728x90
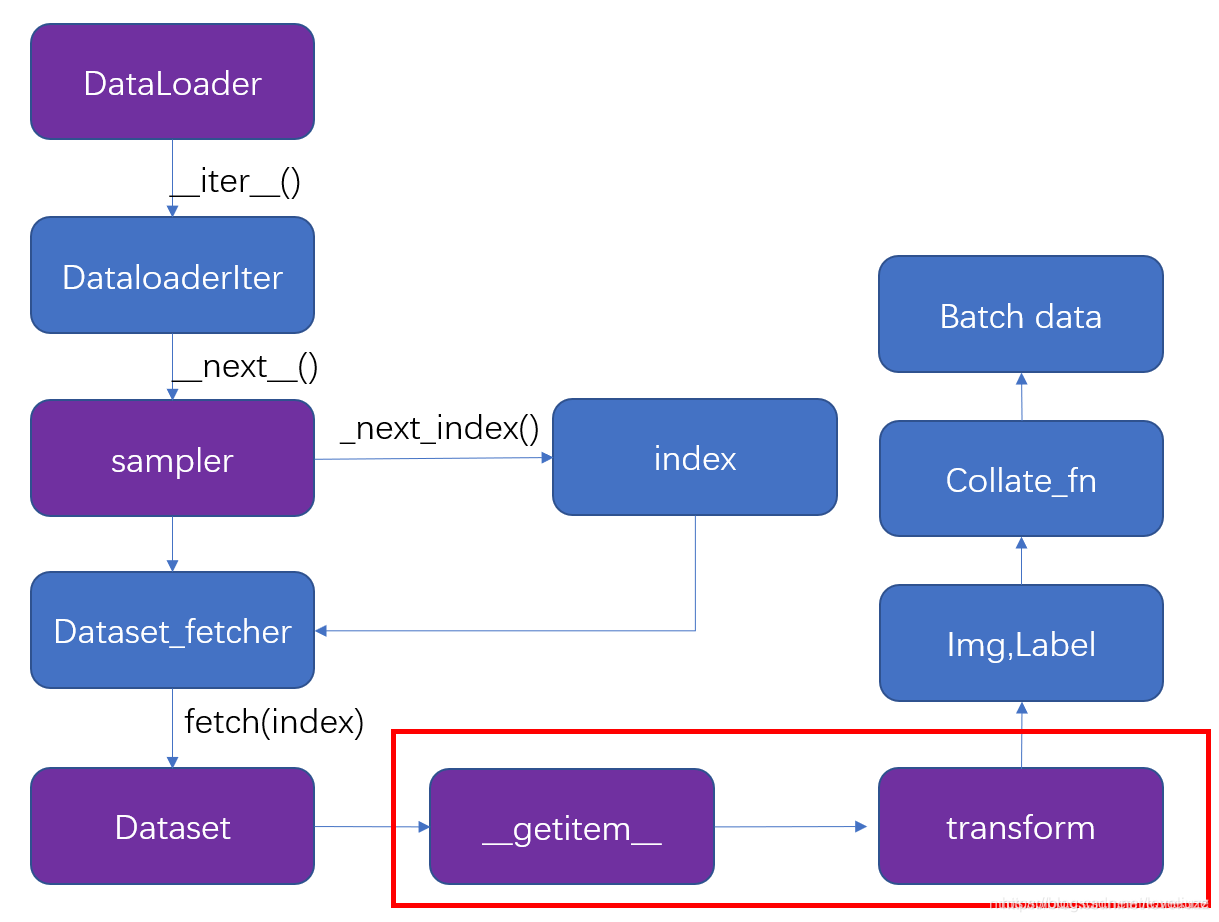
OverSampler / StratifiedSampler 구현물
OverSampler는 다른 코드를 참고해서 수정해봤습니다.
