현재 카프카를 공부할 일이 있어서 원래는 그냥 인터넷에 있는 글들을 읽어서 파악하려고 했지만,
영어 바보인 관계로 두리뭉실하게 알고 있는 것 같아서 카프카, 데이터 플랫폼의 최강자 책을 읽어보려고한다.
책에서는 현재 자바/파이썬으로 코드가 조금 있는 것 같아서 더 적합한 것 같다.
다른 책들은 일단 도서관에 없었으므로... 일단 이 책도 좋은 것 같아서 시작한다!
더 읽다가 괜찮으면 사야겠다! ㅎㅎㅎ
http://www.yes24.com/Product/Goods/59789254
카프카, 데이터 플랫폼의 최강자
데이터 플랫폼의 핵심 컴포넌트로 각광받고 있는, 이벤트 기반 비동기 아키텍처를 위한 고가용성 실시간 분산 스트리밍 솔루션 카프카(Kafka)의 모든 것!국내 최대 모바일 플랫폼 회사인 카카오에서 `전사 공용 카프카` 서비스를 운영하고, 데이터 파이프라인과 빅데이터 플랫폼을 구축한 저자들의 풍부한 지식, 생생한 실전 경험, 노하우가 가득 담긴 책...
www.yes24.com
https://www.slideshare.net/OracleDeveloperkr/main-session-97867729
[Main Session] 카프카, 데이터 플랫폼의 최강자
오늘날 빅데이터 분석, 처리부터 모든 개발 플랫폼을 연결해주는 카프카의 등장 배경과 의미를 살펴보고, 실무에서 적용한 경험을 바탕으로 적절한 카프카 사용 사례를 정비해 보겠습니다. 또한 카프카의 내부 구동 방식에 대하여 소개하는 시간을 갖겠습니다. 마지막으로 실무에서 카프카를 운영하면…
www.slideshare.net
https://github.com/onlybooks/kafka/
onlybooks/kafka
Contribute to onlybooks/kafka development by creating an account on GitHub.
github.com
일단 빠르게 읽어봐야겠다!
카프카의 장점
1. 강력한 메시지 처리 성능(high throuhgput)
2. 빠른 수평 확장성 (scale-out)
3. 고장 감내 성(Fault-torelane)
이벤트 소싱과 같이 시간순으로 발생하는 이벤트를 카프카라는 데이터 버스에 저장해서, 활용하는 것이 많이 쓰인다고 함!
비동기 통신 방식 / 메시징 시스템 / 대용량 대규모 메시지 데이터 처리
기존 엔드 투 엔드 방식에서 문제점이 많음
1. 실시간 트랜잭션(OLTP) 처리와 비동기 처리가 동시에 이뤄지지만, 통한된 전송 영역이 없어서 복잡도 증가
(문제 발견 및 조치를 취하기 위해서는 여러 데이터 시스템을 확인해야 함.)
2. 데이터 파이프라인 관리의 어려움
부서별로 각각 다른 방식으로 파이프라인을 만들고 유지함.
이러한 복잡도와 파이프라인의 파편화로 인한 개발 지연 및 데이터 신뢰 하락으로 카프카 개발 시작
1. Producer와 Consumer의 분리 ( 보내는 놈 따로 쓰는 놈 따로)
2. 메시징 시스템과 같이 영구 메시지 데이터를 여러 Consumer에게 허용 (한 인풋을 여러 Consumer가 쓸 수 있게 하기)
3. 높은 처리량을 위한 메시지 최적화
4. 데이터 증가함에 따라 스케일 아웃이 가능한 시스템
그래서 여러 앱에서 카프카로 데이터를 보내고 / 카프카에서 여러 데이터를 꺼내서 각각 원하는 부서나 분석에 사용!
카프카의 동작 방식과 원리
카프카는 기본 적으로 메시징 서버로 동작
메시징 시스템이란?
