2022. 6. 10. 22:51ㆍ관심있는 주제/Paper
해당 논문을 보고자 하는 이유는 transformer를 사용하고, hierarchical 한 구조를 제시하고, 다양한 task에 적용 가능한 아키텍처인 것 같아 보려고 한다.
아래 DSBA에서 설명해주시는 영상을 보면 잘 설명해주기 때문에 참고하시면 될 것 같다.
이 논문은 컴퓨터 비전의 범용 백본 역할을 할 수 있는 Swin Transformer라는 새로운 비전 트랜스포머를 제시한다.
언어에서 비전으로 트랜스포머를 적응시키는 데 있어 어려움은 시각적 엔티티의 스케일의 큰 차이와 텍스트의 단어에 비해 이미지의 픽셀의 높은 해상도와 같은 두 도메인 간의 차이에서 발생한다.
- 물체의 크기(the scale of visual entities)
- 해상도(high resolution of pixels in images compared to words in text.)
이러한 차이를 해결하기 위해, 우리는 Shifted Window로 표현이 계산되는 계층적 트랜스포머(hierarchical Transformer)를 제안한다.
shifted windowing scheme은 cross-window 연결을 허용하면서 중복되지 않는 로컬 윈도로 self attention 계산을 제한하여 더 큰 효율성을 제공한다.
이 계층적 아키텍처는 다양한 규모로 모델링할 수 있는 유연성이 있으며 이미지 크기와 관련하여 선형 계산 복잡성을 갖는다.
Swin Transformer의 이러한 특성은 이미지 분류를 포함한 광범위한 비전 작업과 호환된다고 한다.
(image classification, object detection, semantic segmentation)

a) 제안된 Swin Transformer는 이미지 패치(회색으로 표시)를 더 깊은 레이어에 병합하여 계층적 특징 맵을 구축하고 입력 이미지 크기에 대한 선형 계산 복잡성을 갖는다. 각 로컬 창(빨간색으로 표시됨) 내에서만 자체 주의 연산으로 인해
따라서 그것은 범용 백본의 역할을 할 수 있다. 이미지 분류 및 고밀도 인식 작업에 모두 사용할 수 있습니다.
b) 대조적으로, 이전 비전 트랜스포머[20]는 단일 저해상도 피처 맵을 생성하고 전체적으로 자기 주의 계산으로 인해 이미지 크기를 입력하는 데 2차 계산 복잡성을 갖는다.
시퀀스 모델링 및 변환 작업을 위해 설계된 Transformer는 데이터의 장거리 종속성을 모델링하는 데 주의를 기울이는 것으로 유명하다.
우리는 언어 영역에서 높은 성능을 시각적 영역으로 전송하는 데 있어 중요한 문제가 두 가지 양식 간의 차이로 설명될 수 있다는 것을 관찰한다.
이러한 차이 중 하나는 규모와 관련이 있습니다.
language Transformer에서 처리의 기본 요소 역할을 하는 토큰이라는 단어와는 달리 시각적 요소는 크기가 상당히 다양할 수 있는데, 이는 객체 감지와 같은 작업에서 관심을 받는 문제이다.
기존의 Transformer 기반 모델에서 토큰은 모두 고정 스케일로, 비전 적용에 적합하지 않다.
또 다른 차이점은 텍스트 구간의 단어에 비해 이미지의 픽셀 해상도가 훨씬 높다는 것이다.
픽셀 수준에서 조밀한 예측을 요구하는 의미론적 분할과 같은 많은 비전 작업이 있으며, self-attention의 계산 복잡성이 이미지 크기에 2차이기 때문에 고해상도 이미지의 트랜스포머에서는 이것이 다루기 어려울 것이다.
이러한 문제를 해결하기 위해 swin Transformer라는 이름으로 제안한다고 한다.
계층적 피쳐 맵을 구성하고 이미지 크기에 대한 선형 계산 복잡성을 가진다.
Swin Transformer는 작은 크기의 패치(회색으로 요약)에서 시작하여 더 깊은 Transformer 계층에서 인접 패치를 점진적으로 병합하여 계층적 표현을 구성한다.
이러한 계층적 특징 맵을 통해 Swin Transformer 모델은 특징 피라미드 네트워크(FPN) 또는 U-Net과 같은 고밀도 예측을 위해 고급 기술을 편리하게 활용할 수 있다.
선형 계산 복잡성은 이미지를 분할하는 겹치지 않는 창(빨간색으로 표시된) 내에서 로컬로 self attention를 계산함으로써 달성된다.
각 window의 패치 수는 고정되어 있으므로 복잡도는 이미지 크기에 따라 선형으로 변합니다.
