1 step으로 쓰이고 이 과정을 반복한다.
(몇 번 더 보고 코드를 봐야 이해가 될 것 같다...ㅠ)
4 EXPERIMENTS
이 알고리즘은 회구 문제와 분류 문제 두개에서 다 적용할 수 있다. 다른 tree-based model과 비교하여 실험하였다.
일단 실험을 하기 위해서
- Categorical Inputs
- single dimensinal을 학습 가능한 embedding으로 맵핑을 했다.
- Numerical Inputs
- 전처리 없이 진행하였다.
TabNets들의 Hyperparameters은 appendix에 기재된 validation set이다.
TabNet 성능은 하이퍼 파라미터에 민감하지 않았다.
Adam을 사용했고 Glorot uniform init을 사용했다.
4.1 PERFORMANCE
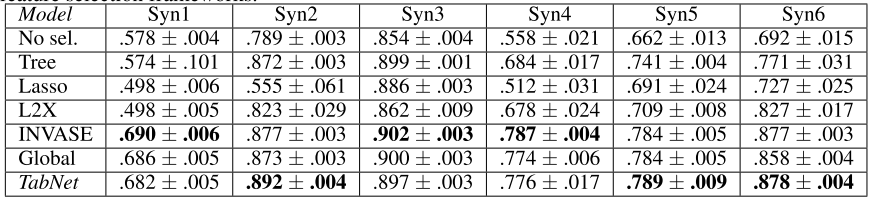
Comparison to methods that integrate explicit feature selection
2.
In GLU, first a linear mapping is applied to the intermediate representation and the dimensionality is doubled, and then second half of the output is used to determine nonlinear processing on the first half.
3.
In some problems, higher dimensional embedding mapping may slightly improve the performance, but interpretation of individual embedding dimensions may become challenging.
4.
Specially-designed feature engineering, e.g. logarithmic transformation of variables highly-skewed distributions, may further improve the results but we leave it out of the scope of this paper.


4.2 INTERPRETABILITY
TabNet 안에서 변수 선택 마스크들은 각 스탭에서 선택된 변수들에서 통찰력을 가질 수 있다.
이러한 능력은 각각의 차후 layer의 sparsity-controlled selection 없이 모든 특질들의 결합된 처리를 하는 전통적인 mlp에서는 가능하지 않았다.
변서 선택 마스크들에서, if Mb,j[i]Mb, j [i] = 0, then jth feature of the bth sample should have 0 contribution to the overall decision. If fi were a linear function, the coefficient Mb, j [i] would correspond to the feature importance of fb, j.
비록 각 결정 단계에서 비선형 처리를 배치할지라도, 그들의 결과물은 선형 방법을 후에 결합된다.
우리의 목표는 또한 각 단계의 분석을 넘어 종합 특성 중요도를 정량화하는 것이다.
다른 결정 단계들에서 마스크들의 결합은 결정에서 각 단계의 상대적인 중요성을 가중화하는 계수가 필요하다.

직관적으로 d_{b, c} [i] < 0 i 번째 결정 단계에서 모든 특질들은 전반적인 결정에서 0으로 기여한다.
그르기 그 값들이 커질 때, 전반적인 선형적인 결합에서 큰 역할이 된다.
긱 결정 단계에서 decision mask를 Scaling 하면서 저자는 변수 중요도 마스크를 통합하는 것을 제안했다.


Figure 4
변수 중요도 마스크들 M [i] (i번째 단계에서 선택된 변수를 나타낸다.) 그리고 global instance-wise feature selection을 보여주면서 변수 중요도 마스크 Magg를 통합하다.
밝은 색은 높은 값을 의미한다.

그림 4와 5는 sec에서 논의된 통합 데이터 세트에 대한 총 기능 중요 마스크를 보여준다.

그림 6 (a)는 다른 알고리즘과 TabNet의 변서 중요도를 보여준다. Odor가 가중 중요한 변수로 나왔다.
그림 6 (b)는 다른 데이터셋에 대해서 변수들의 ranking의 중요성을 보여준다.
그림 6 (c)는 T-SNE로 decision manifold를 시각화함으로써 output decision의 중요한 특징을 보여준다.
5 CONCLUSIONS
저자는 TabNet을 제안했다. tabular learning을 위한 참신한 딥러닝 아키텍처를 제시했다.
TabNet은 각 결정 단계에서 처리할 의미 있는 변수의 subset을 선택하기 위해 sequential attention mechanism을 활용했다.
이 선택된 특징들은 representation으로 처리되어서 다음 결정 단계에서 정보를 보내고 기여하고 있다.
Instance-wise feature selection은 model capacity로써 효율적인 학습을 가능하게 하다.
개인 생각
일단 이쪽을 공부하면서 이러한 아이디어를 보면서 많이 부족함을 느끼고, 아직도 배워야 할 게 많은 것을 느낀다. 보통 이쪽을 공부하면 논문에서 말한 거와 같이 정형 데이터보다는 비정형 데이터에 많이 개발되어 있는 상태이다. 그래서 개인적으로 그런 비정형 데이터에서 성능을 높인 CNN을 정형 데이터에 적용하기에는 이론이 맞지 않기 때문에 다른 대안으로 Attention을 어떻게 쓰고 싶었는데, 논문에서 attentive mechanism이라고 하는 방법으로 이전 단계를 반영하는 것이 나와서 기뻤고,
그리고 또 최근에 고민을 했던 게 수치형 변수에 대해서 skewed 되어 있을 때 애를 box-cox 변환이나 log transform을 해야 하나 고민을 했는데, 이 방법론을 사용하면 그러한 전처리가 필요 없어지는 tree-based model처럼 쓸 수 있어서 되게 인상적이었다. 그래서 더 나아가서 결측치도 MAR이나 NMAR 같은 경우여서 처리하기 어려운 경우에도 굳이 MCAR로 가정해서 처리하지 않고 다른 방식으로 할 수 있지 않을까 생각했다.
그리고 역시 여기서도 범주형 데이터에 대해서도 one hot을 쓰지 않고 embedding을 통해서 처리하는 게 내 생각이 틀리지 않음을 보여주는 것 같아 다행이라고 생각했다.
그리고 읽다가 또 하나 충격적인 것은 해석 가능성 방식을 넣었다는 것이다.
대부분의 정형 데이터로 딥러닝을 사용하는 사람들에게는 이 부분을 보통 surrogate model로 대체하는데, 이 부분을 해결한 게 아주 큰 장점인 것 같다.
암튼 최대한 빠르게 습득해서 나만의 코드로 바꿔야겠다!
'관심있는 주제 > 뉴럴넷 질문' 카테고리의 다른 글
| Graph Neural Networks 이란? (파파고 번역) (3) | 2020.02.16 |
|---|---|
| Ensemble Neural Network Architectures (0) | 2020.01.25 |
| TABNET: ATTENTIVE INTERPRETABLE TABULAR LEARNING -1 (0) | 2020.01.05 |
| What is Label Smoothing? - 리뷰 (Overconfidence) (0) | 2020.01.04 |
| Designing Your Neural Networks 리뷰 (0) | 2019.09.26 |