2019. 10. 15. 21:37ㆍ관심있는 주제/Activation Function
새로운 activation을 소개하는 논문이 나왔다.
일단 논문은 안읽고 바로 적용하면서 부분적으로 읽어서 좋은 점만 알아보는 걸로...
def relu(x):
return max(0,x)
def swish(x) :
return x * tf.nn.sigmoid(x)
def mish(x) :
return x * tf.nn.tanh( tf.nn.softplus(x))


mish를 사용하니, 평균 정확도도 올라가고 정점의 정확도도 올라가는 것을 확인했다고 함.
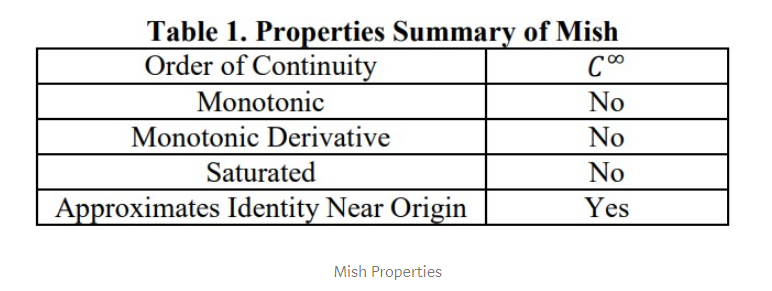

왜 Mish가 잘 되는지?
1. 위에 무한이 있으면(즉, 양의 값이 어떤 높이로든 갈 수 있음) 캡핑으로 인한 포화를 피할 수 있다.
2. 약간의 음수를 허용해서 relu zero bound 보다는 gradient 가 더 잘 흐르게 함.
마지막으로 현재 생각은 smooth activation function은 network 안에서 정보를 더 잘 흐르게 해서 일반화와 정확도를 높일 수 있다.

깊은 신경망 구조를 만들어도 더 학습이 안정성 있게 잘 되는 것을 보여주는 그래프
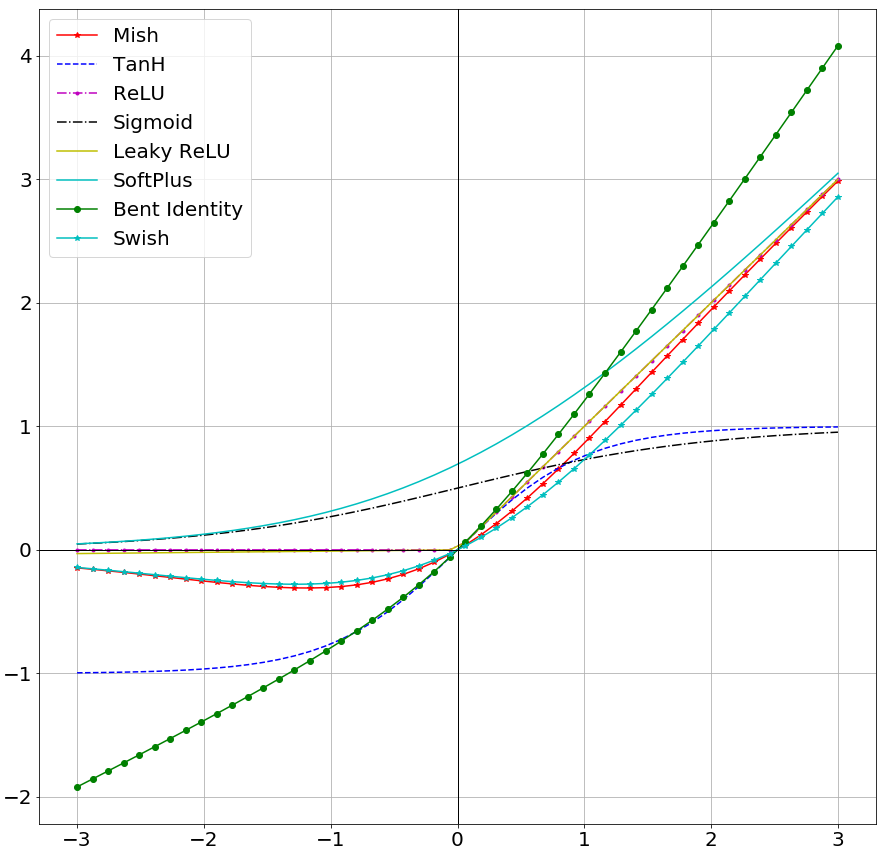

모양상으로는 swish와 유사함.
하지만 1차 도함수와 2차 도함수에는 좀 더 눈에 띄는 차이가 남
1차에서는 양수 쪽에서 좀 더 너무 크게 될 경우 gradinet를 음수로 더 빨리 줘서 안쪽으로 모는 효과?
(더 0쪽으로 모는 효과가 더 빠르다?)
아래 github에 더 많은 시각화 그래프 제공함
암튼 결론적으로 mish가 짱이라고 하는 듯
https://github.com/digantamisra98/Mish
digantamisra98/Mish
Mish: A Self Regularized Non-Monotonic Neural Activation Function - digantamisra98/Mish
github.com
https://arxiv.org/abs/1908.08681
Mish: A Self Regularized Non-Monotonic Neural Activation Function
The concept of non-linearity in a Neural Network is introduced by an activation function which serves an integral role in the training and performance evaluation of the network. Over the years of theoretical research, many activation functions have been pr
arxiv.org
'관심있는 주제 > Activation Function' 카테고리의 다른 글
| Gaussian Error Linear Unit Activates Neural Networks Beyond ReLU (GELU, ELU, RELU 비교글) (0) | 2020.01.05 |
|---|---|
| Swish , Selu activation function 둘중에는 Selu? (2) | 2019.09.14 |