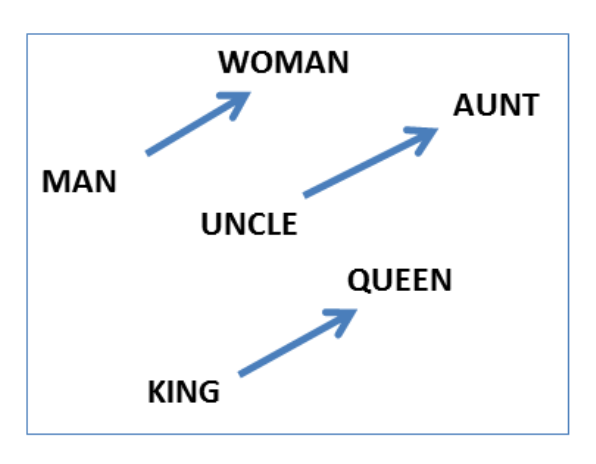
word2 vec을 들어본 사람이라면 아래 그림과 같은 예제를 많이 보게 될 것이다.
word2 vec을 사용하면 단어를 특정 공간에 투영시켜놓는다
그리고 이게 잘 학습이 된다면 단어들이 의미 있는 공간에 투영되게 된다.
그래서 아래 그림에서 보면 성별을 기준으로 같은 방향으로 움직이면 다른 성별에 관련된 단어와 연관이 있다는 것을 알 수 있게 된다. 이런 식으로 sparse representation(one-hot)에서 dense representation(distributed representation)으로 변하게 할 수 있다. 이렇게 하면 기존의 n 차원에서 더 작은 m 차원으로 줄여줄 수가 있게 돼서 차원의 저주라는 문제에 대해서 어느 정도 해소시켜줄 수 있다. 그뿐만 아니라 일반화 능력도 가질 수 있게 된다. 기존에 one-hot으로 하면 각 범주에 대한 관계가 구별되어 있지만, 이런 식으로 embedding을 시키게 되면 아래 예제처럼 (man, uncle)의 관계를 알 수 있게 된다.
그래서 이번 글에서는 단어가 아닌 범주형 변수를 embedding 하는 것을 하고자 한다.
사용하는 이유는 위와 마찬가지로 차원의 저주 문제를 해결하기 위해서 사용한다.
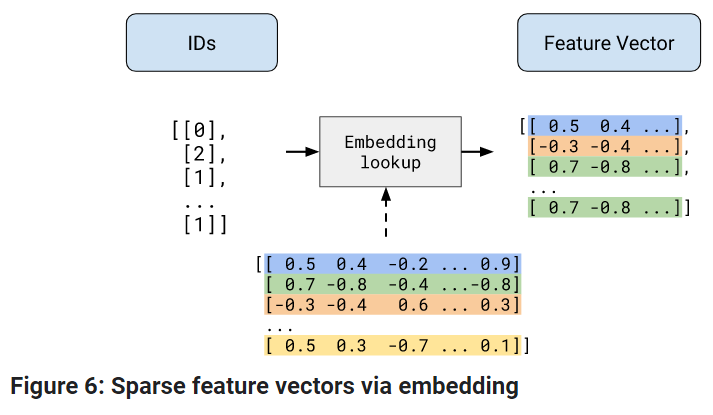
만약에 ID를 변수로 사용하고 싶은데 아이디가 1~10000개라고 하자. 일반적인 방법으로 one-hot을 하게 되면 10000차원의 sparse vector를 얻게된다. 이렇게 되면 학습에 분명히 굉장히 영향을 줄 것이라고 생각한다.
그래서 이러한 onehot을 해결하는 방법을 word2vec 아이디어를 가져와서 dense 한 representation으로 만들어주는 것을 한다.
https://data-newbie.tistory.com/130?category=772751
[Python] 실습 Categorical 변수를 Embedding 해보기
https://data-newbie.tistory.com/90?category=749566 NN에서 Categorical Variables에 대해서는 어떻게 해야할까? 현재 Neural Network는 주로 이미지나 비디어 같이 Unconstructed Data에 대해서 Convolution을..
data-newbie.tistory.com
코드는 위의 글에서 참고하시면 된다.
다른 프레임워크는 모르겠지만 tensorflow에서는 tf.embedding_lookup을 통해서 구현할 수 있다.
그래서 여기서는 이렇게 embedding한 값을 tensorboard에 시각화하는 것을 해보겠다.
일단 우리가 하고자 하는 category 범주들을 확인하자.
data = pd.read_csv("./Data/income_evaluation.csv")
objcol = data.select_dtypes("object").columns.tolist()
data[objcol] = data[objcol].astype("category")
data.columns = [i.strip() for i in data.columns.tolist()]
data["income"] = data["income"].cat.codes
target = data.pop("income")
num_col = data.select_dtypes("int").columns.tolist()
cat_col = data.select_dtypes("category").columns.tolist()
from sklearn.model_selection import train_test_split
Train_X , Test_X , Train_y , Test_y =\
train_test_split(data , target ,
test_size = 0.3,
stratify =target)Train_X[cat_col].head()
각각의 범주형 변수에 몇개가 있는지 확인해보자. (test 데이터와 비교도 하면서)
for col in cat_col :
tr_n = set(Train_X[col].unique())
te_n = set(Test_X[col].unique())
intersect = tr_n & te_n
print(f"{col}, {len(tr_n)}=={len(te_n)}=={len(intersect)}?")
if len(tr_n) != len(te_n) :
te_need = tr_n.difference(te_n)
tr_need = te_n.difference(tr_n)
print("="*15)
print(f"Warning! Check : {col}")
print(f"Train Need Category : {tr_need}")
print(f"Test Need Category : {te_need}")
native-country 같은 경우 총 42개 정도가 있다.
