분석 Python/Visualization
[seaborn] clustermap, heatmap으로 시각화하기
데이터분석뉴비
2020. 8. 20. 21:07
728x90
import seaborn as sns
import sklearn
from sklearn.datasets import load_diabetes , load_wine
data_dict = load_wine()
data = pd.DataFrame(data_dict.data,columns=data_dict.feature_names)
lut = dict(zip(data_dict.target_names, "rbg"))
change = dict(zip(np.unique(data_dict.target) , data_dict.target_names))
row_colors = pd.Series(data_dict.target).map(change).map(lut)
change , lut
Correlation Clustermap
from sklearn.preprocessing import MinMaxScaler
m = MinMaxScaler(feature_range=(-1,1))
data_num_minmax = m.fit_transform(data)
data_num_minmax = pd.DataFrame(data_num_minmax ,
columns=data.columns.tolist())
sns.clustermap(data_num_minmax,
annot = False,
cmap = 'RdYlBu_r',
vmin = -1, vmax = 1,
figsize=(15,15),
metric="correlation"
)
## https://seaborn.pydata.org/examples/structured_heatmap.html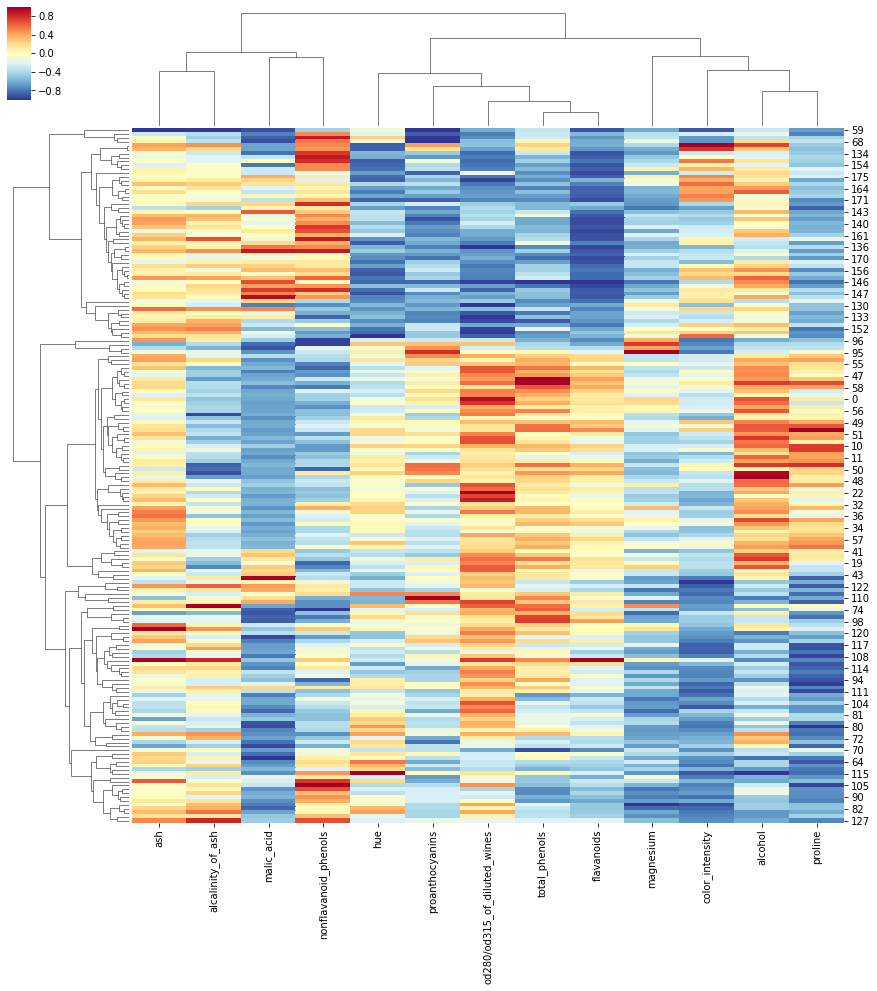
Correlation Clustermap + row_colors
