2019. 8. 2. 12:56ㆍ꿀팁 분석 환경 설정/Kafka
Kafka라는 것에 대해 공부하기 전 개념에 대해서 일단 보려고 하다가 좋은 자료가 있어서 번역해본다.
https://timber.io/blog/hello-world-in-kafka-using-python/
Hello world in Kafka using Python
We're going to teach you what Kafka is, apprehending the need for a tool like Kafka and then get started with it. We're believers that the best way to learn something is to do it, so get out your terminal and your favorite code editor.
timber.io
이 글에서는 총 4가지에 대해서 이야기합니다.
1. Kafka란 무엇인가?
2. 왜 우리는 streaming/ queueing/ messaging system이 필요할까?
3. 장점이 뭘까?
4. 어떻게 나의 현재 백앤드에 적합시킬까?
1. Kafka란 무엇이고 왜 이것을 써야할까?

위의 그림과 같은 웹 애플리케이션이 있다고 하자.
웹 애플리케이션에서 발생하는 clicks , requeusts , impressions , and search 같은 모든 이벤트를 저장하고,
각각이 별도의 애플리케이션이나 서비스에 의해 수행되는 계산, 분석, 보고서에 대한 테마를 저장해야 한다.
간단한 해결책은 데이터베이스에 데이터를 저장하고 데이터 베이스에서 서비스와 다른 애플리케이션을 연결하는 것이다.
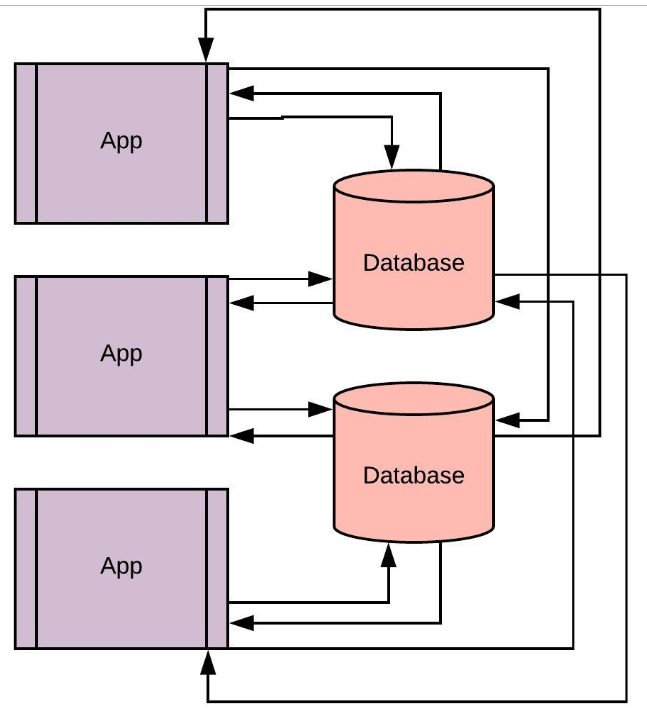
이러한 작업은 간단하지만, 끝나지 않고 다양한 문제가 생길 수 있습니다.
1. 클릭, 요청, 인상 및 검색과 같은 이벤트는 높은 빈도의 상호작용/요청 또는 당신의 웹 서버와 당신의 주 데이터베이스로의 데이터 흐름을 야기한다. 이것은 서버에 점점 더 많은 이벤트가 쏟아져 들어오면서 높은 대기 시간을 도입할 수 있다.
2. SQL이나 MongoDB와 같은 데이터베이스 시스템에 높은 빈도의 데이터를 저장하기로 선택한 경우, 모든 기록 데이터에 새로운 시스템이나 데이터베이스를 도입하고 재구성하는 것은 어려울 것이다. 새로운 기술을 도입함으로써 시스템의 기능을 확장할 수 있는 유연성을 잃게 되는 겁니다.
3. 더 깊은 인사이트를 얻기 위해 이러한 이벤트를 처리할 수 있는 데이터 처리 시스템을 갖추고 있다면 어떻게 하시겠습니까? 이러한 시스템은 빈번한 읽기를 처리할 수 없고 당신은 진정한 데이터 출처에 접근할 수 없기 때문에, 모든 데이터에 대해 다양한 데이터 처리 또는 기계 학습 알고리즘을 실험하는 것은 사실상 불가능하다.
4. 각각의 애플리케이션은 자신의 데이터 형태를 따르는데, 즉 애플리케이션들을 통해서 데이터를 교환할 때, 데이터의 변형을 할 수 있는 시스템이 있어야 한다는 의미다.
이 모든 문제들은 카프카 같은 스트리밍 플랫폼을 그림으로 가져옴으로써 더 잘 해결할 수 있다. 스트리밍 플랫폼은 다음을 수행할 수 있는 시스템이다.
1. 내결함성을 위해 영구적으로 체크섬 및 복제할 수 있는 방대한 양의 데이터를 저장할 수 있다.
2. Real time으로 데이터를 처리할 수 있다.
3. 애플리케이션에서 데이터 또는 데이터 스트림을 독립적으로 게시하고 애플리케이션/서비스가 데이터 스트림을 소비하는 것과 무관하게 게시할 수 있도록 허용하십시오.
전통적인 데이터베이스와 차이가 뭘까?!
