OpenAI-Context Engineering 가이드(2025.09) 공부해보기
OpenAI에서 정리한 문서이고 간단하게 정리하면 다음과 같습니다
이 문서는 ‘긴 대화 속에서 AI가 필요한 것만 기억하고, 불필요한 정보는 버리거나 압축해 효율적으로 대화를 이어가도록 하기 위한 컨텍스트 관리 전략(트리밍 vs 요약)과 그 구현 방법(TrimmingSession / SummarizingSession)을 설명하는 가이드
실제 개발을 하다 보면 멀티턴 시 대화를 어떻게 처리할까에 대한 고민을 많이 하게 됩니다.
이 글에서는 OpenAI에서 만든 Context Engineering 가이드를 보고 어떻게 하는 게 좋은 지 배워보고자 합니다.
문서 전체 핵심 요약
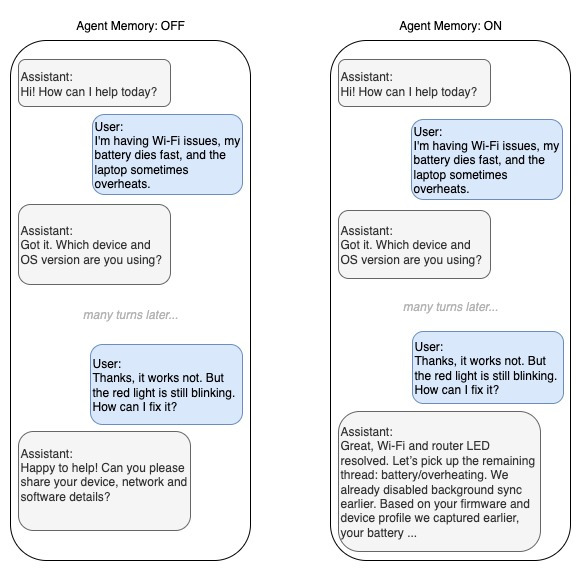
1) 왜 컨텍스트 관리가 필요한가
- LLM은 대화 전체를 계속 기억한다 → 길어질수록 비용 증가, 속도 저하, 오류 증가, 맥락 왜곡 발생.
- 토큰 수가 정해져있고 많다해도 관리를 하지 않으면 문제가 생길 수 있음
- 맥락이 너무 많으면 비효율, 산만, 오작동
- 맥락을 너무 줄이면 일관성 상실, 정보 누락
- “필요한 것만 유지하고 불필요한 것 제거”가 성능 + 비용 최적화에 필수.
- 특히 여러 문제를 한 세션에서 다룰 때 과거 정보가 계속 남아있으면 판단이 흐려질 위험이 큼.
2) 두 가지 핵심 전략
| 전략 | 핵심 아이디어 | 장점 | 단점 | 적합한 상황 |
| Context Trimming (최근 N턴 유지) | 오래된 대화들을 통째로 버리고 최근 대화 몇 개만 남김 | 단순, 빠름, 예측 가능 | 이전 문제나 사용자 상태를 잊어버릴 수 있음 | 요청이 매번 독립적 / 툴 중심 프로세스 |
| Context Summarization (과거 내용 요약 보존) | 오래된 대화는 요약해서 기억에 남김 | 장기 맥락 유지 가능, 사용자 경험 좋음 | 요약이 부정확하면 맥락 오염 위험, 추가 비용 발생 | 고객 상담, 코칭, 분석 등 장기 연속 흐름이 중요한 상황 |
3) 구현 방식
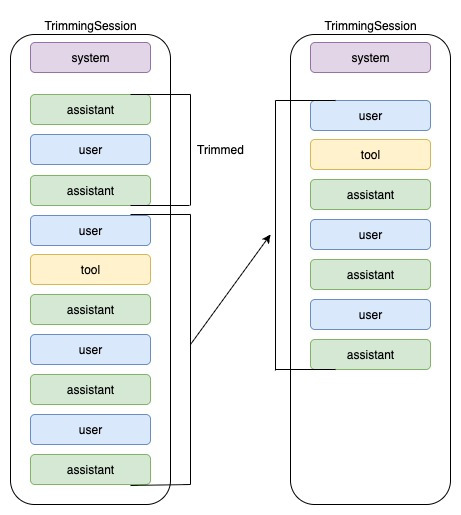
A) TrimmingSession
- 최근 N개의 “유저 턴(대화 단위)”만 저장
- 오래된 턴은 완전히 제거
- 메모리가 간결 → 빠름 + 비용 절약
- 단, 기억이 뚝 끊길 수 있음
B) SummarizingSession
- 전체 대화 중 오래된 부분은 자동으로 요약 → 요약본을 synthetic user/assistant 메시지 쌍으로 저장
- 최근 N턴은 원문 그대로 유지
- 요약을 만드는 LLM Summarizer 모델 포함
- 요약 프롬프트는 정확성, 시간순 정리, 오류 전파 방지(contradiction check) 등을 강하게 요구
4) Summarization Prompt 설계 원칙
- 사실 기반 유지, 추측 금지
- 최근 상태가 항상 최종 진실
- 수행한 행동 / 도구 호출 / 오류 코드 등은 타임라인으로 정리
- 사용자의 환경 정보는 가치가 있을 때만 보존
- 요약은 구조화된 bullet 형식 권장 (파편화 방지)
5) 평가(Eval) 방향
