동행 복권 당첨 데이터를 가지고 추후에 통계치나 시각화를 통해서 분석해보고자 한다.
dhlottery.co.kr/common.do?method=main
동행복권
당첨번호 1 18 28 31 34 43 보너스번호 40 1등 총 당첨금 233억원(12명 / 19억) 이전 회차 당첨정보 보기 다음 회차 당첨정보 보기
dhlottery.co.kr
데이터 불러오기 및 포맷 변경하기 (wide -> long)
data = pd.read_csv("./dhlottery_data.csv")
win_nums = np.vstack(data["win_nums"].\
apply(lambda x : np.array(ast.literal_eval(x))).values)
win_nums_pd = pd.DataFrame(win_nums, columns = [f"number_{i}" for i in range(1,7)])
data2 = pd.concat([data , win_nums_pd],axis=1).\
drop(columns=["win_nums"],axis=1)
data2["sum"] = win_nums_pd.sum(axis=1).values
data2["draw_date"] = pd.to_datetime(data2["draw_date"])
data2['year'] = pd.DatetimeIndex(data2['draw_date']).year
data2['month'] = pd.DatetimeIndex(data2['draw_date']).month
data2['Week_Number'] = data2['draw_date'].dt.week
월별로 숫자의 총합을 이용하여 데이터 분석한 것을 시각화
월별로 동일한 분포를 띄지는 않는 것으로 보아 일부러 맞추는 행위는 하지 않아 보인다.
월마다 자주 나오는 구간이 있긴 한데, 이것이 패턴이 있더라는 것과 상관성이 있을지는 모르겠다.
data_long = pd.melt(data2, id_vars=["round_num","draw_date"],
value_vars=[f"number_{i}" for i in range(1,7)],
var_name="추출",value_name="당첨번호")
data_long.head()


연도별로 당첨 복권의 빈도수를 treemap
연도별로 treemap으로 복권 당첨 번호 빈도수를 분석
월별로 당첨 복권의 빈도수를 treemap으로 시각화
달별로 잘 나오는 숫자는 있다는 것을 알 수 있었다.
현재는 5월인데, 균등하게 나오는데 그나마 34 혹은 5가 많이 나오는 것을 알 수 있다.
주차별로 시각화
import datetime
my_date = datetime.date.today()
year, week_num, day_of_week = my_date.isocalendar()
print("Week #" + str(week_num) + " of year " + str(year))
## Week #19 of year 2021

이번 주는 24,34,20,35,2가 먼가 상대적으로 더 많이 나온 것을 알 수 있다.
먼가 상대적으로 봤을 때 확실히 많이 나오는 것 같아서 신기하다.
사실 복권으로 머신러닝 하기에는 말이 안 되는 부분이 있지만, 일단 생각해보면 비지도는 일단 아니고, 지도나 강화 학습 중에 있을 텐데, 지도 학습도 먼가 로스를 구성하는 데 있어서 실제 기대하는 성과랑 다르게 학습된 것 같아서 강화 학습으로 구성해서 해볼까 말까를 고민 중이다.
각각의 숫자별로 시간이 지날수록 패턴(?)보다는 암튼 어떤 통계치들이 나오게 되는데, 혹시나 이런 것들이 어떠한 연관성이 있을 수 있지 않을까라는 기대로 시도를 해볼까 말까 고민 중이다.
어느 정도 환경 구성에 대한 나이브한 아이디어를 가지고 있어서 금방 할 수 있을 것 같기도 한데, 암튼 고민 중이다.
복권 데이터로 통계치 분석을 추후에 계속 할 예정이다.
머신러닝을 이용하여 복권 후보군 찾기(963)
딥러닝 방법론을 적용하여 multi label로 학습시켜봤다.
실제로 과적합이 되어가고 있겠지만, 일단은 loss는 감소하는 형태를 띠고 있었다.
혹시 모르는 패턴을 찾았을까?! 하는 기대를 해본다.


963회에서 유력하다고 나오는 번호는 33,0,13,20,14,4 정도가 있으며, 실제로 확률 값은 0.5보다 크지도 못한 상황이지만, 이것이 잘 된다는 것을 기대하고, 이것들을 기반으로 복권을 사봤다... 결과는 곧 나오니 기대해보기로...(내돈내복)
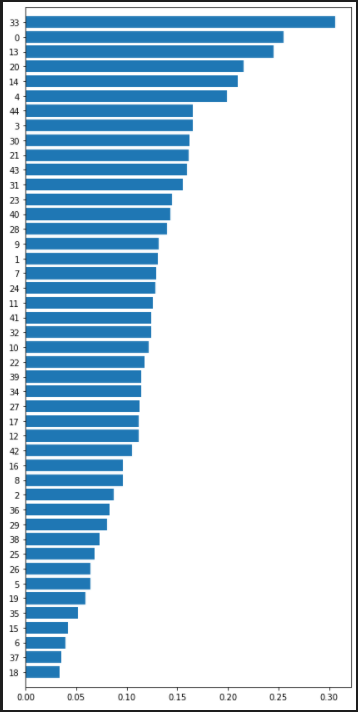
결과...
처참하게 틀렸다ㅠㅠㅠㅠ
거의 전부 다 틀린 것을 확인하였다
오히로 확률이 높은 것보다

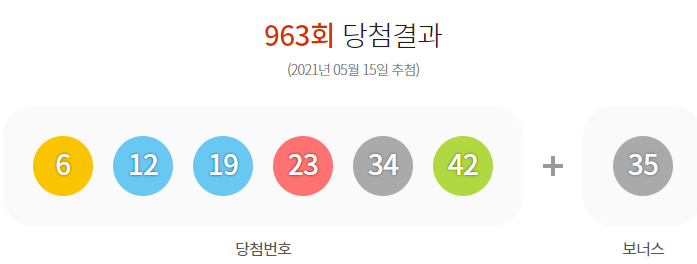

예측한 상위권의 숫자는 거의 나오지 않았고, 밑에 있는 값들이 더 많이 나왔다.
기대한 것은 몇개라도 더 맞추는 것을 기대하였지만... 실패
참고
[plotly] 티스토리/웹페이지에 반응형 그래프 올리기
티스토리에 글을 쓰다보니 반응형 그래프를 올려보고 싶어졌다. 컴알못+영알못이지만 구글을 열심히 뒤져서 힘들게 찾아낸 방법이다! 내가 그래프를 올리고자 한 티스토리 위주로 이번 글을 작
mizykk.tistory.com
로또의 정석! 앞수합과 뒷수합으로 도출한 이번주 당첨번호는?
한국복권데이터에서 최근 30회차 로또 당첨결과를 분석한 결과, 하나의 법칙이 발견되었습니다. 과연 무엇일까요?
blog.lottery.or.kr