메시지라고 불리는 데이터 단위를 보내는 측(publisher or producer)에서 카프카에 토픽이라는 각각의 메시지 저장소에 데이터를 저장하면 , 가져가는 측(subscriber , consumer)은 원하는 토픽에서 데이터를 가져가게 되어있음.
중앙에 메시징 시스템 서버를 두고 메시지를 보내고 받는 형태의 통신을 Pub/Sub모델!

Pub/Sub 장점
수신 불가능하다 해도 메시징 서버만 살아있으면 전달되는 메시지는 사라지지 않고 있습니다.
그리고 중간에 교환기의 룰에 의해서 데이터가 수신처의 큐에 정확하게 전달되므로 데이터 유실 염려도 없습니다.
Pub/Sub 단점
직접 통신을 하지 않기 때문에 정확히 전달되는지 확인하려면 코드가 좀 더 복잡해짐
중간에 메시징 시스템이 있어서 전달 속도가 빠르지 않음(?!)
주로 Pub/Sub 은 간단한 이벤트 처리(수 KB)
WHY?
- 메시징 시스템 내부의 교환기의 부하, 각 컨슈머들의 Queue 관리, Queue에 전달되고 가져가는 메시지의 적합성들을 관리하는 내부 프로세스가 아직 복잡했기 때문ㅇ!
즉) 기존 메시징 시스템은 메시지의 보관 , 교환, 전달 과정에서 신뢰성을 보장하는 것에 중점을 맞췄기 때문에 석도와 용량 중요하지 않았음!
파이썬에서 카프카를 이용하는 방법에 대해서 공부하는 겸 그냥 코드 몇 줄 남긴다!
카프카는 이런 단점을 극복하기 위해
1. 메시지 교환 전달의 신뢰성 관리를 Producer와 Consumer로 넘김
2. 부하가 많이 걸리는 교환기 기능 역시 Consumer가 만들 수 있게 해서 메시징 시스템 내에서의 작업량 줄임
절약한 작업량을 메시징 전달 성능에 집중시켜서 고성능 메시징 시스템을 만들어냄!

카프카도 기존 메시징 시스템과 동일한 비동기 시스템
Producer는 Consumer와 상관없이 새로운 메시지 카프카로 전송
Consumer는 Producer와 상관없이 메시지 사용
(역할 분담 철저)
수많은 메시지들이 저장되고 Topic이라는 식별자를 이용해 Topic 단위로 저장
비동기 기반으로 메시지 전달하는 것이 대표적인 것은 큐 솔류션!(RabbitMQ)
그러면 카프카와 메시지 큐 설루션의 차이는? 아래에 나옴
카프카 특징
1. Producer와 Consumer 분리
- 기존 링크드인 메트릭 수집 방식( 폴링 방식 ) - 늦어지는 현상 발생
- 보내는 놈 따로 / 나가는 놈 따로 필요성 느낌
- Pub/Sub으로 만들자라고 생각
- 만약 Pub/Sub은 싫어?!
- N대 N로 연결하는 경우 통신 장애로 연속적으로 다른 것에도 피해를 입힐 수 있음!
- Kafka 방식은 다른 것이 시스템이 망가져도 살 놈은 살아서 계속! 그리고 서버 추가 부담도 줄어듦 그냥 받는 것만 설정하면 되니까!
- 만약 Pub/Sub은 싫어?!
- Pub/Sub으로 만들자라고 생각
- 보내는 놈 따로 / 나가는 놈 따로 필요성 느낌
2. 멀티 Producer / 멀티 Consumer
- 카프카는 한 Topic에 멀티 Producer 나 멀티 Consumer들이 접근 가능한 구조임
- Producer는 하나의 메시지를 여러 Topic으로 보내줄 수 있다는 말
- Consumer 역시 여러 개에서 가져올 수 있음!
