논문 리뷰) Deep Interest Network 리뷰
저자들이 주장하는 것은 한 그림을 표현하면 다음과 같다.
유저가 특정 상품에 대해서 클릭할 지 안할 것인 지 유저의 성향과 검색 기록을 바탕으로 클릭 여부를 예측한다는 것이고,
이때 가장 큰 핵심 포인트는 모든 히스토리를 동등하게 보는 것이 아닌 유저의 성향에다가 기존 검색 기록을 특정 상품과의 지역적인 특색을 합쳐서 해당 상품에 대해서 클릭 여부를 판단하겠다는 것이 이 논문에서 가장 말하고자 하는 것이라 생각한다.

저자들은 이런 문제를 기존에 풀 때는 fixed-length 의 벡터를 사용하고 있다는 것에 대해서 bottleneck이 생겨 유저의 다양성을 학습하는데 어려움이 있다가 하고, 이러한 문제를 해결하기 위해서 특정 광고와 기존 과거 행동등으로 adaptively하게 유저의 행동을 표현함으로써, feature representation을 향상시키는 deep interest network를 주장한다.
여기까지 봤을 때는 전에 우연히 봤던 BST(Behavior transformers)가 떠오르고 여기까지 보면 BST는 고정된 사이즈가 필요하지만 여기서는 없다고 하니 오히려 이 논문이 더 고도화된 방법같이 보이기도 한다.




위의 모델을 하나씩 뜯어보면 다음과 같다.
물론 구현 방식에 따라 좀 차이가 있는 것 같으나 참고하면 좋을 것 같다.
구현 코드 살펴보기
class EmbeddingLayer(nn.Module):
def __init__(self, feature_dim, embedding_dim):
super().__init__()
self.embed = nn.Embedding(feature_dim, embedding_dim, padding_idx=0)
# normal weight initialization
self.embed.weight.data.normal_(0., 0.0001)
# TODO: regularization
def forward(self, x):
return self.embed(x)
# deep input embedding
feature_embedded = []
for feature in embed_features:
feature_embedded.append(user_features[feature])
feature_embedded = torch.cat(feature_embedded, dim=1)
#print('User_feature_embed size', user_feature_embedded.size()) # batch_size * (feature_size * embedding_size)
#print('User feature done')
query_feature_embedded = []
for feature in que_embed_features:
query_feature_embedded.append(self.query_feature_embedding_dict[feature](user_features[feature].squeeze()))
for feature in que_image_features:
query_feature_embedded.append(self.query_image_fc(user_features[feature]))
for feature in que_category:
query_feature_embedded.append(user_features[feature])
query_feature_embedded = torch.cat(query_feature_embedded, dim=1)