OverSampler
from torch.utils.data import Sampler
class OverSampler(Sampler):
"""Over Sampling
Provides equal representation of target classes in each batch
"""
def __init__(self, class_vector, batch_size):
"""
Arguments
---------
class_vector : torch tensor
a vector of class labels
batch_size : integer
batch_size
"""
self.n_splits = int(class_vector.size(0) / batch_size)
self.class_vector = class_vector
self.indices = list(range(len(self.class_vector)))
self.batch_size =batch_size
uni_label = torch.unique(class_vector)
uni_label_sorted, _ = torch.sort(uni_label)
print(uni_label_sorted)
uni_label_sorted = uni_label_sorted.detach().numpy()
label_bin = torch.bincount(class_vector.int()).detach().numpy()
label_to_count = dict(zip(uni_label_sorted , label_bin))
weights = [ len(class_vector) / label_to_count[float(label)] for label in class_vector]
self.weights = torch.DoubleTensor(weights)
def __iter__(self):
return (self.indices[i] for i in torch.multinomial(
self.weights, self.batch_size, replacement=True))
def __len__(self):
return len(self.class_vector)StratifiedSampler
class StratifiedSampler(Sampler):
"""Stratified Sampling
Provides equal representation of target classes in each batch
"""
def __init__(self, class_vector, batch_size):
"""
Arguments
---------
class_vector : torch tensor
a vector of class labels
batch_size : integer
batch_size
"""
self.n_splits = int(class_vector.size(0) / batch_size)
self.class_vector = class_vector
def gen_sample_array(self):
try:
from sklearn.model_selection import StratifiedShuffleSplit
except:
print("Need scikit-learn for this functionality")
import numpy as np
s = StratifiedShuffleSplit(n_splits=self.n_splits, test_size=0.7)
X = torch.randn(self.class_vector.size(0), 2).numpy()
y = self.class_vector.numpy()
s.get_n_splits(X, y)
train_index, test_index = next(s.split(X, y))
return np.hstack([train_index, test_index])
def __iter__(self):
return iter(self.gen_sample_array())
def __len__(self):
return len(self.class_vector)from sklearn.utils.class_weight import compute_class_weight
class StratifiedSampler(Sampler):
"""Over Sampling
Provides equal representation of target classes in each batch
"""
def __init__(self, class_vector, batch_size):
"""
Arguments
---------
class_vector : torch tensor
a vector of class labels
batch_size : integer
batch_size
"""
self.n_splits = int(class_vector.size(0) / batch_size)
self.class_vector = class_vector
self.indices = list(range(len(self.class_vector)))
self.batch_size =batch_size
target_class = np.unique(class_vector.detach().cpu().numpy())
target_weight = compute_class_weight(
class_weight='balanced',
classes=target_class , y=class_vector.detach().cpu().numpy())
self.mapping_sampling_weights = dict(zip(target_class , target_weight))
self.mapping_sampling_weights[1] = self.mapping_sampling_weights[1] / 2
weights = [ self.mapping_sampling_weights[int(label)] for label in class_vector]
self.weights = torch.DoubleTensor(weights)
def __iter__(self):
return (self.indices[i] for i in torch.multinomial(
self.weights, self.batch_size, replacement=True))
def __len__(self):
return len(self.class_vector)
How to use
traindataset = ## DataSet Custom Class
trainsampler = OverSampler(class_vector=torch.from_numpy(label.values.squeeze()),
batch_size=batch_size)
trainloader = DataLoader(traindataset, batch_size=batch_size, shuffle=False,
sampler=trainsampler,num_workers =5,drop_last= True)'분석 Python > Pytorch' 카테고리의 다른 글
| Pytorch 1.11 이후) torchdata 알아보기 (0) | 2022.03.14 |
|---|---|
| pytorch 1.8.0 램 메모리 누수 현상 발견 및 해결 (0) | 2021.12.18 |
| [Pytorch] gather 함수 설명 (특정 인덱스만 추출하기) (1) | 2021.03.17 |
| PyGAD + Pytorch + Skorch+ torch jit (0) | 2021.01.30 |
| [Pytorch] Error : Leaf variable has been moved into the graph interior 해결 방법 공유 (0) | 2021.01.16 |