sns.clustermap(data_num_minmax,
annot = False, # 실제 값 화면에 나타내기
cmap = 'RdYlBu_r', # Red, Yellow, Blue 색상으로 표시
vmin = -1, vmax = 1, #컬러차트 -1 ~ 1 범위로 표시
figsize=(15,15),
metric="correlation",
row_colors=row_colors)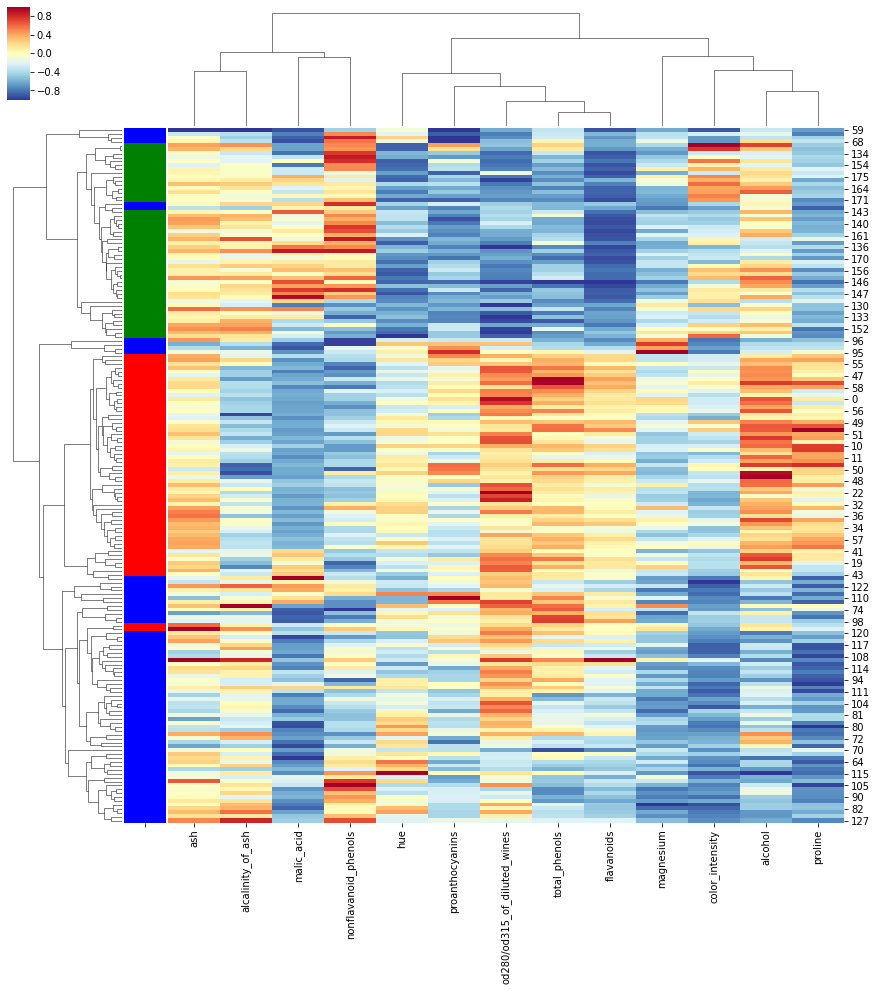
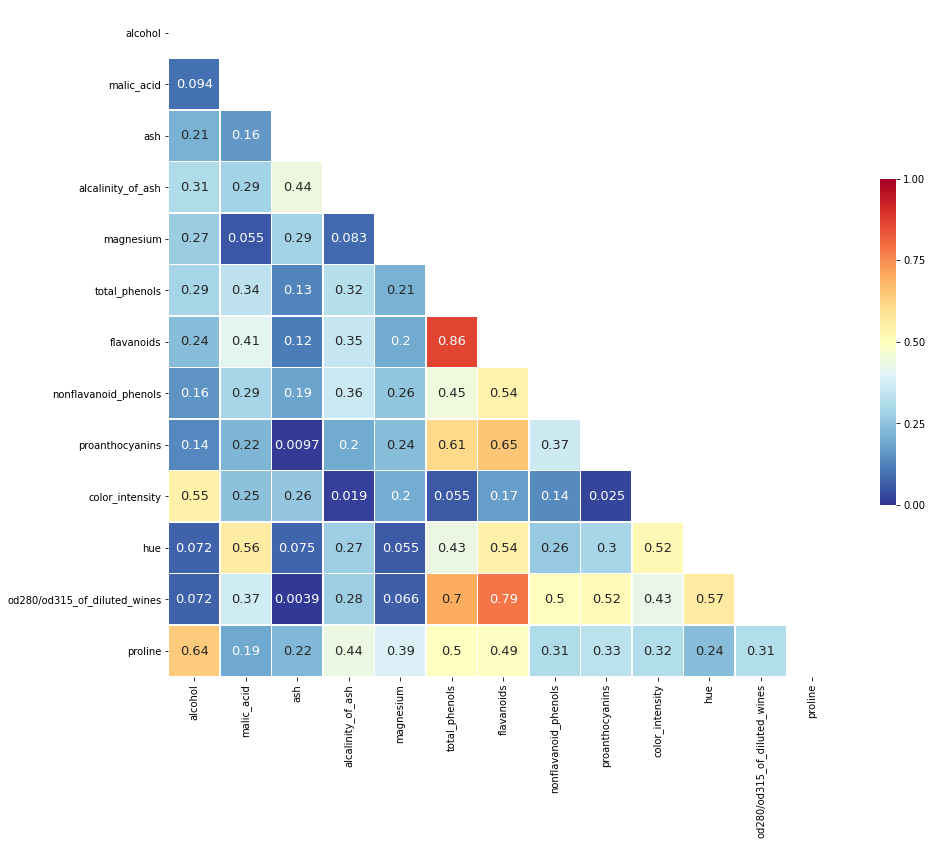
Correlation Heatmap
corr_matrix = data.corr().abs()
mask = np.zeros_like(corr_matrix, dtype=np.bool)
mask[np.triu_indices_from(mask)]= True
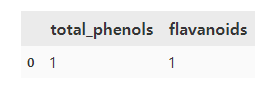
corr_matrixcorr_rel_check = (corr_matrix > 0.8).sum()-1
pd.DataFrame(corr_rel_check[corr_rel_check > 0]).T
import seaborn as sns
f, ax = plt.subplots(figsize=(15, 15))
heatmap = sns.heatmap(corr_matrix,
mask = mask,
square = True,
linewidths = .5,
cmap = 'RdYlBu_r',
cbar_kws = {'shrink': .4,
'ticks' : [0 , 0.25, 0.5, 0.75 , 1]},
vmin = 0,
vmax = 1,
annot = True,
annot_kws = {'size': 13}
)
sns.set_style({'xtick.bottom': True}, {'ytick.left': True})