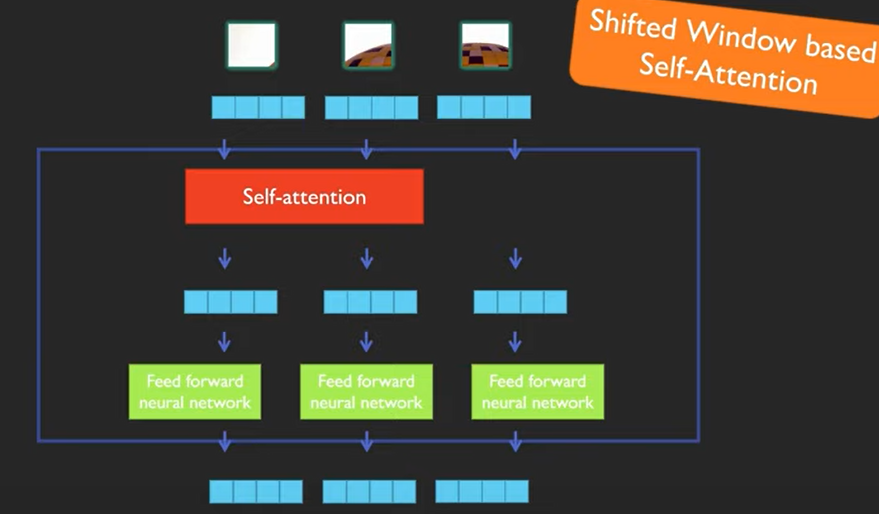
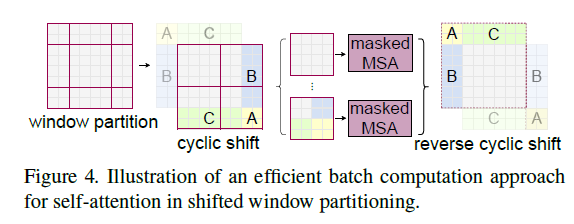
Swin Transformer의 핵심 설계 요소는 그림 2와 같이 연속적인 셀프 어텐션 레이어 간의 윈도 파티션 이동이라고 한다.
shifted 된 창은 이전 층의 창을 연결하므로 모델링 성능이 크게 향상됩니다
이 전략은 실제 대기 시간과 관련해서도 효율적이다.
창 내의 모든 query 패치는 하드웨어에서 메모리 액세스를 용이하게 하는 동일한 key set을 공유한다.
대조적으로, 이전의 슬라이딩 윈도 기반 self attention 접근 방식은 낮은 대기 시간으로 인해 어려움을 겪는다.
다른 query 픽셀에 대한 다른 key 집합으로 인해 일반 하드웨어에 적용되었습니다.
Shifted window 접근법은 슬라이딩 window 방법보다 지연 시간이 훨씬 낮지만 모델링 파워에서 유사하다.
전환된 창 접근 방식은 또한 All-MLP 아키텍처에도 유용합니다.
- Path Partition
- Linear Embedding
- Swin Transformer
- Path Merging
먼저 ViT와 같은 패치 분할 모듈에 의해 입력 RGB 이미지를 겹치지 않는 패치로 분할한다.
각 패치는 "토큰"으로 처리되며 해당 기능은 원시 픽셀 RGB 값의 연결로 설정됩니다.
패치를 4x4의 사이즈를 사용하면 채널 수까지 고려하면 4x4x3 = 48을 사용한다는 예시를 들었다.
수정된 self attention 계산이 있는 몇 가지 트랜스포머 블록(스윈 트랜스포머 블록)이 이러한 패치 토큰에 적용된다.
(H/4 x W/4) 만큼의 토큰 수를 가지게 된다.
