딥러닝을 적용을 할 때 핵심 요소는 바로 신뢰다.
훈련에서 최적화까지, 심층 학습 모델의 라이프사이클은 서로 다른 당사자 간의 신뢰할 수 있는 데이터 교환과 연계된다.
그러한 동향이 확실히 실험실 환경에 효과적이지만 모델에서 다른 참가자 사이의 신뢰할 수 있는 관계를 조작하는 여러 종류의 보안 공격에 취약하다.
금융거래를 이용하여 특정 고객의 신용위험을 분류하는 신용평가모형의 예를 들어보자.
모델을 훈련하거나 최적화하기 위한 전통적인 메커니즘은 그러한 활동을 수행하는 기업들이 모든 종류의 사생활 위험에 대한 문을 여는 그러한 재무 데이터 세트에 완전히 접근할 것이라고 가정한다.
딥러닝이 발전함에 따라서 데이터셋과 모델의 라이프사이클 동안 프라이버시 제약을 강제하는 메커니즘의 필요성이 점점 더 중요해지고 있다.
이 기념비적인 도전에 대처하려는 기술들 중에서, PySyft는 깊은 학습 공동체 내에서 꾸준히 관심을 얻고 있는 최근의 틀이다.
딥러닝 애플리케이션에서 프라이버시의 중요성은 분산된 다당제 모델의 출현과 직결된다.
딥러닝 설루션에 대한 기존의 접근 방식은 대규모 분산 컴퓨팅 인프라를 사용하더라도 모델의 라이프사이클 전체를 제어하는 중앙 집중식 당사자에 의존한다.
웹사이트에 방문하는 고객들을 선호들을 관리하는 예측 모델을 만드는 것이 하나의 사례다.
그러나 데이터를 생산하고 모델을 실행하는 많은 디바이스에 의존하는 사물(IOT)의 모바일 또는 인터넷과 같은 시나리오에서는 중앙 집중식 심층 학습 토폴로지가 비현실적으로 입증되었다.
그러한 시나리오에서, 분산 당사자들은 종종 민감한 데이터셋을 생성할 뿐만 아니라 심층 학습 모델의 성능을 실행하고 평가한다.
그러한 역동성은 심층 학습 모델을 만들고, 훈련하고, 실행할 책임이 있는 다른 당사자 사이의 양방향 프라이버시 관계를 필요로 한다.
보다 분산된 아키텍처로 전환하는 것은 심층 학습 모델에서 강력한 프라이버시 메커니즘의 필요성을 뒷받침하는 주요 요소 중 하나이다.
그것은 PySyft가 다루기 위해 설정했던 도전이지만 기계학습과 분산 프로그래밍에 관한 여러 분야의 연구가 진화하지 않았다면 불가능했을 것이다.
딥러닝 모델에서의 프라이버시는 몇 년 동안 잘 알려진 문제였지만, 해결책을 제공할 수 있는 기술은 이제 특정 수준의 생존성을 달성하고 있다.
PySyft의 경우, 프레임워크는 지난 10년간 기계학습과 암호화에 있어 가장 매력적인 세 가지 기술을 활용한다.
- Secured Multi-Party Computations
- Federated Learning
- Differential Privacy
Secured Multi-Party Computations (sMPC)
(SMPC)은 다른 당사자가 입력에 대해 계산을 수행하면서 그러한 입력을 비공개로 유지할 수 있도록 하는 암호화 기법이다.
Federated Learning
(Federated Learning)은 사물인터넷(IOT) 시스템과 같은 고도로 분산된 토폴로지에서 작동하는 AI 시스템을 위한 새로운 학습 아키텍처다.
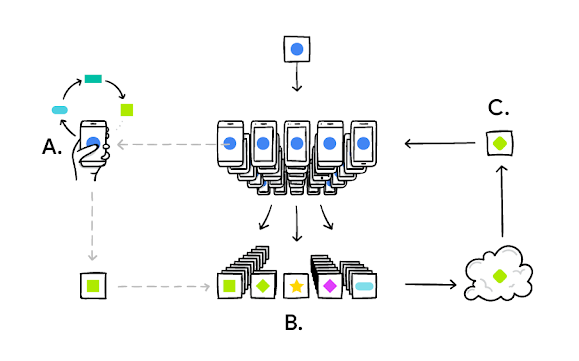
구글 연구소에 의해 처음 제안된 연합 학습은 참여 장치 연합에서 중앙 서버의 조정 하에 공유 글로벌 모델을 훈련하는 중앙 집중식 AI 훈련의 대안을 의미한다.