일단 이 놈들을 숫자값으로 encoding 해주자.
LabelEncoding = {}
for col in cat_col :
print(col)
encoding = LabelEncoder()
category = list(set(list(Train_X[col].unique()) + ["Unknown"]))
encoding.fit(category)
Train_X[col] = Train_X[col].cat.add_categories('Unknown')
Train_X[col] = Train_X[col].fillna('Unknown')
Train_X[col] = encoding.transform(Train_X[col])
LabelEncoding[col] = encoding
그래서 나중에 저 값과 label을 맵핑을 시켜줘야 한다.
맵핑은 다음처럼 하면 된다.

workclass 변수에 대해서 0은? 1은 Federal-gov처럼 다 맵핑을 해주는 것을 가지고 있어야 나중에 projector에다가 맵핑을 해줄 수가 있게 된다.
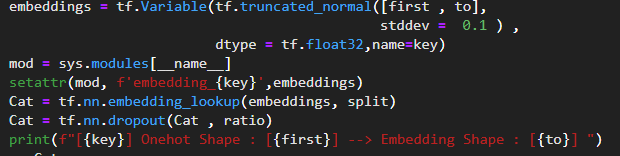
이제 embeddings에다가 각각의 범주형 변수를 맵핑을 해준다.
이제 실제 코드에서는 아래 부분을 추가해주면 된다.
아래 코드의 의미는 각각의 범주마다 tsv파일을 만든다.
그리고 그것을 embedding tensor name에다가 맵핑을 시켜준다.
saver = tf.train.Saver()
config = projector.ProjectorConfig()
mod = sys.modules[__name__]
for cat in cat_col :
if len(LabelEncoding[cat].classes_) < 5 :
continue
index2word_map = dict(zip(np.arange(len(LabelEncoding[cat].classes_)).tolist() ,
LabelEncoding[cat].classes_))
metadata_file = os.path.join(ResultPath, f'train_{trial.number}',
f'metadata_{trial.number}_{cat}.tsv')
with open(metadata_file, "w") as metadata:
metadata.write('Name\tClass\n')
for k, v in index2word_map.items():
metadata.write('%s\t%d\n' % (v, k))
embedding = config.embeddings.add()
embedding.tensor_name = getattr(mod, f'embedding_{cat}').name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = metadata_file
projector.visualize_embeddings(train_writer, config)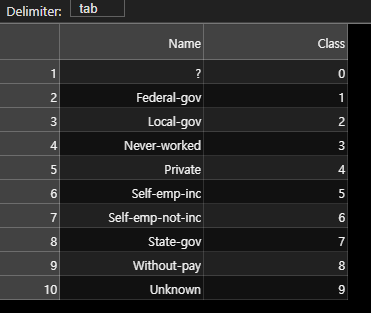
주의해야 할 점은 projector만 사용하면 안 되고 tf.train.Saver도 같이 사용해야 tensorboard에서 보인다.
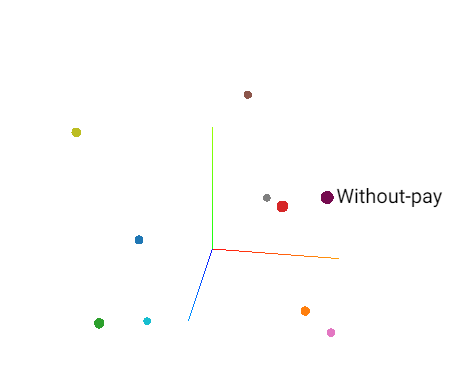
실제로 tensorboard에서 보면 다음과 같은 결과를 얻을 수 있다.
이제 잘 학습이 되면 범주끼리 유사한 것이 어떻게 되는지 알 수 있을 것이다.

참고 코드
Hezi-Resheff/Oreilly-Learning-TensorFlow
Contribute to Hezi-Resheff/Oreilly-Learning-TensorFlow development by creating an account on GitHub.
github.com
'분석 Python > Tensorflow' 카테고리의 다른 글
| [ Tensorflow ] AUC 구하기 (0) | 2020.02.21 |
|---|---|
| Tensorflow Version 1 tune 간단 예제 (0) | 2020.02.02 |
| [ Python ] tensorflow에서 결측치(na)를 특정값으로 대체하기 (0) | 2020.01.12 |
| tf.scan, tf.less , tf.assign , projector, tf.dtypes (0) | 2020.01.05 |
| Tensorflow 1.x Tabular Data Neural Network Modeling (0) | 2020.01.04 |