2025. 4. 16. 21:55ㆍ분석 Python
소개
최근 AI 음성 인식 기술의 발전으로 다양한 서비스에서 음성-텍스트 변환 기능이 중요해지고 있습니다. 특히 OpenAI의 Whisper 모델은 뛰어난 인식 정확도와 다국어 지원으로 주목받고 있죠. 하지만 이러한 모델을 실제 서비스에 통합하기 위해서는 안정적이고 확장 가능한 API 시스템이 필요합니다.
이 글에서는 FastAPI, Celery, Redis를 활용하여 비동기적으로 여러 음성 파일을 처리할 수 있는 Whisper 음성 인식 API 시스템을 구축하는 방법을 소개합니다.
사실 이 프로젝트는 제가 최근 마이크로서비스 아키텍처와
비동기 처리 시스템에 대한 깊이 있는 이해를 얻기 위해 시작한 개인 학습 프로젝트입니다.
FastAPI의 비동기 처리 기능과
Celery의 분산 작업 처리 능력을 실제로 경험해보고 싶었습니다.
Whisper 같은 대규모 AI 모델은 처리 시간이 상당히 길어 동기식 처리 방식으로는 사용자 경험이 크게 저하될 수 있습니다.
특히 여러 오디오 파일을 처리해야 하는 경우 더욱 그렇죠.
이 문제를 해결하기 위해 FastAPI의 비동기 기능과 Celery의 작업 큐 시스템을 결합했고,
Redis를 메시지 브로커로 활용해 시스템의 확장성을 높였습니다.
실제 업무 환경에서도 이와 같은 아키텍처는 다양한 활용 사례가 있습니다.
예를 들어, 회의 녹음 자동 기록 서비스, 다국어 콘텐츠 플랫폼의 자막 생성 시스템,
고객 센터 통화 내용 분석 도구 등 다양한 비즈니스 영역에서 이러한 기술이 활용될 수 있습니다.
이 프로젝트를 통해 비동기 프로그래밍, 분산 작업 처리, Docker 기반 마이크로서비스 배포,
그리고 AI 모델의 효율적인 활용 방법에 대해 많은 것을 배울 수 있었습니다.
특히 실시간 처리와 배치 처리의 균형을 맞추는 것이 중요한 도전 과제였습니다.
이제 시스템 아키텍처부터 구현 세부사항까지 하나씩 살펴보겠습니다.
시스템 아키텍처
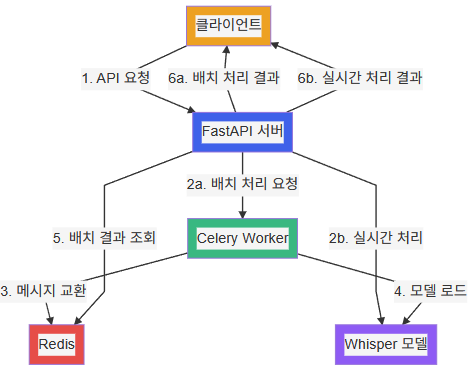
우리가 구현할 시스템은 다음과 같은 구성요소로 이루어져 있습니다:
1. FastAPI 서버: 클라이언트 요청을 받고 응답을 반환하는 API 서버
2. Celery Worker: 오디오 처리 작업을 비동기적으로 실행
3. Redis: Celery의 메시지 브로커 및 결과 저장소 역할
4. Whisper 모델: 실제 음성-텍스트 변환을 수행하는 AI 모델
전체 시스템은 Docker Compose를 통해 컨테이너화되어 쉽게 배포 가능합니다. 각 구성요소는 독립적인 컨테이너로 실행되어 확장성과 유지보수성을 높였습니다.
이 아키텍처의 핵심은 두 가지 처리 경로를 제공한다는 점입니다:
배치 처리 경로: 다수의 오디오 URL을 비동기적으로 처리 (Celery Worker 활용)
실시간 처리 경로: 단일 오디오를 동기적으로 처리 (직접 Whisper 모델 호출)
이렇게 두 가지 경로를 제공함으로써 다양한 사용 사례에 유연하게 대응할 수 있습니다.
주요 기능
이 시스템은 다음과 같은 기능을 제공합니다:
1. 배치 처리 API: 여러 오디오 URL을 한 번에 처리하는 비동기 API
2. 실시간 처리 API:
- URL 기반: 단일 오디오 URL을 실시간으로 처리
- 파일 업로드 기반: 직접 업로드한 오디오 파일을 처리
3. 병렬 처리: Celery 작업 내에서 asyncio를 활용한 병렬 다운로드 및 처리
4. 캐싱 최적화: lru_cache를 활용한 Whisper 모델 로딩 최적화
구현 세부 사항
1. 프로젝트 구조
whisper_api/
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPI 서버
│ ├── tasks.py # Celery Task 정의
│ └── config.py # 설정 파일
├── docker/
│ └── celery_worker.sh # Worker 실행 스크립트
├── docker-compose.yml # Docker Compose 설정
├── Dockerfile # Docker 이미지 빌드
├── requirements.txt # 패키지 의존성
├── README.md # 사용 설명서
├── test_api.py # 배치 API 테스트 스크립트
└── test_realtime_api.py # 실시간 API 테스트 스크립트
2. 설정 관리 (config.py)
설정을 중앙에서 관리하여 환경 변수를 통해 쉽게 조정할 수 있게 했습니다.
