2024. 4. 14. 13:00ㆍ관심있는 주제/LLM
LLM 학습 방법을 찾는 중에, SFT, DPO, RLHF는 알고 있었는데, ORPO라는 것을 찾게 되었고, 잠깐 봤을 때, 방법론이 효율적인 것 같아서 정리해보고자 한다.
최근에 LLM 모델에서 좀 더 사람의 선호에 맞게 학습하는 방법들이 등장하고 있습니다.
기존에 RLHF, DPO, IPO, KTO 같은 방식이 생기고 있고, 기존에 RLHF방식보다는 저렴하게 할 수 있게 있습니다.
DPO, IPO 역시 기존에 RLHF 방식보다는 저렴하지만, 결국 이것도 2개의 모델이 필요합니다.
1개의 모델은 Supervised Fine-Tuning(SFT) 단계를 위한 모델 즉, 우리가 원하는 TASK에 대답을 할 수 있도록 훈련하는 것
다른 모델은 SFT 모델을 참고하여 사람이 좀 더 선호하는 모델을 만드는 것이 있습니다.
즉 이렇게 2개의 모델이 필요한데, 이번에 소개할 글은 위에서 말한 참조 모델 즉 SFT를 사용하지 않고 바로 사람이 선호하는 모델을 만드는 방식에 대한 방법론입니다.

논문에서 나온 기존 관련 작업들을 살펴보면 다음과 같습니다.
기존에 초기에 더 선호되는 답변을 만들기 위해서 강화학습 방법을 사용했습니다.
RLHF라고 하는 방법이 있었고 이는 AI 모델이 2가지 다른 반응을 비교하고, 피드백을 통해 더 나은 반응을 선택하는 방법으로 학습하는 것입니다.
이때 더 나은 선택된 방법을 REWARD라는 것으로 정의하여 학습합니다.
하지만 이 작업에는 다양한 파라미터 튜닝 작업과 최적화가 별도로 필요하여 보상 모델 없이 사람의 선호도랑 일치시키는 방법을 연구하기 시작했습니다.
그래서 나온 것이 DPO, IPO, KTO입니다.
아래는 각각에 대해서 핵심 개념과 장/단점을 적어본 것입니다.
| 기법 | 전체 명칭 | 핵심 개념 | 장점 | 단점 |
| DPO | Direct Policy Optimization | 보상 모델링 단계를 선호 학습 단계에 직접 통합 | 프로세스 단순화, 효율적인 학습 가능 | 과적합 위험성 있음 |
| IPO | Identity Preference Optimization | DPO의 과적합 문제를 해결하기 위해 정체성 기반 최적화 적용 | 과적합 방지, 더 안정적인 학습 결과 제공 | 다양성 부족 가능성 |
| KTO | Kahneman-Tversky Optimization | 짝지어진 선호 데이터 세트 없이 최적화 수행 | 데이터 요구 사항 감소, 유연성 향상 | 실제 적용에서의 효과 미확인 가능 |
그리고 현재 보통 이러한 작업을 할 때 사람들의 경험적으로 SFT로 어느 정도 결과 수렴을 달성하는 것이 먼저 필수적으로 된 다음에 보통 진행하는 것 같습니다.
SFT의 역할
그렇다면 SFT가 어떤 역할을 하는지에 대해서 알아보자.
SFT의 중요성
SFT는 사전 훈련된 언어 모델을 원하는 도메인에 맞게 조정하는 데 중요한 역할을 합니다.
이 과정에서 토큰의 로그 확률을 증가시켜 모델이 특정 도메인의 언어 스타일을 잘 이해하도록 합니다.
Cross Entropy Loss의 한계
하지만 현재 사용하는 로스 함수를 사용하게 되면 답변에 대한 로짓이 낮으면 모델한테 페널티를 주지만, 원하지 않는 답변의 로짓에 대해서는 직접적인 페널티를 주는 것이 없어서 이로 인해 원치 않는 스타일의 토큰 생성 확률이 높아질 수 있습니다.
아래의 그림이 cross entropy loss의 구조이고, 이 함수를 통해 예측된 확률 분포의 정답 간의 분포 차이를 측정합니다.

위의 수식을 보면 실제 답변에 대한 토큰 i에 대해서만 로그 확률을 계산하고 나머지 토큰은 계산하지 않습니다.
즉 yi가 0이면 해당 로그 확률은 계산에 포함이 되지 않습니다.
이러한 방식은 정답 토큰에 더 높은 확률을 부여하도록 유도할 수 있지만, 정답이 아닌 토큰에는 아무런 피드백을 주지 않는다는 뜻입니다.
이러한 방식의 학습은 결국 미세 조정에는 도움이 되지만 사람의 선호도 조정의 관점에서는 문제가 발생할 수 있습니다.
두 가지 응답 스타일에 대한 일반화
저자가 실험한 케이스에서는 Chosen만 이용해서 SFT를 한다.
그럴 때 결과를 보면 Chosen이 올라갈 때 Rejected 도 같이 올라가는 것을 확인했다고 하고 이는 일반화된 답을 생성하게 돼버린다고 볼 수 있다.