Kafka는 영구 데이터를 저장할 수 있지만 데이터베이스가 아니다.
Kafka는 데이터의 연속적인 흐름을 Push 하거나 Pull 할 수 있을 뿐만 아니라, 실시간 애플리케이션을 도와주고 구축하는 처리를 다룬다.
이는 소극적인 데이터에 대해 CRUD 작업을 수행하거나 기존 데이터베이스에서 쿼리를 실행하는 것과는 다르다.
그러면 어떻게 해결하고 왜 이 시스템이 필요할까?
Kafa는 분산형 플랫폼이고 규격에 맞게 구축이 가능해서 매우 빈번한 읽기와 쓰기 그리고 큰 데이터 볼륨을 저장할 수 있다. 그 데이터에 대해선 신뢰성을 높게 가질 수 있다.
실패에 대한 복구도 하는 강한 메커니즘을 제공한다.
앞으로는 Kafka를 왜 사용하는 데에 있어서 핵심적인 관점을 말하고자 한다.
1. Simplify The Backend Architecture
아래의 그림은 복잡한 아키텍처를 Kafka의 도움으로 어떻게 단순화하고 간결하게 하는지 보여준다.

2. Universal Pipeline Of Data
위의 그림을 보듯이, Kafka는 다수의 애플리케이션과 서비스에 걸쳐 보편적인 데이터 파이프라인 역할을 할 수 있다.
이런 방식에는 2가지 장점이 있다고 한다.
1. 데이터 통합의 장점이 있다.
Kafka를 진정한 데이터의 원천을 만들기 위해서 한 곳에 상주하는 서로 다른 시스템의 모든 데이터를 가지고 있다.
어떤 애플리케이션도 나중에 다른 애플리케이션에 의해 끌 수 있는 이 플랫폼으로 데이터를 푸시할 수 있다.
2. Kafka는 애플리케이션들 사이에 데이터를 교환하는 것이 쉽다.
그러므로 한 장소에 모든 데이터를 넣을 수 있게 되고, 데이터 변형을 줄일 수 있는 플랫폼에 사용할 데이터의 포맷을 표준화할 수 있다.
3. Connects To Existing Systems
카프카는 표준 데이터 형식을 갖도록 허용하지만, 그렇다고 해서 애플리케이션이 데이터 변환을 필요로 하지 않는 것은 아니다.
이것은 아키텍처에서 데이터 변형의 전체적인 수를 감소하게 하는 것이다.
그러나 여전히 변형을 필요로 하는 경우가 있다.
카프카에 대해 모르는 레거시 시스템을 당신의 아키텍처에 연결하는 것을 고려해보라.
이러한 경우에는 Kafka는 보편적인 데이터 파이프라인을 지속하기 위해 존재하는 시스템과 연결하는 Kafka Connect라
는 프레임 워크를 제공한다.
4. Process Data In Real-Time
실시간 애플리케이션은 일반적으로 지속적인 데이터 흐름을 필요로 하며, 이는 즉시 또는 현재 시간 범위 내에서 처리될 수 있으며 대기 시간이 단축된다.
Kafka Streams는 무겁거나 비싼 기반 또는 구별된 stream processors의 도움 없이 애플리케이션을 구축, 패키징, 배포하는 게 가능하다.
이러한 특징들이 Kafka가 아키텍처에서 진정한 데이터의 원천이 되게 한다.
이런 것들을 통해서 새로운 서비스나 존재하고 있는 기반에 애플리케이션을 더할 수 있다. 그리고 특별한 노력 없이도 legacy systems(이미 구축된 옛것)으로부터 이동하거나 존재하는 데이터베이스를 다시 구축할 수 있다.
밑에는 파이썬에서 Kafka에 대한 패키지 간략 설명이 있다. (해보려다가 remote server에서 하다 보니 먼가 안된다..ㅠ)
- Command line client provided as default by Kafka
- kafka-python
- PyKafka
- confluent-kafka
마지막 주목!
카프카가 상당히 강력한 도구임에도 불구하고 몇 가지 단점이 있기 때문에 여기 팀버에서 AWS 키네시스 같은 관리 툴을 선택하게 된 겁니다.
우리가 속도를 목표로 할 때, 당신만의 서버를 프로비저닝하고 핵심을 파고드는 것은 말이 안 된다는 것을 알아냈다. 키네시스의 한계점에 부딪히면서 우리는 그 결정을 재고하기 시작했다.
(잘 모르겠다)
암튼 이번 자료에선 Kafka가 무엇이며, 어떤 것에서 기본 데이터 베이스와는 다른 장점이 있는지를 알았다.
이러한 자료로써, 유튜브 자료도 있어서 같이 공유하고자 한다.
https://www.youtube.com/watch?v=PtILI6v0ngY
'꿀팁 분석 환경 설정 > Kafka' 카테고리의 다른 글
| 카프카 데이터 플랫폼의 최강자 (1장 ~50pg) (0) | 2019.08.17 |
|---|---|
| Celery란? 좋은 자료 (1) | 2019.08.10 |
| python-Kafka Example (0) | 2019.08.06 |
| Kafka topic 만들고 써보고 제거해보기 (0) | 2019.08.04 |
| Kafka 자료 찾기 (0) | 2019.08.02 |