728x90
도움이 되셨다면, 광고 한번만 눌러주세요. 블로그 관리에 큰 힘이 됩니다 ^^
R에서는 모델링을 하겠다고 하면 주로 H2O로 하였고, Python에서는 딥러닝 프레임워크나 scikit learn을 주로 사용했는데, H2O는 모델 결과값도 아주 잘 정리해주는 좋은 패키지이기도 하고, 다양한 모델을 거의 비슷한 문법으로 사용할 수 있는 장점이 있는 것 같다. 그래서 여러개의 모델 중 XGBOOST로 실습해봤다.
아래 URL 참고!
# http://docs.h2o.ai/h2o/latest-stable/h2o-py/docs/_modules/h2o/estimators/xgboost.html
# https://github.com/h2oai/h2o-tutorials/blob/master/best-practices/categorical-predictors/gbm_drf.ipynb
# https://towardsdatascience.com/fine-tuning-xgboost-in-python-like-a-boss-b4543ed8b1e
import h2o
from h2o.estimators import H2OXGBoostEstimator
h2o.init(nthreads = 10 )
h2o.remove_all()
h2o.ls()
h2o_data = h2o.H2OFrame(data)
h2o_y = h2o.H2OFrame(target_y)
h2o_y = h2o_y.asfactor()
df = h2o_data.cbind(h2o_y)
train, valid = df.split_frame(seed = 1234,
destination_frames=["train.hex", "test.hex"])
xgb = H2OXGBoostEstimator(max_depth = 7 , ntrees = 300 ,
colsample_bytree = 0.9 , learn_rate= 0.001 ,
gamma = 0.0 , sample_rate = 1.0 ,
stopping_rounds = 50, stopping_tolerance = 0.001,
stopping_metric = "AUC",
)
xgb.train(x= h2o_data.col_names ,
y = h2o_y.col_names[0] ,
training_frame= train ,
validation_frame = valid ,
)
xgb.plot()
xgb.model_performance(train = True )
xgb.model_performance(valid = True )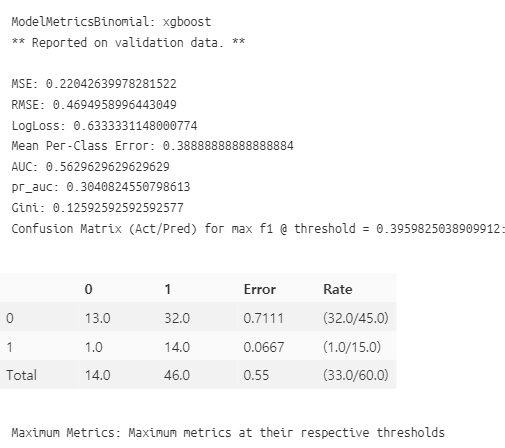


importances = xgb._model_json["output"]["variable_importances"].as_data_frame()
importances.head()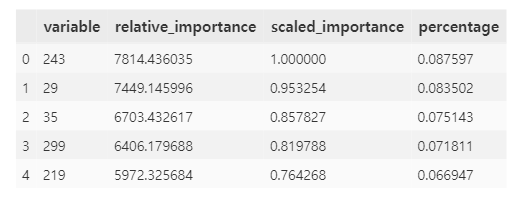
xgb.varimp_plot(num_of_features =20)
'분석 Python > 구현 및 자료' 카테고리의 다른 글
| [ Python ] smtplib을 활용한 메일 보내기 (이미지 , 텍스트 , gif) (0) | 2020.01.05 |
|---|---|
| [ Python ] 동적 변수 할당 및 불러들이기 (1) | 2019.12.15 |
| [ Python ] logging 결과물 폴더 생성 후 압축 파일로 저장하기 (0) | 2019.12.09 |
| [ Python ] smtplib를 이용해서 html 메일로 보내기 (0) | 2019.11.24 |
| [ Python ] Thread 간에 결과값 Queue로 전달 (0) | 2019.11.22 |