- 요약이 핵심 정보를 정확하게 유지하는지 정량적으로 검증 필요
- 주요 측정 포인트:
- long-range context 유지 능력
- 도구 호출 정확도 변화
- 중복 지시 / 같은 질문 반복 여부
- 요약이 잘못된 사실을 포함해 오염되지 않는지
기법
기법 1: Context Trimming (최근 N턴 유지)
개념
- “턴(turn)”을 유저 메시지 + 그 이후 어시스턴트/툴 호출/툴 결과 등의 연속단위로 정의. Scribd+1
- max_turns = N 값 설정 → 최근 N개의 유저 턴만 히스토리에 남기고 그 이전은 잘라버림.
- 코드 예시도 제공됨 (TrimmingSession 클래스). Scribd+1
장점
- 단순 구현: 별도 요약모델 호출 필요 없음 → latency 적음. cookbook.openai.com+1
- 최근 대화는 원문 그대로 유지되므로 디버깅/추적이 비교적 용이함. cookbook.openai.com
- 이전 정보가 넘쳐서 생기는 혼란(context poisoning) 가능성 일부분을 막을 수 있음. cookbook.openai.com
단점 & 리스크
- “큰 그림(big picture)” 정보(예: 초기 요구사항, 사용자 선호, 케이스 번호)가 잘려나갈 수 있음 → 이후 대화에서 잊은 것처럼 보일 위험 있음. cookbook.openai.com+1
- 최근 N턴 안에 포함된 정보라도 툴 호출 결과 데이터량이 많으면 토큰 급증으로 인해 의미 없는 상황이 발생할 수 있음. cookbook.openai.com
- 사용자 경험 측면에서 “기억해 줬으면 좋았을 것”이라는 기대가 많은 서비스라면 트리밍만으로는 부족할 수 있음.
실제 적용에서 고려사항
- N값 설정: 사용자 대화 평균 턴 수 + 중요 정보 지속기간을 참조해서 실험 필요.
- 트리밍만 적용했다가 “왜 이전에 했던 말 기억 안 해줘?” 피드백 나올 가능성 있음 → 사용자 기대치 고려 필수.
- 툴 호출 내용이 많을 경우, “최근 턴”이라도 내부에서 별도 trimming 또는 요약이 필요할 수 있음.
기법 2: Context Summarization (과거 내용을 압축 보존)

개념
- 일정 턴 수(예: context_limit)를 초과하면, 그 이전의 모든 대화를 **요약(summary)**으로 바꿔버린다.
- 최근 keep_last_n_turns는 원문 그대로 유지하고, 그 앞쪽은 synthetic 유저→어시스턴트 메시지 쌍으로 대체됨. cookbook.openai.com+1
- 요약을 위한 별도 LLM 호출을 포함함 (LLMSummarizer). Scribd
장점
- 장기간 대화에서 “초기 맥락 / 결심 / 사용자 선호 / 식별자” 같은 중요 정보를 압축해서 유지 가능함.
- 사용자 및 서비스에 대해 “지속되는 기억”을 제공할 수 있어 UX 관점에서 이점 있음.
- 토큰 사용량을 통제하면서도 긴 흐름을 놓치지 않고 담을 수 있음.
단점 & 리스크
- 요약 과정에서 정보 손실 또는 왜곡이 발생할 수 있음 → “컨텍스트 오염(context poisoning)” 위험 존재. cookbook.openai.com
- 요약을 호출하기 위한 모델 비용 + latency 증가.
- 요약 구조가 복잡하면 추적/디버깅이 어려워짐.