- (이 부분에 대해서 더 나오면 자세히 보고 싶음
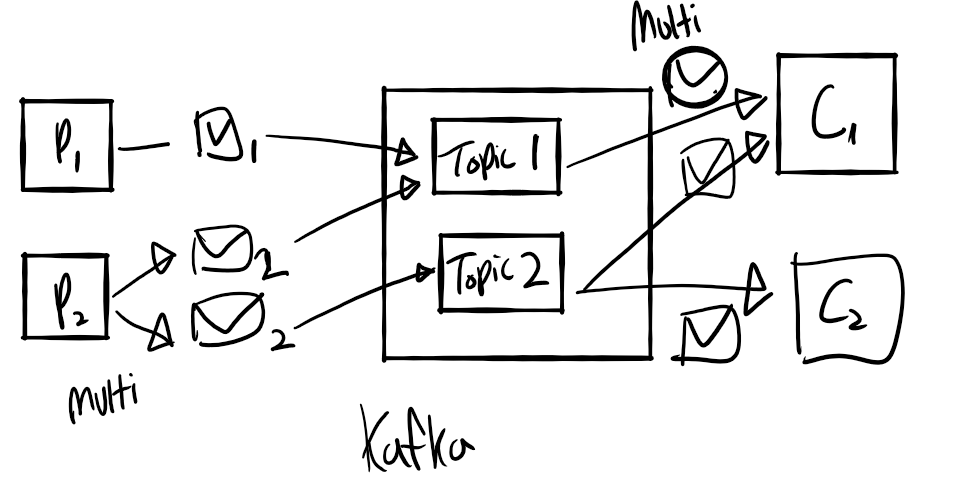
> P1 은 토픽 1로 메시지 1을 보내고 있음
> Multi Producer P2는 토픽 1과 토픽 2로 메시지 2를 각각 보냄
> C2 은 토픽 2에서 메시지 2를 가져오고 있음
> Multi Consumer C2는 토픽 1과 토픽 2에서 메시지 1 , 메시지 2를 각각 가져오고 있음
카프카는 중앙 집중형 구조
3. 디스크에 메시지 저장
기존의 메시징 시스템과 다른 점은 디스크에 메시지를 저장하고 유지!
일반적인 것은 큐에서 읽고 바로 삭제하는 구조/ 버그가 있어도 디스크에 저장되므로 손실 우려 x
4. 확장성
하나의 카프카 Cluster는 3개의 Broker로 시작해 수십대의 Broker로 확장 가능
서비스 중단 없이 온라인으로 가능함!
클러스터 확장이 굉장히 용이함. (6장)
5. 높은 성능
링크드인 사례) 1조 개 메시지 생성하고 하루에 1 테라 바이트 데이터 처리
용어 정리
카프카 : 아파치 애플리케이션 이름. 클러스터 구성이 가능/ (= 카프카 클러스터)
중개인(Broker) : 카프카 애플리케이션이 설치되어있는 서버 또는 노드 (으흠?)
토픽(Topic) : Producer와 Consumer들이 카프카로 보낸 자신들의 메시지를 구분하기 위한 네임
파티션(Partition) : 병렬 처리가 가능하도록 토픽을 나눌 수 있고, 많은 양 처리를 위해서는 파티션 늘려줄 필요가 있음
Producer : 메시지를 생산하여 Broker의 Topic 이름으로 보내는 서버 또는 애플리케이션
Consumer : Broker의 Topic 이름으로 저장된 메시지를 가져가는 서버 또는 애플리케이션
(~49pg)
역시 책으로 공부하니 기초부터 잘된다(책도 좋은 것 같다)
'개발 > Kafka' 카테고리의 다른 글
| [ Python ] kafka consume multiprocessing 해보기 (0) | 2019.08.17 |
|---|---|
| [Python] Kafka offset 확인 (0) | 2019.08.17 |
| Celery란? 좋은 자료 (1) | 2019.08.10 |
| python-Kafka Example (0) | 2019.08.06 |
| Kafka topic 만들고 써보고 제거해보기 (0) | 2019.08.04 |