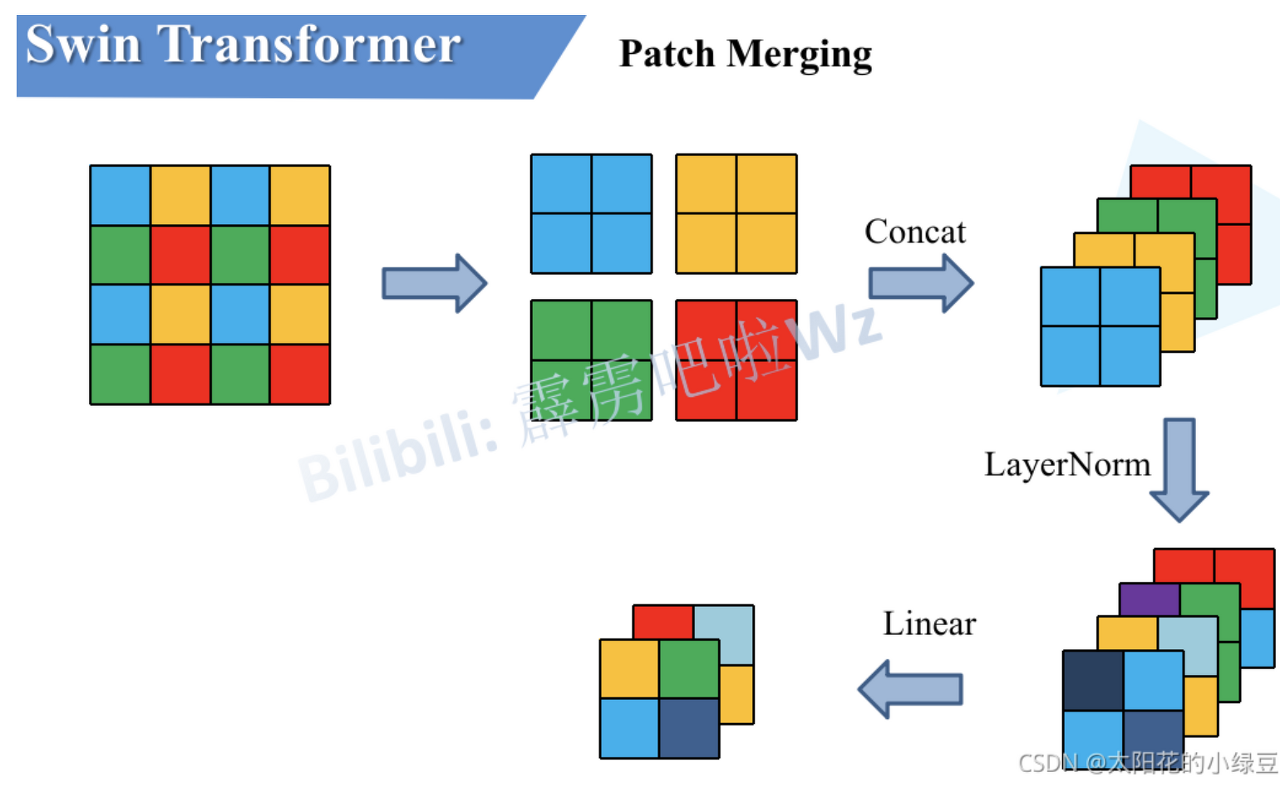
계층적 표현을 생성하기 위해 네트워크가 깊어질수록 패치 병합 계층에 의해 토큰 수가 감소한다.
만약 pixel 단위로 토큰을 만들게 되면 엄청나게 토큰을 만들게 되고, patch 단위로 하면 어느 정도 줄인 상태가 될 수 있다.


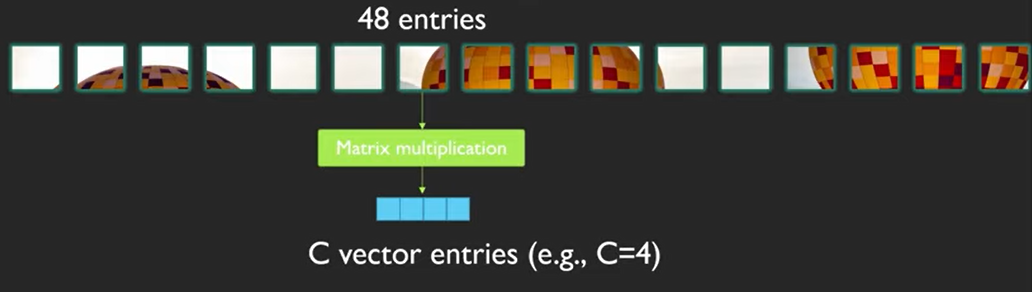
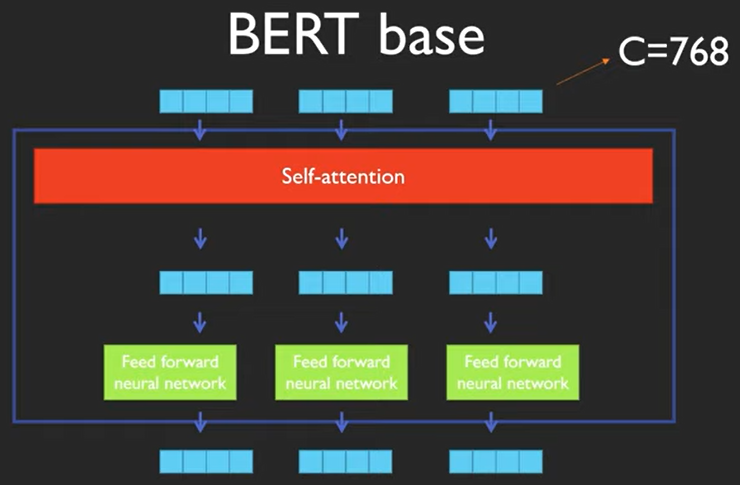
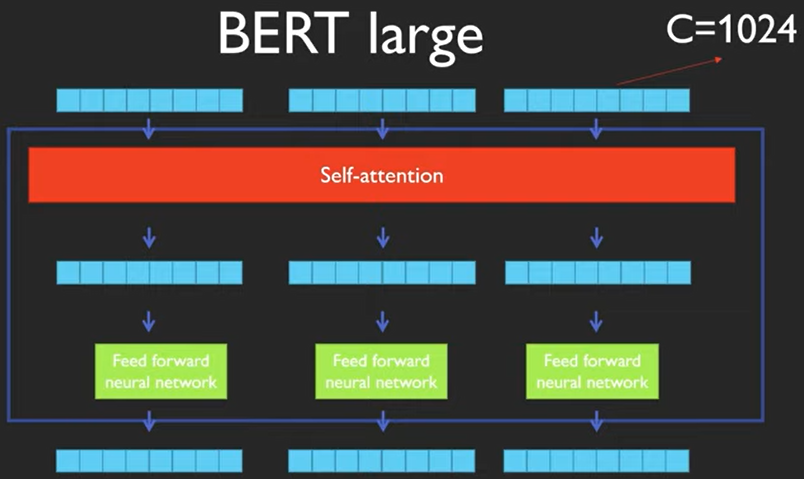
attention은 다음과 같은 차이가 있다고 합니다.
Path Merging
(DBSA 자료가 더 좋음)
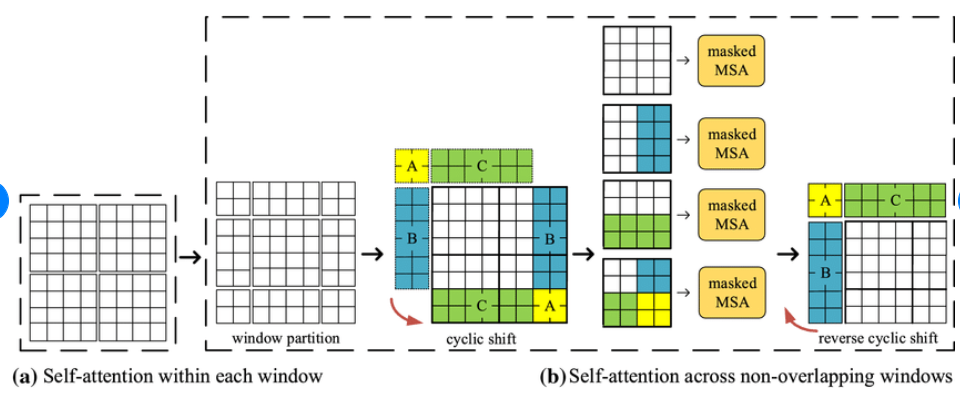
Swin Transformer
- Encoder
- W-MSA
- Decoder
- SW-MSA
공식 코드\https://paperswithcode.com/paper/swin-transformer-hierarchical-vision\
https://github.com/microsoft/Swin-Transformer
GitHub - microsoft/Swin-Transformer: This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer u
This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows". - GitHub - microsoft/Swin-Transformer: This is an official implementation...
github.com
https://arxiv.org/abs/2103.14030
DSBA에서 한 논문 리뷰
https://youtu.be/2lZvuU_IIMA
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
간단한 코드 1
간단한 코드 2
https://github.com/WangFeng18/Swin-Transformer/blob/master/SwinTransformer.py
GitHub - WangFeng18/Swin-Transformer: Implementation of Swin Transformer with Pytorch
Implementation of Swin Transformer with Pytorch. Contribute to WangFeng18/Swin-Transformer development by creating an account on GitHub.
github.com
https://www.youtube.com/watch?v=SndHALawoag&ab_channel=AICoffeeBreakwithLetitia
'관심있는 주제 > Paper' 카테고리의 다른 글
| LLM) 논문 내용 정리 Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone (2) | 2024.05.01 |
|---|---|
| CLIP (Contrastive Language-Image Pre-Training) 알아보기 (0) | 2022.08.13 |
| 논문 리뷰) A Generalist Agent (GATO) (0) | 2022.05.25 |
| [Paper][RL] [ToDo]Mutual Information State Intrinsic Control 리뷰 (0) | 2022.05.19 |
| Paper) Deep Learning for Anomaly Detection: A Review (0) | 2022.02.27 |
데이터분석뉴비님의
글이 좋았다면 응원을 보내주세요!