- 요약된 정보가 잘못되면 이후 모든 대화에 영향 미침 → 리스크가 누적됨.
실제 적용에서 고려사항
- 요약 프롬프트 설계가 중요: 구조화된 포맷, 시간 순서, 불확실한 정보는 UNVERIFIED로 표시 등. (SUMMARY_PROMPT 예시) Scribd
- 요약 주기 설정: 어떤 턴 수에서 요약을 실행할지 조건 설정 필요 (예: context_limit, keep_last_n_turns)
- 요약 후 검증/모니터링: 요약이 중요한 정보 빠뜨리지 않았는지, 왜곡 없는지 주기적으로 체크해야 함.
- 요약되고 나면, 원문 로그는 보관하면서 모델엔 요약본만 보내는 구조 고려 가능 (운영/감사 관점).
요약 프롬프트 예시
아래 프롬프트는 위에서 말한 것처럼 여러 요인을 고려하여 작성하게 된 것으로 보인다.
| 요소 | 의도 | 이유 |
| 사실만 유지 | 오염 방지 | 잘못된 summary는 장기 컨텍스트 전체를 망친다 |
| 최근 정보 기준 | 상태 일관성 유지 | troubleshooting에서는 최신 상태가 유일한 진실 |
| 섹션 구조화 | reasoning 입력 형태 표준화 | 모델이 다음 reasoning 할 때 lookup 가능 |
| 툴/실행 단계 기록 | 문제 해결 trace 유지 | tool-based workflow에서 중요 |
| 다음 단계 제안 포함 | “기억” + “계속 해결”을 위한 state transition | 단순 기록이 아니라 에이전트 행동 지속 목적 |
SUMMARY_PROMPT = """
You are a senior customer-support assistant for tech devices, setup, and software issues.
Compress the earlier conversation into a precise, reusable snapshot for future turns.
Before you write (do this silently):
- Contradiction check: compare user claims with system instructions and tool definitions/logs; note any conflicts or reversals.
- Temporal ordering: sort key events by time; the most recent update wins. If timestamps exist, keep them.
- Hallucination control: if any fact is uncertain/not stated, mark it as UNVERIFIED rather than guessing.
Write a structured, factual summary ≤ 200 words using the sections below (use the exact headings):
• Product & Environment:
- Device/model, OS/app versions, network/context if mentioned.
• Reported Issue:
- Single-sentence problem statement (latest state).
• Steps Tried & Results:
- Chronological bullets (include tool calls + outcomes, errors, codes).
• Identifiers:
- Ticket #, device serial/model, account/email (only if provided).
• Timeline Milestones:
- Key events with timestamps or relative order (e.g., 10:32 install → 10:41 error).
• Tool Performance Insights:
- What tool calls worked/failed and why (if evident).
• Current Status & Blockers:
- What’s resolved vs pending; explicit blockers preventing progress.
• Next Recommended Step:
- One concrete action (or two alternatives) aligned with policies/tools.
Rules:
- Be concise, no fluff; use short bullets, verbs first.
- Do not invent new facts; quote error strings/codes exactly when available.
- If previous info was superseded, note “Superseded:” and omit details unless critical.
"""
왜 요약을 “user → assistant 메시지 페어”로 다시 넣는가?
1) 대화 구조를 깨면 모델이 맥락을 잘못 해석함
LLM은 컨텍스트를 볼 때 역할(role: user / assistant) 을 매우 강하게 신호로 사용한다.
- 만약 요약을 단순한 assistant 메시지로만 넣으면?
→ 모델은 그것을 “이전 내가 말한 내용의 연속”으로 오해할 수 있음.
즉, 내가 한 말을 내가 다시 말한 것처럼 reasoning이 꼬일 수 있다. - 반대로 user 메시지 없이 assistant summary만 있으면?
→ 모델이 summary를 “새 사용자가 준 입력”으로 잘못 인식할 수 있음.
따라서 user → assistant 페어는
"사용자가 요약 요청 → AI가 요약 응답"
이라는 대화적 위치 관계를 명확히 유지한다.
2) 대화의 흐름(턴 구조)을 유지하기 위함
앞서 정의된 "턴(turn)" 개념 기억하지?