import os
# Redis 설정
REDIS_HOST = os.getenv("REDIS_HOST", "redis")
REDIS_PORT = int(os.getenv("REDIS_PORT", "6379"))
REDIS_DB = int(os.getenv("REDIS_DB", "0"))
# Celery 설정
CELERY_BROKER_URL = f"redis://{REDIS_HOST}:{REDIS_PORT}/{REDIS_DB}"
CELERY_RESULT_BACKEND = f"redis://{REDIS_HOST}:{REDIS_PORT}/{REDIS_DB}"
# Whisper 모델 설정
WHISPER_MODEL = os.getenv("WHISPER_MODEL", "base")
WHISPER_DEVICE = os.getenv("WHISPER_DEVICE", "cpu")
WHISPER_COMPUTE_TYPE = os.getenv("WHISPER_COMPUTE_TYPE", "float32")
# 병렬 처리 설정
CONCURRENT_DOWNLOADS = int(os.getenv("CONCURRENT_DOWNLOADS", "4"))
DOWNLOAD_TIMEOUT = int(os.getenv("DOWNLOAD_TIMEOUT", "300")) # 5분
3. Celery 태스크 구현 (tasks.py)
Celery를 통한 비동기 처리와 모델 로딩 최적화를 위한 lru_cache 적용이 핵심입니다.
from functools import lru_cache
from celery import Celery
from faster_whisper import WhisperModel
# Whisper 모델 로드 함수 (LRU 캐시 적용)
@lru_cache(maxsize=1)
def load_whisper_model(model_name=None, device=None, compute_type=None):
"""Whisper 모델을 로드하고 캐싱합니다."""
model_name = model_name or WHISPER_MODEL
device = device or WHISPER_DEVICE
compute_type = compute_type or WHISPER_COMPUTE_TYPE
return WhisperModel(model_name, device=device, compute_type=compute_type)
# Celery 배치 트랜스크립션 태스크
@celery_app.task(name="tasks.transcribe_batch")
def transcribe_batch(urls, language):
"""여러 오디오 URL을 병렬로 처리하는 태스크"""
# 비동기 큐 생성
queue = asyncio.Queue()
for url in urls:
queue.put_nowait(url)
# 결과 리스트
results = []
# asyncio 작업 실행
async def runner():
workers = [
queue_worker(queue, results, language)
for _ in range(min(CONCURRENT_DOWNLOADS, len(urls)))
]
await asyncio.gather(*workers)
# 비동기 실행
asyncio.run(runner())
return results
4. FastAPI 서버 구현 (main.py)
배치 처리와 실시간 처리를 위한 다양한 엔드포인트를 제공합니다.
from fastapi import FastAPI, HTTPException, File, UploadFile, Form
from pydantic import BaseModel, HttpUrl
# API 애플리케이션 생성
app = FastAPI(
title="Whisper 음성 인식 API",
description="비동기적으로 여러 오디오 파일을 다운로드하고 Whisper로 처리하는 API",
version="1.0.0",
)
# 배치 트랜스크립션 요청 엔드포인트
@app.post("/transcribe/batch", response_model=TaskStatus)
async def transcribe_batch_endpoint(request: TranscriptionRequest):
task = transcribe_batch.delay(
urls=[str(url) for url in request.urls],
language=request.language
)
return {"status": "success", "task_id": task.id}
# 실시간 트랜스크립션 요청 엔드포인트 (URL 기반)
@app.post("/transcribe/realtime", response_model=RealtimeTranscriptionResponse)
async def transcribe_realtime(request: RealtimeTranscriptionRequest):
# 구현 생략...
pass
# 파일 업로드를 통한 실시간 트랜스크립션
@app.post("/transcribe/upload", response_model=RealtimeTranscriptionResponse)
async def transcribe_upload(file: UploadFile = File(...), language: str = Form("en")):
# 구현 생략...
pass
API 사용 방법
1. 배치 처리 API
여러 오디오 URL을 한 번에 처리하고 task_id를 반환받은 후, 상태 확인 API로 결과를 조회합니다.
# 트랜스크립션 요청
curl -X POST http://localhost:8000/transcribe/batch \
-H "Content-Type: application/json" \
-d '{
"urls": ["https://github.com/openai/whisper/raw/main/tests/jfk.flac"],
"language": "ko"
}'
# 결과 조회
curl -X GET http://localhost:8000/transcribe/{task_id}/status
2. 실시간 처리 API
단일 URL이나 파일을 바로 처리하고 결과를 받습니다.