저자는 이것에서 영감을 받아서 Rejected token들에서 높게 나오는 것에 페널티를 주는 것을 생각했습니다.
그래서 저자는 특별한 거절 토큰 집합 없이 각 쿼리에 거절 답변을 동적으로 처벌하는 단일 선호도 정렬 방법을 설계하였다고 합니다.
Odds Ratio Preference Optimization
저자는 선호와 비선호를 구별하기 위해서 전통적인 음의 로그 우도(NLL) 손실에 기반한 오즈 비율 기반 페널티를 통합합니다. (negative log-likelihood loss)

오즈비를 해석해 보면, 특정 입력 시퀀스 X 다음에 Y라는 것이 나올 확률이나 나오지 않은 확률 보다 몇 배 높은 지를 의미합니다.
그래서 여기서는 조금 바꾼 것이 이 시점에 나와야 할 답변과 이 시점에 나오지 말아야 할 답변보다 몇 배 높은 지를 계산합니다.
y_w = chosne repsonse
y_l = rejected response

Objective Function of ORPO
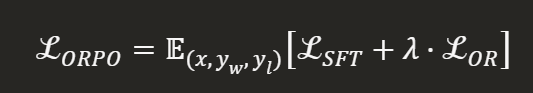
ORPO의 Loss는 크게 2개로 이루어져 있습니다.
- SFT Loss - 전통적인 손실 함수
- Relative Ratio Loss (L OR)
1번 같은 경우 기존처럼 선호 답변을 높게 하는 역할을 하는 손실함수이다.
2번 같은 경우 잘못된 답변의 단어와 좋은 답변 사이의 차이를 크게 하는 것이 목적인 손실함수이다.
우리는 여기서 최소화를 하기 위해 다음과 같이 log odd ration에다가 log sigmoid 함수를 적용한다.
결과 비교
결과를 보면 ORPO가 더 좋은 것을 가져왔을 것이다.
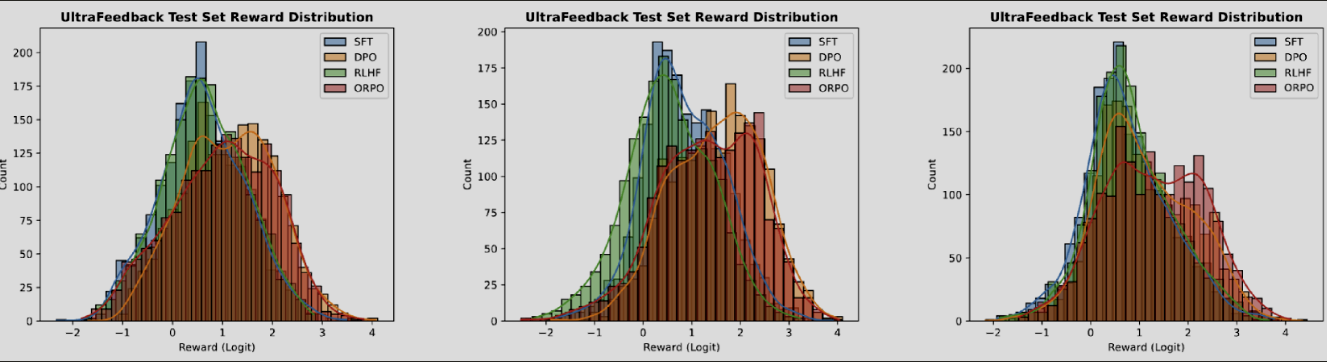
UltraFeedback using the RM-1.3B 사용하여 비교했을 때 ORPO가 기존 방식보다 리워드의 분포가 좀 더 우측으로 쏠려서 기대 리워드를 더 많이 받았다고 주장합니다.
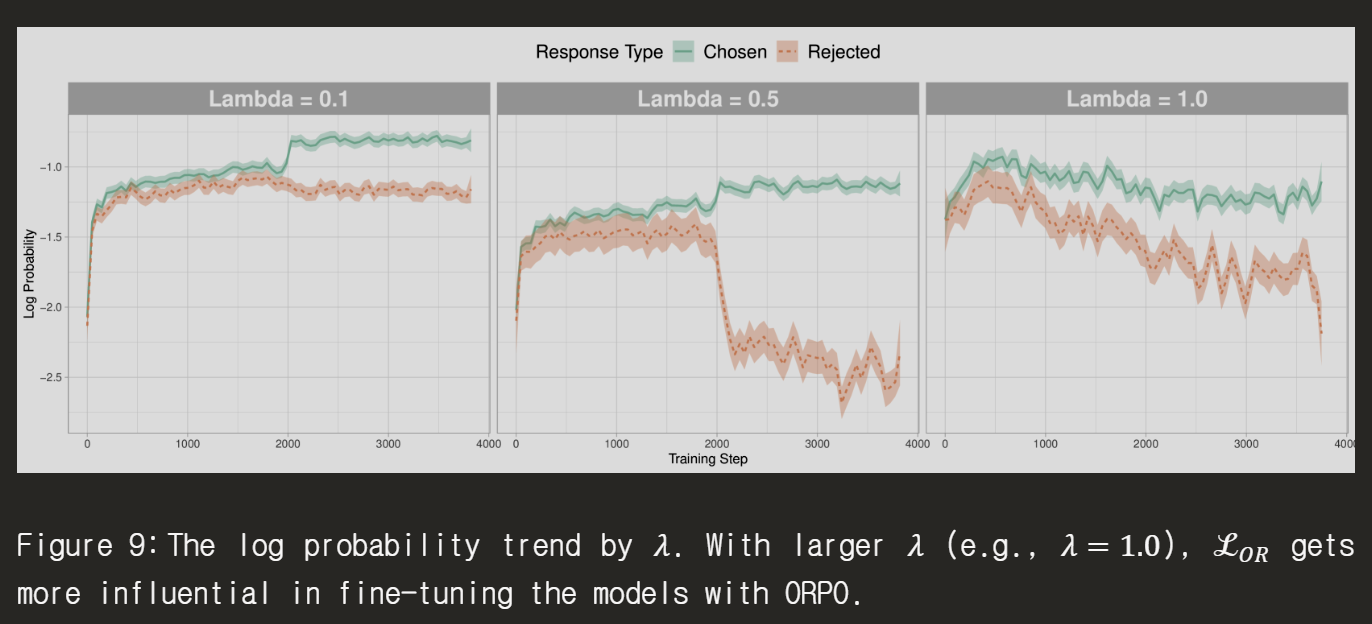
Lambda를 잘 조정하냐에 따라서 Chosen과 Rejected를 좀 더 차이가 날 수 있게 하고 여기서는 0.5가 성능은 조금 떨어지지만 말하지 못하게 할 것은 분명하게 말하지 못하게 할 것 같은 효과를 줄 수 있을 것 같습니다.
코드
코드를 보면 이미 huggingface에서 잘 감싸줘서 바로 사용할 수 있습니다.
데이터에 key를 prompt, chosen, rejected로 고정시킵니다.
orpo_dataset_dict = {
"prompt": [
"hello",
"how are you",
"What is your name?",
"What is your name?",
"Which is the best programming language?",
"Which is the best programming language?",
"Which is the best programming language?",
],
"chosen": [