턴 = user 발화 이후 assistant + tools + 결과 전부
요약을 넣을 때도 새로운 “턴” 형태로 삽입해야:
- 모델 입장에서 “대화가 이어지는 중”이라고 자연스럽게 인식됨
- 이후 reasoning 시, “이건 요약된 과거” 라는 의미가 유지됨
만약 turn 패턴을 깨면:
- 모델이 다음 reasoning 단계에서 role confusion 발생
- 특히 function/tool call 추론이 흔들림
3) “요약은 새로운 진실의 앵커(anchor)”
요약은 과거 대화 전체의 정리본이므로
모델은 이후 reasoning을 할 때 이 요약을 “과거 상태(state) 스냅샷” 으로 본다.
그런데 이걸 assistant 혼자 말한 것으로 처리하면?
→ 장기 컨텍스트에서 “내부 독백 / hallucination”으로 취급될 위험이 있다.
그 반면
“user가 summarize 요청 → assistant가 그 요청에 따라 요약”
으로 표현되면:
- 모델은 요약이 합리적이고 외부적으로 유효한 판단 결과라고 더 신뢰한다.
- 즉, memory anchor 로 작동한다.
(과거 오래된 대화들) → 요약 대상
요약된 삽입 메시지:
user: "Summarize the conversation we had so far." ← shadow prompt (대화의 자연스러운 위치 유지)
assistant: "<generated structured summary>" ← state snapshot
(최근 N개의 turn은 원문 그대로 유지)⚠️ 왜 “shadow user prompt” 라는 표현을 쓰는가?
- 실제 유저가 입력한 메시지가 아님
- 하지만 대화 형식과 흐름을 유지하기 위한 “가짜 유저 역할”
→ 모델이 요약을 맥락 전이(context transition) 로 정확히 인식하게 하기 위함.
즉,
"너 지금부터 요약된 상태를 기준으로 생각해"
라고 은밀하게 컨텍스트를 재정렬하는 장치.
요약 실행 방식
| 방식 | 설명 | 장점 | 단점 |
| 매 턴 요약 | 매 유저 메시지 후 요약 실행 | 메모리 항상 깔끔 | 정보 손실 축적 (전화게임 효과), latency 증가, 비용 증가 |
| 임계점 조건 요약 (추천) | turn 수가 context_limit을 초과할 때만 요약 실행 | 비용/품질 균형, 손실 최소화 | 조건/치환 로직 필요 |
“임계점 조건 요약”의 동작 흐름 (SummarizingSession 내부 로직 그대로)
- 사용자가 계속 말을 한다 → turn 수 증가
- 아직 context_limit 이내 → 원문 히스토리 유지
- turn 수가 context_limit 초과 → 딱 그때만 요약 진행
- 요약 결과를 user→assistant synthetic pair 로 넣고
- 최근 keep_last_n_turns 는 그대로 보존
- 다시 turn count 초기화된 상태로 계속 대화 진행
- 다시 limit 넘으면 또 요약 1회 실행
→ 반복
즉, 주기적 또는 배치가 아니라 "이벤트 기반" 조건 실행이다.
왜 “배치 주기형 요약”은 비추천인가?
배치형(예: “5분마다” / “10턴마다 강제 요약”)은 그럴듯해 보이지만 문제는:
1) 요약 시점이 대화 흐름과 무관해질 수 있다.
→ 대화 중간 reasoning 상태가 허공에서 잘려나가는 현상 발생.
2) 요약 빈도가 불필요하게 증가 → 비용 증가 + 정보 왜곡 누적.
3) 어떤 턴은 짧고 어떤 턴은 길어 토큰량 기준으로 왜곡 발생.
따라서 시간 기반, 주기 기반 배치는 메모리 오염 및 UX 저하를 유발한다.
최종 리뷰
이번에 context를 관리하는 방법에 대해서 알아보았습니다.
더 많은 방법이 있지만 가장 심플하면서 효과적인 방법인 trimming과 summarizing을 알아보았고, 이것은 결국 사용자와의 대화 로그를 분석하여 어느 정도의 limit를 설정할 지 서비스 이후 대화 로그를 분석하는 추가 작업도 매우 중요해보입니다.
출처-링크
https://github.com/openai/openai-cookbook/blob/main/examples/agents_sdk/session_memory.ipynb
openai-cookbook/examples/agents_sdk/session_memory.ipynb at main · openai/openai-cookbook
Examples and guides for using the OpenAI API. Contribute to openai/openai-cookbook development by creating an account on GitHub.
github.com
https://cookbook.openai.com/examples/agents_sdk/session_memory
Context Engineering - Short-Term Memory Management with Sessions from OpenAI Agents SDK | OpenAI Cookbook
AI agents often operate in long-running, multi-turn interactions, where keeping the right balance of context is critical. If too much is...
cookbook.openai.com