# URL 기반 실시간 처리
curl -X POST http://localhost:8000/transcribe/realtime \
-H "Content-Type: application/json" \
-d '{
"url": "https://github.com/openai/whisper/raw/main/tests/jfk.flac",
"language": "ko"
}'
# 파일 업로드 기반 처리
curl -X POST http://localhost:8000/transcribe/upload \
-F "file=@/path/to/audio.mp3" \
-F "language=ko"
테스트 자동화
테스트 자동화를 위한 Python 스크립트를 제공합니다.
# test_realtime_api.py 샘플 코드
def test_realtime_url():
"""실시간 URL 기반 트랜스크립션 테스트"""
print("\n===== 실시간 URL 트랜스크립션 테스트 =====")
start_time = datetime.now()
# 요청 데이터
data = {
"url": "https://github.com/openai/whisper/raw/main/tests/jfk.flac",
"language": "ko"
}
# 트랜스크립션 요청
response = requests.post(f"{API_URL}/transcribe/realtime", json=data)
end_time = datetime.now()
duration = (end_time - start_time).total_seconds()
print(f"처리 시간: {duration:.2f}초")
result = response.json()
print_json(result)
성능 최적화 고려사항
1. 모델 로딩 최적화: lru_cache 데코레이터를 사용하여 Whisper 모델이 매번 새로 로드되지 않도록 캐싱했습니다.
2. 병렬 처리: Celery 태스크 내부에서 asyncio를 활용해 여러 오디오 파일을 병렬로 다운로드 및 처리합니다.
3. 자원 할당 제어: 환경 변수를 통해 동시 다운로드 수와 모델 계산 타입을 쉽게 조정할 수 있습니다.
Docker 배포 환경
Docker Compose를 사용하여 전체 시스템을 쉽게 배포할 수 있습니다.
version: '3.8'
services:
# FastAPI 서버
api:
build:
context: .
dockerfile: Dockerfile
ports:
- "8000:8000"
environment:
- REDIS_HOST=redis
- WHISPER_MODEL=base
- WHISPER_DEVICE=cpu
- CONCURRENT_DOWNLOADS=4
depends_on:
- redis
# Celery Worker
worker:
build:
context: .
dockerfile: Dockerfile
command: /celery_worker.sh
environment:
- REDIS_HOST=redis
- WHISPER_MODEL=base
- WHISPER_DEVICE=cpu
depends_on:
- redis
# Redis 서버
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
volumes:
redis_data:
실행 방법
# Docker Compose로 시스템 실행
docker-compose up -d
# 로그 확인
docker-compose logs -f
# 테스트 스크립트 실행
python test_api.py
python test_realtime_api.py
결론
이 프로젝트를 통해 Whisper 모델을 활용한 확장 가능한 음성 인식 API 시스템을 구현해 보았습니다. FastAPI와 Celery의 조합은 비동기 작업 처리에 매우 효과적이며, Docker를 통한 컨테이너화로 손쉬운 배포가 가능합니다.
이 시스템은 다음과 같은 상황에서 특히 유용합니다:
1. 대량의 오디오 파일을 일괄 처리해야 하는 경우 (배치 API)
2. 실시간 응답이 필요한 애플리케이션 (실시간 API)
3. 사용자 업로드 파일을 직접 처리해야 하는 경우 (업로드 API)
이러한 프로젝트를 진행하면서 가장 큰 배움은 단순히 기술적인 측면에 국한되지 않았습니다. 복잡한 시스템을 설계할 때는 사용자 경험과 기술적 제약 사이의 균형을 맞추는 것이 중요하다는 점을 깨달았습니다. 특히 다음과 같은 점들이 인상 깊었습니다:
1. 아키텍처 선택의 중요성: 처음부터 확장 가능한 아키텍처를 설계함으로써 추후 발생할 수 있는 병목 현상을 미리 방지할 수 있었습니다.
2. 비동기 프로그래밍의 복잡성: 비동기 작업과 동기 작업의 적절한, 균형과 오류 처리가 매우 중요하며, 이를 통해 시스템의 안정성을 보장할 수 있었습니다.
3. 캐싱 전략의 효과: Whisper 모델 로딩에 LRU 캐시를 적용함으로써 성능을 크게 향상시킬 수 있었습니다. 이는 메모리 사용량과 처리 속도 사이의 균형을 고려한 결정이었습니다.
4. Docker의 편리함: 복잡한 의존성을 가진 시스템을 Docker로 패키징함으로써 "내 컴퓨터에서는 작동합니다" 문제를 효과적으로 해결할 수 있었습니다.
참고 자료
- [OpenAI Whisper 모델](https://github.com/openai/whisper)
- [FastAPI 공식 문서](https://fastapi.tiangolo.com/)
- [Celery 공식 문서](https://docs.celeryproject.org/)
- [Docker Compose 문서](https://docs.docker.com/compose/)
'분석 Python' 카테고리의 다른 글
| Python) Pandas read_csv 인코딩 확인하는 방법 소개 (0) | 2022.08.30 |
|---|---|
| [Python] txt 파일을 읽을 때, sep를 지정해서 분리하기 (0) | 2020.08.07 |
| openpyxl을 활용하여 Python에서 엑셀 사용하기 (0) | 2019.05.04 |