history 에 있는 모들 데이터를 하나로 만듬
(Batch Size, T, (Feature Size * Embedding Size)
Sequence가 T인 상태에서 각 필요한 Feature 들의 embedding size만큼 붙여 놓은 형태가 history_feature_embeded
# TODO: history
history_feature_embedded = []
for feature in his_embed_features:
#print(feature)
#print(user_features[feature].size())
history_feature_embedded.append(self.history_feature_embedding_dict[feature](user_features[feature]))
#print(self.history_feature_embedding_dict[feature](user_features[feature]).size())
for feature in his_image_features:
#print(user_features[feature].size())
history_feature_embedded.append(self.history_image_fc(user_features[feature]))
for feature in his_category:
history_feature_embedded.append(user_features[feature])
history_feature_embedded = torch.cat(history_feature_embedded, dim=2)
query_feature_embedded : (batch_size , (feature_size * embedding_size))
history_feature_embedded : (batch_size , T , (feature_size * embedding_size) )
history = self.attn(query_feature_embedded.unsqueeze(1),
history_feature_embedded,
user_features['history_len'])
class AttentionSequencePoolingLayer(nn.Module):
def __init__(self, embedding_dim=4):
super(AttentionSequencePoolingLayer, self).__init__()
# TODO: DICE acitivation function
# TODO: attention weight normalization
self.local_att = LocalActivationUnit(hidden_size=[64, 16], bias=[True, True], embedding_dim=embedding_dim, batch_norm=False)
def forward(self, query_ad, user_behavior, user_behavior_length):
# query ad : size -> batch_size * 1 * embedding_size
# user behavior : size -> batch_size * time_seq_len * embedding_size
# user behavior length: size -> batch_size * 1
# output : size -> batch_size * 1 * embedding_size
attention_score = self.local_att(query_ad, user_behavior)
attention_score = torch.transpose(attention_score, 1, 2) # B * 1 * T
#print(attention_score.size())
# define mask by length
user_behavior_length = user_behavior_length.type(torch.LongTensor)
mask = torch.arange(user_behavior.size(1))[None, :] < user_behavior_length[:, None]
# mask
output = torch.mul(attention_score, mask.type(torch.cuda.FloatTensor)) # batch_size *
# multiply weight
output = torch.matmul(output, user_behavior)
return output
class LocalActivationUnit(nn.Module):
def __init__(self, hidden_size=[80, 40], bias=[True, True], embedding_dim=4, batch_norm=False):
super(LocalActivationUnit, self).__init__()
self.fc1 = FullyConnectedLayer(input_size=4*embedding_dim,
hidden_size=hidden_size,
bias=bias,
batch_norm=batch_norm,
activation='dice',
dice_dim=3)
self.fc2 = FullyConnectedLayer(input_size=hidden_size[-1],
hidden_size=[1],
bias=[True],
batch_norm=batch_norm,
activation='dice',
dice_dim=3)
# TODO: fc_2 initialization
def forward(self, query, user_behavior):
# query ad : size -> batch_size * 1 * embedding_size
# user behavior : size -> batch_size * time_seq_len * embedding_size
user_behavior_len = user_behavior.size(1)
queries = torch.cat([query for _ in range(user_behavior_len)], dim=1)
attention_input = torch.cat([queries, user_behavior, queries-user_behavior, queries*user_behavior], dim=-1)
attention_output = self.fc1(attention_input)
attention_output = self.fc2(attention_output)
return attention_output
attention을 뜯어보면 다음과 같음.
일단 LocalActivation Unit에서 Query에 있는 것을 History 의 Seq Lenght만큼 늘려줌
# LocalActivationUnit (forward)
user_behavior_len = user_behavior.size(1)
queries = torch.cat([query for _ in range(user_behavior_len)], dim=1)
# queries (batch size , seq length , (feature size * embedding size)
# use_behavior (batch size , seq length , (feature size * embedding size)
# 해당 데이터를 다시 마지막 축을 기준으로 concat
attention_input = torch.cat([queries, user_behavior, queries-user_behavior, queries*user_behavior], dim=-1)
# attention_input : batch size , seq length , (feature size * embedding size) * 4
attention_output = self.fc1(attention_input)
attention_output = self.fc2(attention_output)
# 아마 fully connected니까
# attention_input : batch size , seq length , 1로 될 것임.
# AttentionSequencePoolingLayer (forward)
attention_score = torch.transpose(attention_score, 1, 2)
# batch size * 1 * seq length
user_behavior_length = user_behavior_length.type(torch.LongTensor)
mask = torch.arange(user_behavior.size(1))[None, :] < user_behavior_length[:, None]
# torch.arange(seq length) 에 대해서 user behavior length 보다 크면 1 작으면 0으로 될 것 같음d = torch.arange(10)[None, :] < torch.arange(5).unsqueeze(1)[:,None]
d # 5, 1, 10
tensor([[[False, False, False, False, False, False, False, False, False, False]],
[[ True, False, False, False, False, False, False, False, False, False]],
[[ True, True, False, False, False, False, False, False, False, False]],
[[ True, True, True, False, False, False, False, False, False, False]],
[[ True, True, True, True, False, False, False, False, False, False]]])
그래서
output = torch.mul(attention_score, mask.type(torch.cuda.FloatTensor))
# output = (batch size * 1 * seq length) X (batch size, 1, seq length)
output = torch.matmul(output, user_behavior)
# (batch size, 1, embedding size)논문에서는 여기가 구현된 것이다.
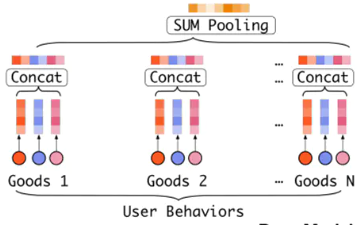
마지막에는 feature 나 query 그리고 history를 하나로 합친 다음에 network를 태운다
concat_feature = torch.cat([feature_embedded, query_feature_embedded, history.squeeze()], dim=1)
# fully-connected layers
#print(concat_feature.size())
output = self.fc_layer(concat_feature)마지막은 이 부분으 구현된 것이다.
Reference
https://github.com/shenweichen/DeepCTR-Torch
GitHub - shenweichen/DeepCTR-Torch: 【PyTorch】Easy-to-use,Modular and Extendible package of deep-learning based CTR models.
【PyTorch】Easy-to-use,Modular and Extendible package of deep-learning based CTR models. - GitHub - shenweichen/DeepCTR-Torch: 【PyTorch】Easy-to-use,Modular and Extendible package of deep-learning bas...
github.com
https://www.youtube.com/watch?v=nukWmPo8Kbk
https://arxiv.org/abs/1706.06978
Deep Interest Network for Click-Through Rate Prediction
Click-through rate prediction is an essential task in industrial applications, such as online advertising. Recently deep learning based models have been proposed, which follow a similar Embedding\&MLP paradigm. In these methods large scale sparse input fea
arxiv.org
https://velog.io/@hwanseung2/KDD-2018-Deep-Interest-Network-for-Click-Through-Rate-Prediction
[리뷰] Deep Interest Network for Click-Through Rate Prediction, KDD 2018
알리바바 추천 시스템이 이렇게?
velog.io
https://slideplayer.com/slide/16916102/
Deep Interest Network for Click-Through Rate Prediction - ppt download
Outline Introduction Method Experiment Conclusion
slideplayer.com