"hi nice to meet you",
"I am fine",
"My name is Mary",
"My name is Mary",
"Python",
"Python",
"Java",
],
"rejected": [
"leave me alone",
"I am not fine",
"Whats it to you?",
"I dont have a name",
"Javascript",
"C++",
"C++",
],
}그리고 아래 코드처럼 처리하면 바로 사용할 수 있습니다.
orpo_config = ORPOConfig(
beta=0.1, # the lambda/alpha hyperparameter in the paper/code
)
orpo_trainer = ORPOTrainer(
model,
args=orpo_config,
train_dataset=train_dataset,
tokenizer=tokenizer,
)
orpo_trainer.train()
쉽게 사용할 수 있음을 확인했고, 항상 이 경우가 성능으로 좋게 나오는 것은 아니기 때문에 급한 경우에는 SFT를 학습시키지 않고 우선적으로 해볼 만하다고 생각합니다.
참고
https://huggingface.co/docs/trl/main/en/orpo_trainer
ORPO Trainer
huggingface.co
ORPO: Preference Optimization without the Supervised Fine-tuning (SFT) Step
A much cheaper alignment method performing as well as DPO
towardsdatascience.com
https://arxiv.org/abs/2403.07691
ORPO: Monolithic Preference Optimization without Reference Model
While recent preference alignment algorithms for language models have demonstrated promising results, supervised fine-tuning (SFT) remains imperative for achieving successful convergence. In this paper, we study the crucial role of SFT within the context o
arxiv.org
'관심있는 주제 > LLM' 카테고리의 다른 글
| LLM) Streamlit Tokenizer APP (0) | 2024.04.19 |
|---|---|
| LLM) 모델에서 사용하는 GPU 계산하는 방법 (0) | 2024.04.15 |
| LLM) Mixed-Precision 개념 및 학습 방법 알아보기 (0) | 2024.04.13 |
| LLM) PEFT 학습 방법론 알아보기 (1) | 2024.02.25 |
| LLM) Milvus 라는 Vector Database 알아보기 (0) | 2023.11.11 |