이 모델에서, 다른 장치는 대부분의 데이터를 장치에 보관하면서 모델의 훈련과 지식에 기여할 수 있다.
연합된 학습 모델에서, 당사자는 딥러닝 모델을 다운로드하고, 주어진 장치의 데이터로부터 학습함으로써 그것을 개선한 다음, 그 변화를 작은 집중 업데이트로 요약한다.
모델에 대한 이 업데이트만 암호화된 통신을 사용하여 클라우드에 전송되며,
여기서 공유 모델을 개선하기 위해 다른 사용자 업데이트와 함께 즉시 평균을 구한다.
모든 학습 데이터는 원래 장치에 남아 있으며, 개별 업데이트는 클라우드에 저장되지 않는다.
Differential Privacy
차등 프라이버시(differential privacy)는 통계 알고리즘이 더 큰 데이터 세트의 일부인 피험자의 프라이버시에 미칠 수 있는 영향을 제한하는 데 사용되는 기법이다.
알고리즘의 출력을 보는 관찰자가 특정 개인의 정보가 계산에 사용되었는지를 알 수 없는 경우 알고리즘은 서로 다르게 Private 하게 한다.
데이터베이스에 정보가 있을 수 있는 개인을 식별하는 맥락에서 종종 논의되는 차등 프라이버시.
식별 및 재식별 공격을 직접적으로 언급하지는 않지만, 차별화된 개인 알고리즘은 그러한 공격에 대한 저항성이 있다.
결국 결과물을 사용하는 자가 특정 개인의 정보를 사용하는 것을 인지 못하게 하는 방법

PySyft
PySyft is a framework that enables secured, private computations in deep learning models.
PySyft combines federated learning, secured multiple-party computations and differential privacy in a single programming model integrated into different deep learning frameworks such as PyTorch, Keras or Tensor Flow.
| https://arxiv.org/abs/1811.04017 | https://github.com/OpenMined/PySyft |
PySyft의 핵심 요소는 SyftTensor이다
SyftTensors는 데이터의 상태 또는 변환을 나타내기 위한 것으로, 서로 연결될 수 있다.
체인 구조에는 항상 PyTorch 텐서가 있으며, SyftTensor에 의해 구현된 변환 또는 상태는 하위 속성을 사용하여 아래쪽으로 접근하고 상위 속성을 사용하여 위로 접근한다

일단 무슨 말인지는 모르겠지만, 요즘 이런 사생활이 딥러닝에 많이 중요한 부분을 차지하고 있는 것 같아서 읽어보려 했는데, 이놈의 영어는 구려 가지고 파파고 번역을 써봤다.
나보다 한 100배는 나은 것 같다 ㅠ...
암튼 일단 Federated Learning과 Different Privacy에 대해서 어느 정도 감은 잠을 수 있어서 좋았던 것 같다
먼가 공부를 하려는데, 멍하게 있는 것 같아서 이러면 안 될 것 같아서 리뷰리뷰
https://towardsdatascience.com/pysyft-and-the-emergence-of-private-deep-learning-a2d169bb1d0b
PySyft and the Emergence of Private Deep Learning
Trust is a key factor in the implementation of deep learning applications. From training to optimization, the lifecycle of a deep learning…
towardsdatascience.com
https://www.youtube.com/watch?v=ei_e7nHS6SE
'관심있는 주제 > 분석 고려 사항' 카테고리의 다른 글
| Dataset Shift에 대한 이해 (2) - Prior probability Shift, Concept Drift (0) | 2019.12.15 |
|---|---|
| Dataset Shift에 대한 이해 (1) - Covariate Shift (0) | 2019.12.15 |
| 어떻게 언제 왜 Normalize Standardize Rescale 해주는지??! (3) | 2019.05.18 |
| Overfit? or dissimilar train and test? (medium 번역 및 생각) (2) | 2019.05.08 |
| Feature engineering ( 글 리뷰 및 내 생각 ) (0) | 2019.05.06 |